Topology- and Congestion-Driven Load Balancing
When preparing an answer to an interesting idea left as a comment to my unequal-cost load balancing blog post, I realized I never described the difference between topology-based and congestion-driven load balancing.
To keep things simple, let’s start with an easy leaf-and-spine fabric:
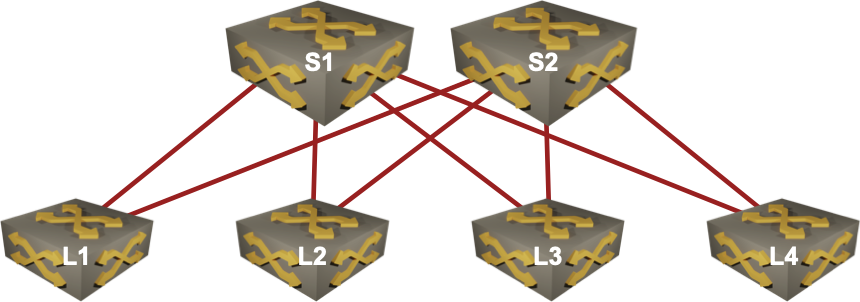
Topology-Based Load Balancing
Looking at the network diagram, it’s easy to realize there are two paths from L1 to L2, and modern routing protocols have absolutely no problem identifying the two paths and entering them in the forwarding table.
Now imagine the link S1-L2 is slower than the link S2-L2. A routing protocol capable of unequal-cost multipathing (EIGRP or properly designed BGP) would be able to identify the opportunity to use both paths in unequal ratio.
In both cases, the decision to use multiple paths (and the traffic ratio) was made based on network topology.
Going back to the first scenario: L1 has two equal-cost paths to L2, and can balance outgoing traffic across both of them. The usual implementation would use ECMP hash buckets (high-level overview, more details). Assuming the forwarding hardware supports 128 hash buckets per next-hop group, 64 of those would point to L1-S1 and the other 64 would point to L1-S2.
Congestion-Based Load Balancing
Let’s add some heavy hitters to the mix: a few backup jobs are started and for whatever crazy reason the all land on L1-S1 link. That link becomes congested, and when another session gets assigned to that link, it will experience lower throughput and higher latency. Wouldn’t it be possible to avoid the congested link even though it has equal cost as the uncongested one? Welcome to the dynamic world of congestion-driven load balancing (or whatever it’s properly called).
Modern forwarding hardware supports dynamic reassignment of output interfaces to hash buckets in a next-hop group. With per-bucket traffic counters and proper software support, L1 could rearrange the hash buckets so that the traffic across both uplinks becomes more balanced (fewer hash buckets pointing to S1 than to S2). In a best-case scenario the reshuffling could be done without reordering in-transit packets (hint: move a bucket when it’s empty – see also flowlets).
Mission Impossible
Now for a really interesting scenario: imagine someone runs a bunch of backup jobs between L3 and L2, and they all land on S1-L2 link. The path L1-S1-L2 becomes congested (on the S1-L2 leg). Could L1 do anything about that? Most often, the answer is no and the only exception I’m aware of is Cisco ACI (at least they claim so – see also CONGA paper / HT: Minh Ha). Juniper claims they do something similar in Virtual Chassis Fabric (HT: Alexander Grigorenko)
To change the forwarding behavior on L1 based on downstream congestion, there would have to be a mechanism telling L1 to reduce its utilization of one of the end-to-end paths. While that could be done with a routing protocol, no major vendor ever implemented anything along those lines for a good reason – the positive feedback loop introduced by load-aware routing and resulting oscillations would be fun to troubleshoot.
Ignoring the early IGRP implementations from early 1980s, I heard of one implementation of QoS-aware routing protocol, and I’ve never seen it used in real life. Please also note that SD-WAN uses a different mechanism to get the job done: it’s not using a routing protocol but end-to-end path measurement. That approach works because SD-WAN solutions ignore the complexities of the transport network; they assume the transport network is a single-hop cloud full of magic beans.
Could We Fix It?
Ignoring the crazy ideas of SDN controller dynamically reprogramming edge switches, the best way to solve the problem is (yet again) an end-host implementation:
- Connect hosts to the network with multiple IP interfaces, not MLAG kludges.
- Use MP-TCP or similar to establish parallel TCP sessions across multiple paths using different pairs of source-destination IP addresses.
- When multiple TCP sessions between a pair of hosts land on the same path due to load balancing hashing algorithms, use an irrelevant field in the packet header (TTL, flow label…) to change the hash values – see FlowBender paper for details.
Release Notes
- 2021-03-13
- Link to Juniper VCF documentation
- Information on Broadcom supporting Dynamic Load Balancing
- Link to CONGA research paper
>>the only exception I’m aware of is Cisco ACI (at least they claim so) Juniper VCF also supports that (at least they claim so): https://www.juniper.net/documentation/en_US/junos/topics/concept/virtual-chassis-fabric-traffic-flow-understanding.html
Nokia has such an dynamic SDN solution, but I have not heard too much how successful it is in real life...
https://www.nokia.com/blog/path-computation-ip-network-optimization/
@Bela: That seems to be something similar to Juniper's NorthStar (and Cariden MATE).
There's no reason it wouldn't work well, but we both know centralized traffic management as done with PCE controllers works well only if you strictly enforce ingress traffic flows (so you never get into congestion-driven load balancing).
Left my comments on Li (under this post), copy, if of value
Most data center switches these days support sFlow. Enabling sFlow telemetry across the fabric provides centralized real-time visibility into large flows that can be used to detect link congestion, identify the flow(s) causing the congestion, and the paths they take across the fabric.
Creating a stable feedback loop (avoiding oscillations) to load balance the flows is challenging! A proof of concept using segment routing was shown at ONS/ONF 2015.
https://www.youtube.com/watch?v=CBcPLm-ujPI
I don't know of any production controllers using this approach, but even without a controller, the visibility provides useful insight into fabric performance.
Ivan, a few thoughts after reading your post and the comments:
Dynamic LB, is something available in Broadcom ASIC, so switches that make use of them like those of Arista for ex, have that feature. Juniper Adaptive LB, from Alex's link above, which was first made available with the Trio chipset AFAIK, works on the same principle. Basically in DLB and ALB, the sender monitors the ECMP bunble and dynamically adjust the loads to provide better balancing of traffic across member links. The sender has no visibility into what's going on at the downstream neighbors' status, it makes traffic reshuffling decision based on its own local info of the loads on individual ECMP links.
At first glance, that seems to be what ACI is doing too:
https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/1-x/aci-fundamentals/b_ACI-Fundamentals/b_ACI-Fundamentals_chapter_010010.html#concept_F280C079790A451ABA76BC5C6427D746
But in fact, ACI takes this concept one step further. Cisco was able to come up with a new scheme that enables the sender to see into the traffic condition at the downstream neighbors and adjust its sending rate accordingly. So yes, when the path L1-S1-L2 becomes congested (on the S1-L2 leg), L1 will get enough feedback from S1-L2 status to reduce its traffic rate. They dub this technology CONGA, or Congestion Aware LB, as confirmed by Cisco people here:
https://community.cisco.com/t5/jive-developer-archive/nso-aci-scope/td-p/3572137
CONGA acknowledges that SDN/centralized approaches are simply too slow to deal with low-latency DC environment, so distributed methods are needed. It also realizes that schemes like MPTCP, albeit providing some improvement, are essentially still reactive to congestion, and so, to provide better LB beyond what MPTCP can offer, a proactive scheme will have to be used. That's why it goes in that direction, which, coincidentally, is the same reasoning that underpins the concept of DC-TCP.
Wrt to MPTCP, the flowbender paper also points out the very same weaknesses, i.e. it makes Incast worse (by causing starvation/Oucast problem) and it does nothing for short flows (due to its overhead),which can account for a big majority of flows in DC environment as well, and finally it may require a lot of sub-flows to work its magic.
CONGA basically uses flowlet switching to deflect traffic on sensing congestion. Flowlet is alright, it's one step beyond ECMP when it comes to sophistication and effectiveness, but it's undoubtedly complex, as it involves figuring out the optimum inter-burst time, which has to be larger than the max latency among the ECMP paths, to avoid reordering. In practice, for ACI, this is set to a specific value, which, if too low (100us) can lead to lots of reordering, or if too high (500us) can lead to increased RTT.
I personally feel the best way to go, utilization-wise, is to move beyond flowlet, to combine a proactive scheme like Conga or DCTCP or both (DCTCP doesn't require special hardware like CONGA) with packet-spraying ECMP, essentially amounting to how a high-end router operates internally within its crossbar or multi-stage fabric.
The reason a router fabric can deal with reordering of cell is twofold. First, with internal speedup and close to zero (or zero) buffer crossbar, re-ordering is totally eliminated. Second, in case of multi-stage crossbar inside high-density routers like CRS, where the middle stage has buffer and re-ordering is inevitable, a small re-ordering buffer can be placed at the destination/egress port, for SAR purpose.
A 2nd method of dealing with reordering in Multi-stage xbar router, as utilized by CRS, is to force switch-flow order by eliminating cell spray, effectively turning the inside of a CRS into a network of virtual circuits. With DCs having lots of bandwith these days, there are talks of bringing back to TDMA VC back into the DC to deal with latency as well. Everything old will be new again :)).
DC networks usually are bandwidth-plenty (speedup condition), with low RTT making a bit of reordering tolerable to most apps. Add to that shallow-buffer switches, and we have all conditions necessary for packet spraying to be viable. That way you don't need multiple IPs for a host either. The reordering stage can be implemented on a SmartNIC, or by modifying the logic of GRO inside the hypervisor itself.
This is the link to CONGA, if you want to take a deeper look:
https://people.csail.mit.edu/alizadeh/papers/conga-sigcomm14.pdf
Re UCMP and QoS-aware routing, I think the latter is totally unneeded given better solutions can be readily made available. QoS routing is just a solution looking for problem IMO. Some people probably push that in order to create a competitive advantage in their products, and I don't think it works or will work for that matter. Networking products these days are essentially a race to the bottom, a sign of a very mature, saturating industry.
Not to mention, I don't know how one can propose a scalable scheme of QoS routing for Link State Protocol that involves constant recalculation of SPT. For networks with thousands of nodes or higher in a leaf-spine or fat-tree fabric, it will be very expensive, in terms of computation and flooding. For protocols like EIGRP, as long as a route satisfies the feasibility condition so no loop is possible, it can be used as an UCMP alternate. Calculation is distributed among the nodes, so it's relatively painless. That's why traditionally in hub and spoke environments -- which is what leaf-spine and fat-tree amount to -- distance vector protocols are recommended over LSP.
For me, the use of BGP in DC fabric is an implicit acknowledgement of the preference for DV routing protocols in that kind of topology. The choice of BGP is unfortunate however, as from the very beginning, BGP was designed as a reachability-exchanging protocol, not a pathfinder, so it's not optimized for finding paths, and so is slower to converge. If one tries so hard by tweaking it left, right and center, to improve its convergence status, can we call it BGP anymore? And why not give that effort to improve an IGP, which was from the very beginning, made and optimized with that intention in mind?
EIRGP was looked down upon because it's from Cisco, and it doesn't have traffic engineering feature. But that's not an intrinsic problem of the protocol. ERO can be implemented distributedly with EIGRP, and it would be more scalable than calculating it from a single HER. Since OpenEIGRP is available for experimentation, if people really want, they can try tweaking it. But even without all those trappings, EIGRP as-is is perfectly viable for people who want to build a fabric out of Cisco gadgets.
@JeffT: Sorry Jeff - wanted to read your comments but can't find them.
cheers/ciao
Andrea