Fast Failover: Topologies
In the blog post introducing fast failover challenge I mentioned several typical topologies used in fast failover designs. It’s time to explore them.
The Basics
Fast failover is (by definition) adjustment to a change in network topology that happens before a routing protocol wakes up and deals with the change. It can therefore use only locally available information, and cannot involve changes in upstream devices. The node adjacent to the failed link has to deal with the failure on its own without involving anyone else.
Parallel Links
The simplest design that can be used for fast failover is a set of parallel equal-speed links between a pair of nodes. When one of the links fails, the forwarding tables are adjusted, and the traffic continues to flow.

Parallel links between adjacent nodes
You could run independent routing adjacencies over the parallel links, or bundle them in a Link Aggregation Group. Link Aggregation Group makes more sense when you’re using a link-state routing protocol.
The failover process could happen in hardware or software (more about that in an upcoming blog post and in Advanced Routing Protocol Topics part of Networks Really Work webinar).
Equal-Cost Paths
Parallel links offer link failure protection, but not node failure protection. To get there you need two downstream nodes and a link to each of them.
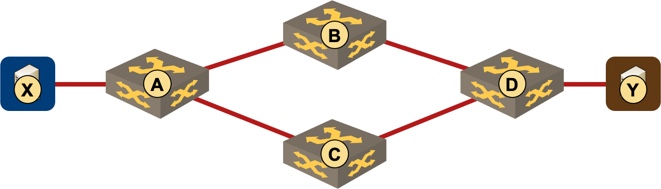
Equal-cost paths toward a destination
In a routed network you SHOULD run independent routing adjacencies over links connected to different nodes. Multi-chassis link aggregation (MLAG), and having routing adjacencies over MLAG, are monstrosities best forgotten. It’s late 2020 – you should use IP routing in your network core, and VXLAN to provide layer-2 services to VLAN huggers.
Loop-Free Alternates
In more complex network topologies a node might not have equal-cost paths to a destination that could be used for fast failover, but has an adjacent node that is using an independent path to get to that destination – a Loop-Free Alternate.
For example, in the following network A can use C to provide a loop-free alternate to get to Y.
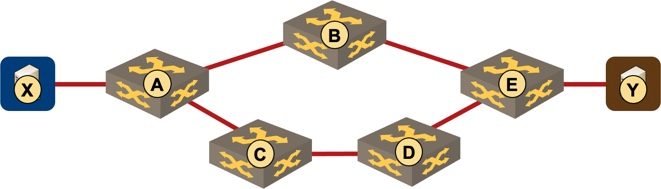
C can be used as a loop-free alternate to protect path from A to Y
Tough Problems
The “fix the problem yourself” requirement is particularly hard in networks without readily available backup paths – rings are a perfect example. For example, when the link between B and E fails in the following topology, B has a really hard time figuring out how to forward IP traffic toward Y before the routing protocol does its job.
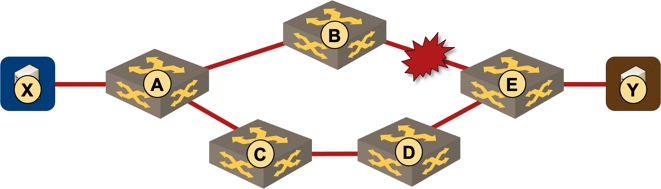
How could B provide fast failure protection for traffic to Y?
Remember that most network-layer packet forwarding implementations use destination-only hop-by-hop forwarding. Imagine B trying to get traffic to Y by sending it through A. As long as A doesn’t know anything about the link failure between B and E, it happily forwards the traffic back to B resulting in a (temporary) forwarding loop.
Conclusion: the only way to implement fast failover in topologies without obvious backup paths is to change the forwarding paradigm using either virtual circuits or source routing. Welcome to the wonderful world of remote LFA, a complex topic deserving its own blog post.
More Information
We’ll discuss routing protocol convergence, link- or node failure detection, multipathing, loop-free alternates and much more in the Advanced Routing Protocol Topics part of Networks Really Work webinar).