Can We Use IPv6 Router Advertisements for Fast Failover?
Ed Horley opened another juicy can of worms in a comment to my First-Hop Load Balancing in IPv6 post: can we use IPv6 RA for fast failover (and high availability)?
TL&DR summary: it depends.
RA-based fast failure detection
IPv6 router advertisements messages contain router lifetime field (measured in seconds). Using a one-second lifetime might be questionable due to host IPv6 stack implementation details, but two seconds should be a very reasonable value.
Cisco IOS can send RA messages every few milliseconds (300 msec RA interval should be good enough for 1 second lifetime). Problem solved (unless your application needs sub-second failover)… and it actually works. However…
Maybe we should stick with FHRP
Ignoring for the moment the fact that very short RA interval burns CPU cycles on every host attached to the IPv6 subnet (which is OK in campus networks where users don’t know what to do with 8 cores in their laptops anyway, but maybe not in a large server subnet), there’s another gotcha: IPv6 forwarding across MLAG-enabled switches.
Imagine two layer-3 switches in an MLAG group (example: Cisco’s VPC). Even though these two switches appear as a single entity to LACP neighbors, they still have independent MAC addresses and IPv6 link-local addresses. Each switch advertises itself using its IPv6 LLA, and the hosts in the attached subnet choose one or both of them as the first-hop router… but both IPv6 LLA appear to be reachable over the same LAG to attached hosts or layer-2 switches.
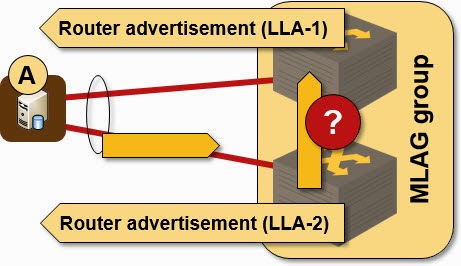
Off-link traffic sent to one or the other router (layer-3 switch) will thus take any one of the uplinks (based on the packet’s ECMP hash value) and will land at the wrong switch half of the time, resulting in overloaded inter-switch link (best case) or dropped traffic (worst case).
To make IPv6 work across layer-3 switches configured as an MLAG group you have to use the same tricks you did with IPv4: virtual ARP on Arista EOS (it works with IPv4 and IPv6) or active-active VRRP or HSRP on most other platforms.
This should only be needed in case of a requirement for two physical uplinks (A/B-net) to the endhost. Single linked clients should have their L3 first-hop on their physical first-hop anyway :-)
http://blog.ipspace.net/2012/12/do-we-need-fhrp-hsrp-or-vrrp-for-ipv6.html
Thanks for pointing this out, will cross-link the two posts.