What Is Layer-2 and Why Do We Need It?
I’m constantly ranting against large layer-2 domains; recently going as far as saying “we don’t really need all that stuff.” Unfortunately, the IP+Ethernet mentality is so deeply ingrained in every networking engineer’s mind that we rarely ever stop to question its validity.
Let’s fix that and start with the fundamental question: What is Layer-2?
I don’t know whether they still teach OSI model in baseline networking courses (they should), but if you’re lucky enough to have heard about it, this is probably the picture you’ve seen:
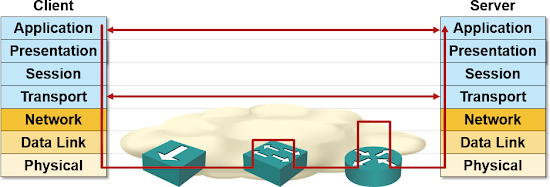
Bottom layers of the OSI stack
Layer-1 (physical layer) is easy to explain: it defines the connectors, voltages and encoding scheme needed to pass a bunch of zeroes and ones between adjacent devices.
Networking devices working at layer-1 convert zeroes and ones between different voltages or transmission media. A few examples: modems (the traditional ones, not the thing that connects your WiFi to cable network, that one is at least a bridge if not a router), media converters (fiber-to-copper converters are still reasonably popular), hubs (you have to be pretty old to have real-life experience with them) and Media Access Units (Token Ring anyone?).
Layer-2 is where things get complex. It was initially defined as the layer that allows adjacent network devices to exchange frames. Every layer-2 technology has to define at least these components:
- How do you group zeroes and ones provided by layer-1 into frames (proper layer-2 terminology for packets);
- Start-of-frame indication (the receiver has to know a new frame is coming), sometimes also know as frame synchronization;
- End-of-frame indication, which can be either a special bit sequence or frame length encoded somewhere else in the frame;
- Error correction mechanism in case the physical layer cannot guarantee error-free transmission of zeroes and ones (they usually don’t);
Have you noticed that I haven’t mentioned layer-2 addresses (known as MAC addresses in Ethernet)? There’s a simple reason for that: sometimes you don’t need them. You only need layer-2 addresses when you have more than two devices attached to the same physical network, like we used to have in the old cable-based Ethernet networks:
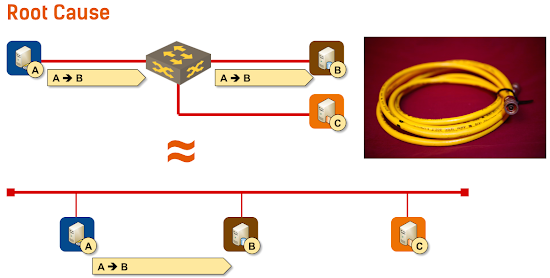
Emulating coax cable with Ethernet gear
The first time you truly need unique addresses is layer-3, which should provide end-to-end packet delivery across the network.
Now let’s answer some interesting questions:
Why do we have MAC addresses in Ethernet frames? Because the original Ethernet used a coax cable with numerous devices attached to the same physical medium.
Why do we still use MAC addresses in Ethernet frames? Because IEEE always wanted to keep everything backward compatible with the original Ethernet. 100 Mbps Ethernet still supported hubs (think of them as cable extenders), and 10GE is the first Ethernet technology that doesn’t have half-duplex support.
Do we still need layer-2? In many cases, the answer is no. Every device that uses software-based forwarding can act as a layer-3 forwarding device (properly known as router but called layer-3 switch by almost everyone). Hardware in many high-speed forwarding devices (particularly switches deployed in data centers) already supports layer-3 forwarding.
Why are we still using layer-2? Because every vendor (apart from Amazon and initial heroic attempts by Hyper-V Network Virtualization team) thinks they need to support really bad practices that originated from the thick yellow coax cable environment, like protocols without layer-3 (and thus no usable end-to-end addresses) or solutions that misuse the properties of shared medium in ways nobody ever envisioned.
Finally, why is everyone using frame format from 40 year old technology? Because nobody wants to change the device drivers in every host deployed in a data center (or in the global Internet).
Want to Know More?
Read these blog posts and watch the How Networks Really Work webinar
That being said, a very interesting point. I never looked at it that way, and now I understand it better.
Additionally, legacy applications (think old school MS SLB) sometimes *required* broadcast reachability. Bad decisions from the get-go, but sometimes reality fails to achieve the Best, or even a Good, answer(s).
IPv6 really makes this easy - Link Local addresses are already there, and GUAs are (effectively) limitless as well.
And moving forward, methinks IP fabrics will take everything else over (atleast in the data center space).
/TJ
However I agree with your v6 statement
Named Data Networking:
http://named-data.net/project/archoverview/
http://www.networkworld.com/article/2602109/lan-wan/ucla-cisco-more-join-forces-to-replace-tcpip.html
On the flip side, I would ask why layer 2 overlays (VxLAN et. al) are necessary at all, as given this argument it seems we are bringing some of the crutches of the past into the virtualized world. Why not rely on microsegmentation and be done with it?
faster for storage is better?
The last two times I was involved (however tangentially) in alternate Layer 2's for the data center -- Fibre Channel and InfiniBand -- did not change the outcome of the competition of networks in the 1980s and early 1990s, which was that Ethernet (by which I mean IEEE 802.1, 3, 11) won.
Concur that the L3 boundary is moving to the first hop Access switch (the ToR) in some leading edge applications. Note that this adds a lot of participants to the Layer 3 routing protocols, leading to at least some centralized control (regardless of whether it's called SDN, or a route reflector, or some other name) not unlike the centralized control which would have been needed for large Layer 2 installations.
There is room, particularly in specialized applications like supercomputers, for innovation at Layer 2. I don't mean arbitrarily framing packet headers differently, I mean actually making a big difference for some class of application, or taking a lot of cost out of the solution. A compelling enough design could be mainstreamed, but it's tough to dislodge Ethernet.
Even if it were the case, if you look at it, you would typically need it for VMs acting as servers (client/server context). Can we not solve this with a good service discovery solution or even a load balancer, in which case really the load balancer alone needs to know how to get to the service?
This translates to a set of interesting -- I almost might say "grand challenge" -- problems for networking. VM migration is useful; keeping a TCP session alive is sometimes useful; being able to migrate a (block of) IPs from one data center to another live is useful. But these are tools in a toolbox, not solutions in their own right.
The "solution" is that my gmail window never hangs; my google maps application never hangs; my netflix movie never hangs and has to be restarted; Amazon never goes away, or wipes my shopping cart, or hangs in a way that my web browser or mobile application needs to be closed and restarted.
North/South: once the client has resolved the server to a single IP address, that IP address needs to keep responding to the client, regardless of particular servers / load balancers / routers / electrical transformers finding themselves engulfed in flames or otherwise offline.
If the protocol is stateless (meaning the application was written in the last decade rather than in the 1990s) then it doesn't matter who's home, just somebody has to be.
From an East/West perspective, if a collection of services which depend on each other is being live migrated, say to new hardware (which could be in a different data center) then keeping both IP's and MAC addresses intact will be important. My guess is Google is able to open new capacity and then shut down old capacity, so doesn't do such migrations. Again, traditional Enterprise is very different: there will be a single instance of an application, with resources spent to make it reliable: very difficult to shut down the SAP back end to migrate it.
It could be that the key east-west case is consolidated storage. Remember a couple of years ago when a network partition in a storage chunk of an Amazon data center caused a bunch of storage servers to simultaneously think they were the single surviving copy of data, and start emergency replication, bringing not just that storage chunk but the AWS instances depending on that storage to their knees? Yes, relative to people who'd done big disk arrays that was a novice specification oversight in an exception path in a piece of software. Back to the point: with that as backdrop, 5 years from now, with AWS live, migrate all of the contents of that chunk of storage to new hardware so the obsolete (not to mention worn-out) disks can be junked. Regardless of whether IP addresses are preserved, the East-West server to storage traffic has to stay live during the entire migration.
See also this blog post on host routes and ARP: http://blog.ipspace.net/2014/02/this-is-not-host-route-youre-looking-for.html
Finally, here's a follow-up article to this one: http://blog.ipspace.net/2015/04/rearchitecting-l3-only-networks.html
Hope this helps,
Ivan