Implications of Valley-Free Routing in Data Center Fabrics
As I explained in a previous blog post, most leaf-and-spine best-practices (as in: what to do if you have no clue) use BGP as the IGP routing protocol (regardless of whether it’s needed) with the same AS number shared across all spine switches to implement valley-free routing.
This design has an interesting consequence: when a link between a leaf and a spine switch fails, they can no longer communicate.
For example, when the link between L1 and C1 in the following diagram fails, there’s no connectivity between L1 and C1 as there’s no valley-free path between them.
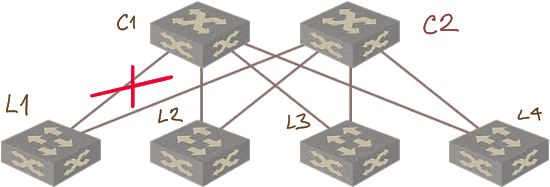
Link failure results in connectivity loss due to lack of valley-free path
No big deal, right? After all, we built the data center fabric to exchange traffic between external devices attached to leaf nodes. Well, I hope you haven’t connected a firewall or load balancer straight to the spine switches using MLAG or a similar trick.
Lesson learned: connect all external devices (including network services devices) to leaf switches. Spine switches should provide nothing more than intra-fabric connectivity.
There’s another interesting consequence. As you might know, some vendors love designs that use IBGP or EBGP EVPN sessions between loopback interfaces of leaf and spine switches on top of EBGP underlay.
Guess what happens after the L1-C1 link failure: the EVPN session between loopback interfaces (regardless of whether it’s an IBGP or EBGP session) is lost no matter what because L1 cannot reach C1 (and vice versa) anyway.
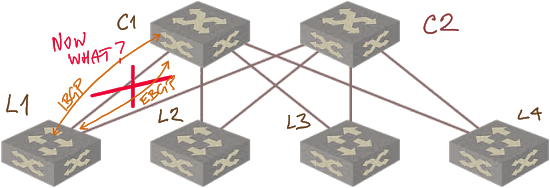
EVPN session failure following a link loss
Inevitable conclusion: all the grand posturing explaining how EVPN sessions between loopback interfaces running on top of underlay EBGP are so much better than EVPN running as an additional address family on the directly-connected EBGP session in a typical data center leaf-and-spine fabric is plain merde (pardon my French).
Even worse, I’ve seen a vendor-produced design that used:
- EBGP in a small fabric that would work well enough with OSPF for the foreseeable future;
- IBGP EVPN sessions between loopback interfaces of leaf and spine switches;
- Different AS numbers on spine switches to make it all work, turning underlay EBGP into a TCP version of RIPv2 using AS path length as the hop count.
As I said years ago: the road to broken design is paved with great recipes.
Lesson learned: whenever evaluating a design, consider all possible failure scenarios.
Don’t get me wrong. There might be valid reasons to use IBGP EVPN sessions on top of EBGP underlay. There are valid reasons to use IBGP route reflectors implemented as VNF appliances for scalability… but the designs promoted by most networking vendors these days make little sense once you figure out how routing really works.
For the Few People Interested in the Red Pill
If you want to know more about leaf-and-spine fabrics (and be able to figure out where exactly the vendor marketers cross the line between unicorn-colored reality and plain bullshit), start with the Leaf-and-Spine Fabric Architectures and EVPN Technical Deep Dive webinars (both are part of Standard ipSpace.net subscription).
Finally, when you want to be able to design more than just the data center fabrics, check out the Building Next-Generation Data Center online course.
1) How fast the device detects the failure
2) How long does it take to recompute a backup path
3) How long does it take to propagate the changes to the neighbors
4) Time to install the backup path in hardware
So with directly connected links and backup paths already installed in hardware, I don't see a big problem or am I overlooking something?
- An EBGP session interface-to-interface
- Use this session to advertise IP connectivity (i.e. act as the IGP)
- Use this session to advertise EVPN routes
In this case, what do you expect the BGP next hop for the EVPN routes to be? I think it's got to be the loopback address so that the other leaf nodes can reach it via ECMP across C1 and C2. Is the reason that some vendors want to run a separate EBGP session loopback-to-loopback for EVPN because they can't advertise the EVPN routes with a different next hop to that of the IP routes?
Yes, the EVPN next hop must always remain the VTEP (loopback) IP address of the egress leaf. You just gave me another reason why some vendors insist so adamantly on using BGP sessions between loopbacks...
I would think this is still the simplest and most elegant solution. Use IS-IS in the fabric, and EVPN in the overlay. Why isn't this the most popular design still ? Is IS-IS not good enough ? Are IS-IS implementations not good enough these days ?
If that is the case, improve IS-IS. Don't misuse BGP. Using BGP as an IGP is like using assembly to build a website. It works, but it is ugly. Fix the shortcomings in the IS-IS protocol. Fix IS-IS implementations. Is the industry really unable to do this ? Rift, LSVR, openFabric, they all seem overkill to me. Just fix what's broken, don't re-invent the wheel.
https://blog.ipspace.net/2018/05/is-ospf-or-is-is-good-enough-for-my.html
https://blog.ipspace.net/2018/08/is-bgp-good-enough-with-dinesh-dutt-on.html
Unfortunately this industry is brimming with lemmings... and what was good enough for Microsoft data center must be good enough for my two switches, right? RIGHT? RIGHT???
1) One can put the Spine switches in different ASNs - Is a bit of extra I/O but does the trick
2) IS-IS in the underlay would be a better solution as it can be deployed with existing implementation -
a bit of mesh-group config on the leafs and you can control the flooding explosion of vanilla IS-IS implementations - finally UUNets top scaling feature is been used again after almost 20 years of hibernation ;-)
everything could be made work with infinite efforts of turning all possible knobs one could imagine OR let’s make eBGP behave like iBGP?!?! Why going so far if the solution is that near?
Yes, I understand the link and switch failure/repair cases need to be dealt with, and no I'm not talking about the theoretical SDN case so popular a decade ago.
This is a 10,000 line of code problem at the switch level, not a 10,000,000 line of code problem. Just saying.
However, you have to solve fundamental challenges like failure detection, path checks, fast rerouting/convergence, minimization of FIB rewrites... so in the end it's not exactly a 10K line-of-code problem either as some (religiously correct) SDN vendors discovered a while ago.