Blog Posts in December 2020
Learning Networking Fundamentals at University?
One of my readers sent me this interesting question:
It begs the question in how far graduated students with a degree in computer science or applied IT infrastructure courses (on university or college level or equivalent) are actually aware of networking fundamentals. I work for a vendor independent networking firm and a lot of my new colleagues are college graduates. Positively, they are very well versed in automation, scripting and other programming skills, but I never asked them what actually happens when a packet traverses a network. I wonder what the result would be…
I can tell you what the result would be in my days: blank stares and confusion. I “enjoyed” a half-year course in computer networking that focused exclusively on history of networking and academic view of layering, and whatever I know about networking I learned after finishing my studies.
We're Done for This Year
As always, it’s time to shut down our virtual office and disappear until early January… unless of course you have an urgent support problem. Any paperwork ideas your purchasing department might have will have to wait until 2021.
I hope you’ll be able to disconnect from the crazy pace of networking world, forget all the unicorns and rainbows (and broccoli forest of despair), and focus on your loved ones – they need you more than the dusty router sitting in a remote office. We would also like to wish you all the best in 2021!
What Exactly Happens after a Link Failure?
Imagine the following network running OSPF as the routing protocol. PE1–P1–PE2 is the primary path and PE1–P2–PE2 is the backup path. What happens on PE1 when the PE1–P1 link fails? What happens on PE2?
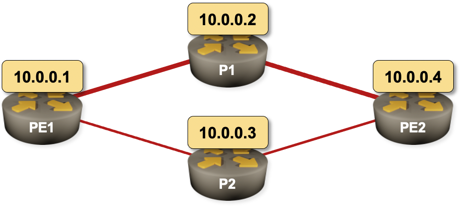
Sample 4-router network with a primary and a backup path
The second question is much easier to answer, and the answer is totally unambiguous as it only involves OSPF:
Feedback: AWS Networking
Deciding to create AWS Networking and Azure Networking webinars wasn’t easy – after all, there’s so much content out there covering all aspects of public cloud services, and a plethora of certification trainings (including free training from AWS).
Having that in mind, it’s so nice to hear from people who found our AWS webinar useful ;)
Even though we are working with these technologies and have the certifications, there are always nuggets of information in these webinars that make it totally worthwhile. A good example in this series was the ingress routing feature updates in AWS.
It can be hard to filter through the noise from cloud providers to get to the new features that actually make a difference to what we are doing. This series does exactly that for me. Brilliant as always.
Other engineers use our webinars to prepare for AWS certifications – read this blog post by Jedadiah Casey for more details.
AWS Networking and Azure Networking webinars are available with Standard ipSpace.net Subscription. For even deeper dive into cloud networking check out our Networking in Public Cloud Deployments online course.
How Ansible Configuration Parsing Made Me Pull My Hair Out
Yesterday I wrote a frustrated tweet after wasting an hour trying to figure out why a combination of OSPF and IS-IS routing worked on Cisco IOS but not on Nexus OS. Having to wait for a minute (after Vagrant told me SSH on Nexus 9300v was ready) for NX-OS to “boot” its Ethernet module did’t improve my mood either, and the inconsistencies in NX-OS interface naming (Ethernet1/1 is uppercase while loopback0 and mgmt0 are lowercase) were just the cherry on top of the pile of ****. Anyway, here’s what I wrote:
Can’t tell you how much I hate Ansible’s lame attempts to do idempotent device configuration changes. Wasted an hour trying to figure out what’s wrong with my Nexus OS config… only to find out that “interface X” cannot appear twice in the configuration you want to push.
Not unexpectedly, I got a few (polite and diplomatic) replies from engineers who felt addressed by that tweet, and less enthusiastic response from the product manager (no surprise there), so it’s only fair to document exactly what made me so angry.
Update 2020-12-23: In the meantime, Ganesh Nalawade already implemented a fix that solves my problem. Thanks you, awesome job!
Streaming Telemetry with Avi Freedman on Software Gone Wild
Remember my rant how “fail fast, fail often sounds great in a VC pitch deck, and sucks when you have to deal with its results”? Streaming telemetry is no exception to this rule, and Avi Freedman (CEO of Kentik) has been on the receiving end of this gizmo long enough to have to deal with several generations of experiments… and formed a few strong opinions.
Unfortunately Avi is still a bit more diplomatic than Artur Bergman – another CEO I love for his blunt statements – but based on his NFD16 presentation I expected a lively debate, and I was definitely not disappointed.
… updated on Tuesday, February 15, 2022 14:10 UTC
Build Your Virtual Lab Faster with netlab
This blog post describes the reasons I started working on netlab. We got incredibly far in the meantime; check netlab documentation for more details.
I love my new Vagrant+Libvirt virtual lab environment – it creates virtual machines in parallel and builds labs much faster than my previous VirtualBox-based setup. Eight CPU cores and 32 GB of RAM in my Intel NUC don’t hurt either.
However, it’s still ridiculously boring to set up a new lab. Vagrantfiles describing the private networks I need for routing protocol focused network simulations are a mess to write, and it takes way too long to log into all the devices, configure common parameters, enable interfaces…
Making LLDP Work with Linux Bridge
Last week I described how I configured PVLAN on a Linux bridge. After checking the desired partial connectivity with ios_ping I wanted to verify it with LLDP neighbors. Ansible ios_facts module collects LLDP neighbor information, and it should be really easy using those facts to check whether port isolation works as expected.
---
- name: Display LLDP neighbors on selected interface
hosts: all
gather_facts: true
vars:
target_interface: GigabitEthernet0/1
tasks:
- name: Display neighbors gathered with ios_facts
debug:
var: ansible_net_neighbors[target_interface]
Alas, none of the routers saw any neighbors on the target interface.
Repost: Drawbacks and Pitfalls of Cut-Through Switching
Minh Ha left a great comment describing additional pitfalls of cut-through switching on my Chasing CRC Errors blog post. Here it is (lightly edited).
Ivan, I don’t know about you, but I think cut-through and deep buffer are nothing but scams, and it’s subtle problems like this [fabric-wide crc errors] that open one’s eyes to the difference between reality and academy. Cut-through switching might improve nominal device latency a little bit compared to store-and-forward (SAF), but when one puts it into the bigger end-to-end context, it’s mostly useless.
Reviving Old Content, Part 2
Continuing my archeological explorations, I found a dusty bag of old QoS content:
- Queuing Principles
- QoS Policing
- Traffic Shaping
- Impact of Transmit Ring Size (tx-ring-limit)
- FIFO Queuing
- Fair Queuing in Cisco IOS
I kept digging and turned out a few MPLS, BGP, and ADSL nuggets worth saving:
Implement Private VLAN Functionality with Linux Bridge and Libvirt
I wanted to test routing protocol behavior (IS-IS in particular) on partially meshed multi-access layer-2 networks like private VLANs or Carrier Ethernet E-Tree service. I recently spent plenty of time creating a Vagrant/libvirt lab environment on my Intel NUC running Ubuntu 20.04, and I wanted to use that environment in my tests.
Challenge-of-the-day: How do you implement private VLAN functionality with Vagrant using libvirt plugin?
There might be interesting KVM/libvirt options I’ve missed, but so far I figured two ways of connecting Vagrant-controlled virtual machines in libvirt environment:
Lessons Learned: Automating Site Deployments
Some networking engineers renew their ipSpace.net subscription every year, and when they drop off the radar, I try to get in touch with them to understand whether they moved out of networking or whether we did a bad job.
One of them replied that he retired after building a fully automated site deployment solution (first lesson learned: you’re never too old to start automating your network), and graciously shared numerous lessons learned while building that solution.
Updated: Getting Network Device Operational Data with Ansible
Recording the same content for the third time because software developers decided to write code before figuring out what needs to be done is disgusting… so it took me a long long while before I collected enough willpower to rewrite and retest all the examples and re-record the Getting Operational Data section of Ansible for Networking Engineers webinar.
The new videos explain how to consume data generated by show commands in JSON or XML format, and how to parse the traditional text-based show printouts. I dropped mentions of (semi)failed experiments like Ansible parse_cli and focused on things that work well: TextFSM, in particular with ntc-templates library, pyATS/Genie, and TTP. On the positive side, I liked the slick new cli_parse module… let’s hope it will stay that way for at least a few years.
On a totally unrelated topic, I realized (again) that fail fast, fail often sounds great in a VC pitch deck, and sucks when you have to deal with its results.
Interesting: Differential Availability
Someone pointed me to a high-level overview of Google’s Spanner database which included this gem:
A second refinement is that there are many other sources of outages, some of which take out the users in addition to Spanner (“fate sharing”). We actually care about the differential availability, in which the user is up (and making a request) to notice that Spanner is down. This number is strictly higher (more available) than Spanner’s actual availability — that is, you have to hear the tree fall to count it as a problem.
In other words, it doesn’t matter if your distributed database fails if its user are also gone. Keep this concept in mind every time you’re designing a high availability solution – some corner cases are simply not worth solving.
Video: Should You Build or Buy a Solution?
After figuring out what business problem you’re trying to solve and what the users expect to get from you it’s time for the next crucial question: should you buy a shrink-wrapped product/solution or build your own? I addressed that question in the third part of Focus on Business Challenges First presentation.
Not surprisingly, the same dilemma applies to network automation solutions, and is often the source of endless time-wasting discussions that I really should have stopped engaging in, but sometimes duty calls ;)
Fast Failover: Techniques and Technologies
Continuing our Fast Failover saga, let’s focus on techniques and technologies available to implement it (assuming you still think it’s worth the effort).
There are numerous technologies you can use to implement fast reroute, from the most complex to the easiest one:
Chasing CRC Errors in a Data Center Fabric
One of my readers encountered an interesting problem when upgrading a data center fabric to 100 Gbps leaf-to-spine links:
- They installed new fiber cables and SFPs;
- Everything looked great… until someone started complaining about application performance problems.
- Nothing else has changed, so the culprit must have been the network upgrade.
- A closer look at monitoring data revealed CRC errors on every leaf switch. Obviously something was badly wrong with the whole batch of SFPs.
Fortunately, my reader took a closer look at the data before they requested a wholesale replacement… and spotted an interesting pattern:
Fifty Shades of High Availability
A while ago we had an interesting exchange of ideas around inserting high-availability network appliance into a public cloud environment (TL&DR: it was really hard until AWS introduced Gateway Load Balancing), and someone quickly pointed out we’re solving the wrong challenge because…
Azure Firewall […] is a fully stateful firewall-as-a-service with built-in high-availability.
Somehow he wasn’t too happy when I pointed out that there’s more to high availability than vendor marketing ;)