… updated on Friday, November 20, 2020 15:10 UTC
How Fast Can We Detect a Network Failure?
In the introductory fast failover blog post I mentioned the challenge of fast link- and node failure detection, and how it makes little sense to waste your efforts on fast failover tricks if the routing protocol convergence time has the same order of magnitude as failure detection time.
Now let’s focus on realistic failure detection mechanisms and detection times. Imagine a system connecting a hardware switching platform (example: data center switch or a high-end router) with a software switching platform (midrange router):
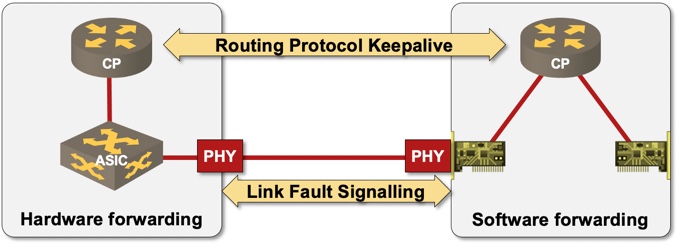
Sample 2-node network with a hardware- and software switching platform
Hardware switching platform has a CPU (control plane), switching hardware (data plane), and a number of transceivers (PHY modules). Software switching platform has a CPU (that runs control- and data planes), interface cards, and transceivers.
Physical Link Failure
The fastest link failure detection mechanism is the physical link failure detection sometimes called (for historical reasons) loss of carrier (or light in optical networks). That mechanism kicks in as soon as you get a clean cable cut, but cannot detect unidirectional problems, or somewhat-faulty cables introducing spurious transmission errors.
Some physical layers – including Gigabit Ethernet – provide end-to-end fault detection (link fault signaling in the above diagram). While that might seem like a perfect solution, do keep in mind that LFS works between transceivers, and thus cannot detect faulty transceivers or faults deeper inside the network node.
Data Link Layer Protocols
Many data link layer (layer-2) technologies provide link fault detection mechanisms - LACP timers, UDLD, Ethernet Connectivity and Fault Management (CFM)… These protocols are often run by the control plane, and are thus correspondingly slow. Example: LACP packets are sent once per second when using fast LACP timers, and it takes three seconds to detect LAG failure.
Some people argue that you don’t need UDLD (on layer-2) or BFD (on layer-3) in a Gigabit Ethernet network due to built-in Link Fault Signaling (LFS). Looking at the above diagram, it becomes painfully obvious that LFS tests PHY-to-PHY path, whereas UDLD and BFD provide more comprehensive tests… but if you think the only failure that could ever happen is a cable cut, go ahead.
Bidirectional Forwarding Detection
Bidirectional Forwarding Detection (BFD) seems like an ideal solution, at least while looking at vendor PowerPoint decks. The reality is a bit different, although it’s still much better to use BFD than to tweak BGP or OSPF timers.
High-end platforms were able to run BFD in hardware years ago, and provided very short failure detection times. Modern data center switching ASICs have hardware dedicated to OAM functionality, including BFD and Ethernet CFM.
However, that hardware might not be used by the software running on the device, or the hardware-software combination might have numerous limitations like:
- No hardware BFD on link aggregation groups or member links (micro-BFD);
- No hardware BFD over layer-3 subinterfaces, or VLAN (SVI) interfaces;
- Hardware cannot run multi-hop or authenticated BFD sessions.
It is also unclear (from what sparse vendor documentation is available) whether the hardware BFD functionality includes transmission, timeout detection, and link state management, or just the packet transmission. There’s also the “minor” detail of timer granularity supported by the BFD hardware.
Most other devices, including data center switching running software that does not support hardware-assisted BFD, run BFD in software and can provide somewhat-stable failure detection in hundreds of milliseconds.
Multi-Access Networks
So far we focused on detecting failures on point-to-point links. Multi-access networks and paths containing invisible third-party devices (media converters, Ethernet switches…) add a new layer of complexity that we’ll discuss in Advanced Routing Protocol Topics part of How Networks Really Work webinar.
Summary
Long story short:
- Total interface loss (cable cut) can be detected in milliseconds;
- Detecting any other failure requires data link- or network-layer protocols, and usually requires hundreds of milliseconds.
Keep these facts in mind when evaluating whether it makes sense to spend time designing a perfect fast failover solution.
Release History
- 2020-11-20: Added (some, sparse) details on hardware-assisted BFD after being prodded in the right direction by Jeff Tantsura. Inserted section headers for easier readability.
Hi there,
I just wanted to add a couple of BFD implementation info I have come across:
1) some implementations make use of the central CPU to scale BFD up since they provide the central CPU with the very same forwarding ASIC that is on the cards while others use the CPU on the line cards
2) BGP PIC-CORE implementation is, to me, very much ECMP fast-rehashing but at a higher indirection level of the hierarchical FIB as it applies to service/BGP prefixes in a BGP multipath scenario. What I found regarding BFD is that in some implementations the trigger for the fast-rehashing at that higher level can be both an interface-down or a BFD session-down event but in other implementations it’s the BFD session-down event only that triggers the ECMP fast-rehashing.
Ciao
Andrea