Packet Forwarding and Routing over Unnumbered Interfaces
In the previous blog posts in this series, we explored whether we need addresses on point-to-point links (TL&DR: no), whether it’s better to have interface or node addresses (TL&DR: it depends), and why we got unnumbered IPv4 interfaces. Now let’s see how IP routing works over unnumbered interfaces.
The Challenge
A cursory look at an IP routing table (or at CCNA-level materials) tells you that the IP routing table contains prefixes and next hops, and that the next hops are IP addresses. How should that work over unnumbered interfaces, and what should we use for the next-hop IP address in that case?
As always, oversimplifications (like the one in the previous paragraph) can impede your understanding. The job of a forwarding table (FIB)1 in a router is to:
- Find the outgoing interface that is on the shortest path to the destination;
- Rewrite layer-2 header in the forwarded packet in a way that will make the downstream router receive it.
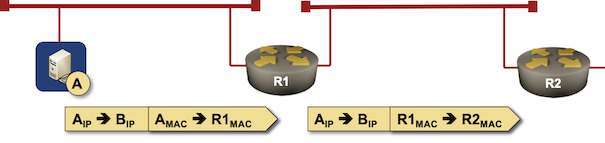
IP forwarding in a nutshell
Have you noticed that I haven’t mentioned the next-hop IP address at all? We commonly use next-hop IP addresses in routing tables as a convenient abstraction to:
- Identify the outgoing interface – match the next-hop IP address to an interface subnet, and assume that must be the outgoing interface.
- Get the destination layer-2 address we need in the outgoing layer-2 header – use ARP/ND table to map the next-hop IP address into MAC address2
However, if we manage to get the same information in some other way, there’s no need for next-hop IP addresses. For example, the outgoing layer-2 header on a point-to-point link is always the same (because it’s a point-to-point link).
Let’s walk through a few examples.
Static Route Pointing to a Point-to-Point Interface
Imagine you configure a static route pointing to a GRE tunnel (because very few people know what serial interfaces are in 2021). Do you need a next-hop IP address for that route? Of course not. The outgoing interface is clearly identified (you configured it), and there’s only one potential next-hop: the other end of the tunnel. Problem solved – point-to-point tunnels can be unnumbered interfaces.
Here’s a curveball: what happens if a static route without next-hop information points to an Ethernet interface? You REALLY SHOULD lab this, but I doubt you will, so you’ll find the answer in the comments to this blog post.
Getting Our Hands Dirty
Consider a simple 2-router network with a GRE tunnel between the routers.
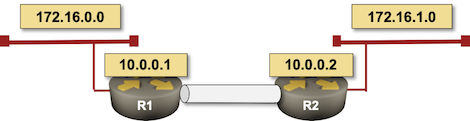
Simple 2-router lab
We’ll use static routes instead of a routing protocol and will add the following static route for the remote loopback interface3 pointing to the tunnel:
ip route 10.0.0.2 255.255.255.255 Tunnel0
The route appears in the routing table without any next-hop information, the only unusual bit of the printout is the claim that it’s a directly connected route.
r1#sh ip route 10.0.0.2
Routing entry for 10.0.0.2/32
Known via "static", distance 1, metric 0 (connected)
Routing Descriptor Blocks:
* directly connected, via Tunnel0
Route metric is 0, traffic share count is 1
Not surprisingly, R1 can ping R2’s loopback interface, but not its LAN interface (we’d need another static route for that)
r1#ping 10.0.0.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.0.0.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/2 ms
Unnumbered Interfaces and Routing Protocols
Now let’s assume you’re running OSPF across unnumbered interfaces. It’s perfectly legal, and there’s even provision in the OSPF RFC for what subnet mask one should be using on such occasions (hint: all zeroes).4
Using some magic (aka SPF algorithm), OSPF figures out it needs to use an unnumbered interface to send traffic to some destination. No problem, it installs a route pointing to that interface, and takes the neighbor IP address (as taken from OSPF hello messages) as the next hop5.
r1#sh ip route 172.16.1.0
Routing entry for 172.16.1.0/24
Known via "ospf 1", distance 110, metric 1001, type intra area
Last update from 10.0.0.2 on Tunnel0, 00:00:34 ago
Routing Descriptor Blocks:
* 10.0.0.2, from 10.0.0.2, 00:00:34 ago, via Tunnel0
Route metric is 1001, traffic share count is 1
Just in case you’re wondering how to get to the next hop (because it sure doesn’t belong to any of the connected subnets) – there’s a route in the routing table saying “to get to the next hop, go to the next hop.”
r1#sh ip route 10.0.0.2
Routing entry for 10.0.0.2/32
Known via "ospf 1", distance 110, metric 1001, type intra area
Last update from 10.0.0.2 on Tunnel0, 00:00:56 ago
Routing Descriptor Blocks:
* 10.0.0.2, from 10.0.0.2, 00:00:56 ago, via Tunnel0
Route metric is 1001, traffic share count is 1
Fortunately, we don’t really need the next hop on a point-to-point link. Everything works as expected as long as we can figure out what to put in the outgoing layer-2 header.6
Making BGP Work
You cannot run BGP over unnumbered interfaces… or at least it’s hard establishing a TCP session with an IP address that’s not in your routing table, but I know we all love MacGyver-type challenges, so here’s how you solve this conundrum:
- Figure out what the remote system wants to use as the source IP address of the BGP session (let’s assume it’s their loopback IP address)
- Create a static host route for that IP address pointing to the unnumbered interface.
- Establish a multihop EBGP session with that remote IP address.
Is anyone using such a nasty hack in real life? Sure – that’s how you establish a BGP session with Azure over a VPN connection.
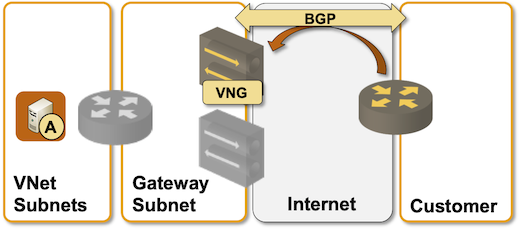
EBGP routing with Azure Virtual Network Gateway over an unnumbered IPsec tunnel
Want to See BGP Work? Here It Is…
I started with the initial configuration of our two-router network (static routes for remote loopback interfaces pointing to GRE tunnel) and configured BGP:
router bgp 65000
bgp log-neighbor-changes
network 172.16.0.0 mask 255.255.255.0
neighbor 10.0.0.2 remote-as 65001
neighbor 10.0.0.2 ebgp-multihop 255
neighbor 10.0.0.2 update-source Loopback0
Here’s the BGP table I was able to observe after a few seconds:
BGP table version is 5, local router ID is 10.0.0.1
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 0.0.0.0 0 32768 i
*> 172.16.1.0/24 10.0.0.2 0 0 65001 i
And here’s the entry for remote LAN in the local IP routing table:
Routing entry for 172.16.1.0/24
Known via "bgp 65000", distance 20, metric 0
Tag 65001, type external
Last update from 10.0.0.2 00:03:21 ago
Routing Descriptor Blocks:
* 10.0.0.2, from 10.0.0.2, 00:03:21 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 65001
MPLS label: none
As you can see, BGP needs next hops to be happy, and the next hop is recursively resolved using the static route we configured.
What About IPv6?
You might think that we don’t have the same challenges in IPv6. After all, IPv6 always assigns a link-local address (LLA) to an interface, and we can use the LLA of the downstream router as the next hop, right?
That trick helps you build the outgoing layer-2 header – there’s a well-defined way to take the downstream IPv6 LLA, do a Neighbor Discovery (ND) cache lookup, and get layer-2 information – but it doesn’t help you identify the outgoing interface. After all, link-local addresses use the same prefix on all interfaces. You still need routes pointing to interfaces, not just IPv6 next-hops.
Next: Unnumbered Ethernet Interfaces Continue
Want to Know More?
- The configurations I used to generate the printouts are on GitHub.
- I discussed numerous aspects of network addressing in How Networks Really Work webinar.
Revision History
- 2024-08-13
- Added a note explaining that network devices usually use regular IP addresses, not the 127.0.0.0/8 subnet, on the loopback interfaces.
-
The table used for data-plane packet forwarding should be called the forwarding table, not the routing table (although some systems might use the same data structure for both). ↩︎
-
Or whatever the underlying address of the outgoing interface is – it could be another IP address when doing tunneling. ↩︎
-
Please note that loopback interfaces on network devices usually use regular IP addresses, not the 127.0.0.0/8 subnet (more details). ↩︎
-
Trying to implement this concept, you’ll also encounter an interesting Socket API challenge: at some point in time, you’ll have to send unicast OSPF packets to an IP address that’s not (yet) in your routing table. The details are left as an exercise for the reader. ↩︎
-
This behavior might be implementation-specific. After all, there’s nothing in the OSPF topology database that would help the router figure out what to use as the next hop. ↩︎
-
Unnumbered Ethernet interfaces are a bit of a challenge. We’ll get there in another blog post. ↩︎
another gem Ivan - thanks.
I just wanted to add a bit of my personal experience on the OSPFoGRE subject:
On a certain OS version of a popular router platform (I believe it's fixed on newer OS versions now but ...still... it's representative of what can happen on any platform), the following happens:
If the 'encaps' dst IP address of the GRE tunnel is known in BGP then you need to override that with a static route in order for any OSPF packet to enter the tunnel. You don't need the static route if the OSPF packets are fragmented.
The reason for this exotic working recipe should be (as we never really got a final answer) that:
The OSPF packets are generated by the OSPF process on the central CPU and it cannot do a BGP lookup since it's a recursive one
if you induce fragmentation then it all works .... as I guess an OSPF packet that is too big can access an area of the processing or of a chipset that is provided with the ability to do recursive lookups as well as fragmentation.
Cheers/Ciao
Andrea
@Andrea: I would suspect the decision to ignore BGP routes when originating OSPF packets probably comes from someone's attempts to detect and alleviate recursive routing loops (tunnel endpoint being available over the tunnel scenarios). Fragments follow the regular packet forwarding structures.
Obviously it would help if the behavior was documented/explained.
Hello Ivan,
Sorry, yeah, of course - I'll share a bit more details:
The layout was the following:
CE ------------------- PE ------------------------P
<-----Connected-----><----OSPF + iBGP----->
<-----------------OSPFoGRE-------------------->
There's a whole network between PE and P. The router with the issue was router P. The CE's end of the GRE tunnel was redistributed as connected into iBGP and thus received this way by router P.
The issue was in version X and was fixed from version Y > X
Cheers/Ciao
Andrea