Impact of Centralized Control Plane Partitioning
A long-time reader sent me a series of questions about the impact of WAN partitioning in case of an SDN-based network spanning multiple locations after watching the Architectures part of Data Center Fabrics webinar. He therefore focused on the specific case of centralized control plane (read: an equivalent of a stackable switch) with distributed controller cluster (read: switch stack spread across multiple locations).
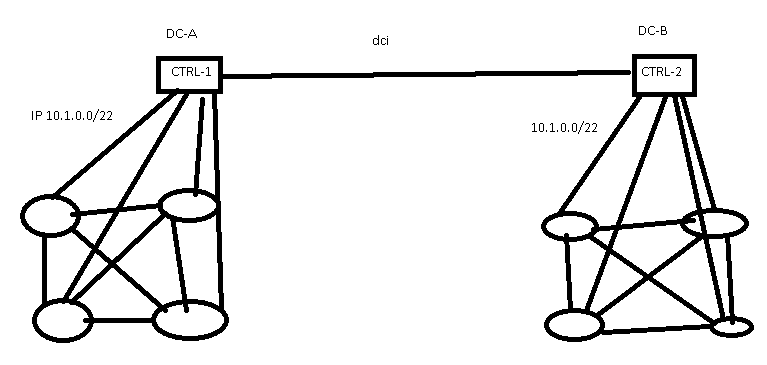
SDN controllers spread across multiple data centers
He started with…
You said that the Centralized control has one IP address per subnet and if the two DC’s lose connectivity, it will result in one DC completely unreachable. Is it because the Controller only exists in one DC?
That’s how most stackable switch solutions work, see for example HP IRF (mentioned here because they were one of the few vendors “brave” enough to advertise Cross-DC Switch Stack stupidity).
The location of the controller cluster and its operations (active/active or active/standby) are architectural decisions, and different architectures went different ways. For example, VMware NSX-V has controllers spread across multiple locations, while VMware NSX-T requires all controllers to be in one location.
The behavior under network partitioning (this is what DCI link failure really is) also depends on controller architecture (does it implement control plane or only management plane) and quality of its implementation. Shutting down the minority part of the partitioned network is the most brutal approach to solving this problem. There are better solutions – here are some of the typical behaviors observed in the wild:
- Complete shutdown of minority part of the network (most stackable switches);
- Complete shutdown of control plane with data plane operating as long as there are no topology changes or control-plane requests that cannot be handled locally. NSX-T uses this approach, and Big Switch made it a bit better by offloading LACP and ARP to the edge switches.
- Minority part of the network reverting to non-controller mode. This is NSX-V approach – minority site uses fabric-wide flood-and-learn.
- Minority part of the network becoming read-only. This is Cisco ACI approach, and works well only when the controllers remain a management-plane component. The moment you introduce control plane to the controller you’re almost forced to go back to one of the previous approaches.
- Minority part of the network losing write access to shared objects. This is how Cisco ACI Multi-Site controller and NSX-T federation work. They both deploy a full-blown controller cluster on each site, and use an umbrella system to synchronize configurable objects across sites. Each location remains fully operational and manageable, and you can even create local objects when undergoing network partition. I expect Microsoft Azure orchestration system to work in a similar way.
- No impact when each location becomes an independent management-plane entity. This is how AWS regions are implemented.
Summary
When choosing a multi-site controller solution always ask yourself “what happens when the inter-site link fails?” and “am I OK with that behavior?”
You won’t find the answer to the first question in vendor whitepapers for obvious reasons. You’ll have to dig deep into the product documentation; or you could find the answer for the most common data center controller products in VMware NSX, Cisco ACI or Standard-Based EVPN webinar.
More to Explore
A quick search for controller failure on my blog resulted in these blog posts:
- Impact of Controller Failures in Software-Defined Networks
- Controller Cluster Is a Single Failure Domain
- How Hard Is It to Think about Failures?
- On SDN Controllers, Interconnectedness and Failure Domains
- OpenFlow Fabric Controllers Are Light-years Away from Wireless Ones
You will also find the impacts of controller failures discussed in Distributed Systems Resources and in these webinars:
Hi Ivan, this sentence is not always correct: ....while VMware NSX-T requires all controllers to be in one location.
NSX-T manager appliances running the controller supports also a distributed design option over three locations (typically with three subnets) without or with (preference ) front LB (for management purpose) to avoid in case of a location failure the lost of the majority. For sure all needs to be within supported RTT.
Maybe you consider this in your blog too Oliver
Maybe
@Oliver: Rechecked NSX-T 3.1 Multisite documentation and it's in perfect agreement with what I wrote.
If you have a VMware document stating that (A) NSX-T cluster (not NSX-T Federation) can be deployed across three locations and that (B) VMware supports that design, I'd appreciate a pointer. Thank you!
Hi Ivan, Vendor public documentation do never show all design options. But I will send you offline a link to a NSX-T multi location (multi site and federation) document. This is a nice Vmware doc about the relevant NSX-T multi location solutions and the starting point for any person working with NSX. Cheers Oliver
Hi Oliver,
Having to deal with numerous networking vendors in the past, I got the impression that most of them love to over-promise and under-deliver. If a vendor decides not to publish a design document that in itself might indicate the potential quality of that design, and I would never advise anyone to use it. See also https://www.ipspace.net/Manual:Vendors
Cheers, Ivan
Hi Ivan, is an official blog or community space from Vmware not a public space? Yes it is in my eyes. Maybe you see it different... To keep everything well documented in the public doc manual area is for every vendor a big challenge. Software cycles are too frequent...
Ivan, as I was not able to find an easy way (ok, searched only a few minutes) to drop you and email offline, so here is the link.
https://communities.vmware.com/t5/VMware-NSX-Documents/NSX-T-3-1-Multi-Location-Design-Guide-Federation-Multisite/ta-p/2810327
It is not only in the networking/IT area, where vendors cannot always match from the technical perspectives what marketing promise. This is a given fact since decades....so i am not worrying too much about it. Have a look to this document and let me know your view. There are a lot of important facts about NSX multi locations solutions. Cheers Oliver
Dear Oliver, please make up your mind. First it is "vendor public documentation do never show all design options, will send you the link" then it is "is an official blog or community space from VMware not a public space". Whatever.
Anyway, thanks for the link.