Deutsche Telekom TeraStream: Designed for Simplicity
Almost a year ago rumors started circulating about a Deutsche Telekom pilot network utilizing some crazy new optic technology. In spring I’ve heard about them using NFV and Tail-f NCS for service provisioning … but it took a few more months till we got the first glimpses into their architecture.
TL&DR summary: Good design always beats bleeding-edge technologies
Business drivers
Deutsche Telekom realized (early enough) that they would start making losses on every single service they offer unless they drastically reduced their costs and simplified service provisioning.
We’ve heard similar arguments numerous times during the last few years (industry press was full of them at the ONF launch), but Deutsche Telekom decided to go down a totally different route. Instead of invoking the ghosts of virgin unicorns and sprinkling pixie dust on white-label boxes they decided to go back to the basics and design the next-generation network from scratch, simplifying every single component.
Horseshoes instead of rings
Everyone is building ring networks these days. Deutsche Telekom decided to build horseshoes – a broken ring connecting two core routers (at different locations) with edge (PE) routers in the same region.
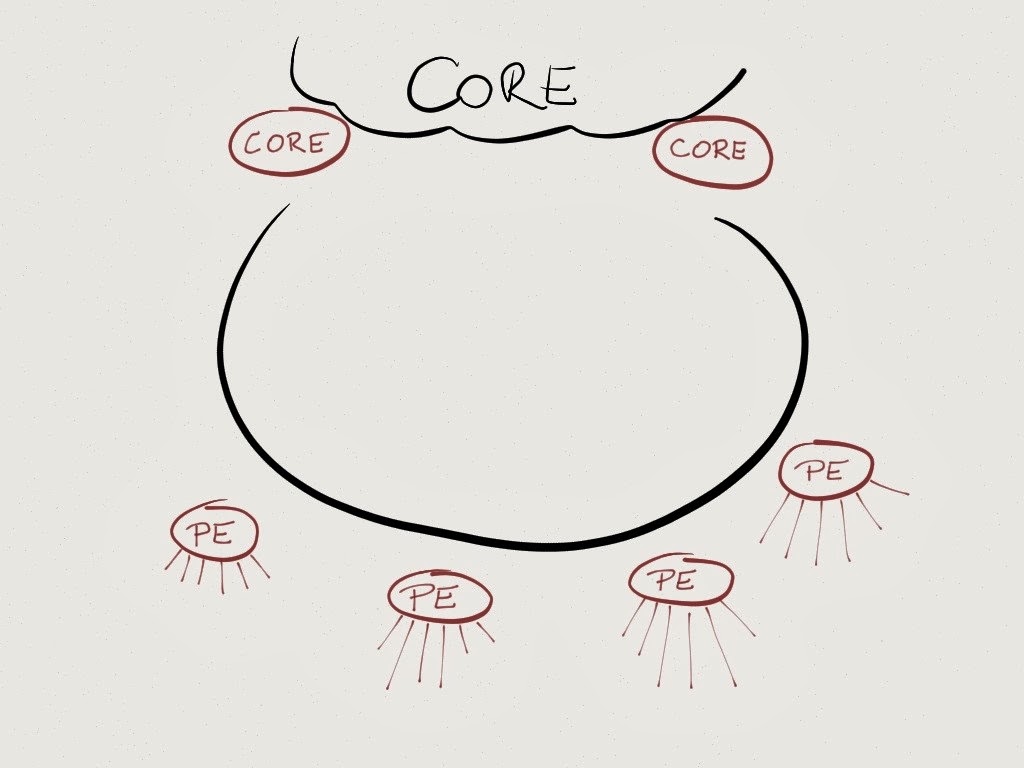
Everyone is using complex (and expensive) optical transport gear on long-distance fibers. Deutsche Telekom uses passive add-drop multiplexers and WDM router interfaces (this is the only bleeding-edge part of their solution: they use coherent 100GE optics on router interfaces).
The router interfaces generate signals with the right color to match the ADM to which they are connected. Core routers have numerous interfaces connected to the same ADM (horseshoe headend), PE routers have four 100GE upstream interfaces, each one emitting a different lambda.
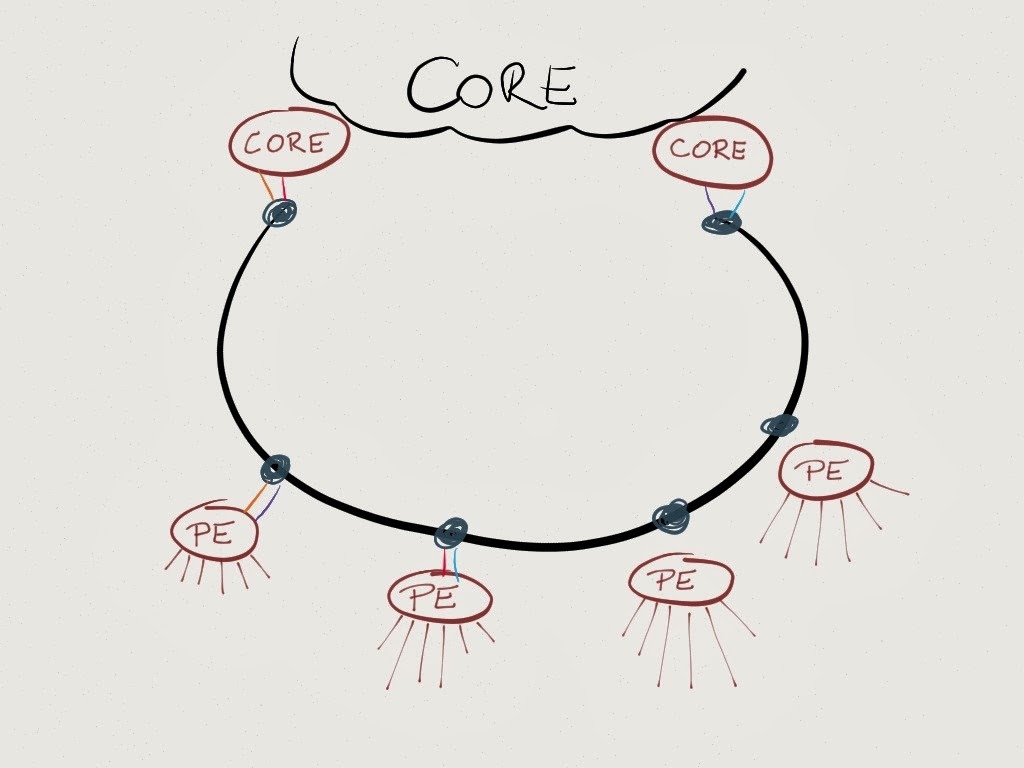
You could further minimize the equipment by generating multi-lambda signal in router linecards, but such a beast has yet to be built with 100GE coherent optics.
The logical topology of the optical network is exceedingly simple. Every PE router has two 100GE lambdas going to each core router, as shown on the next diagram (I drew only one lambda to keep the diagram clean), and they don’t use LAG/LACP (or anything similar) to bond the lambdas, but rely instead on IGP and ECMP.
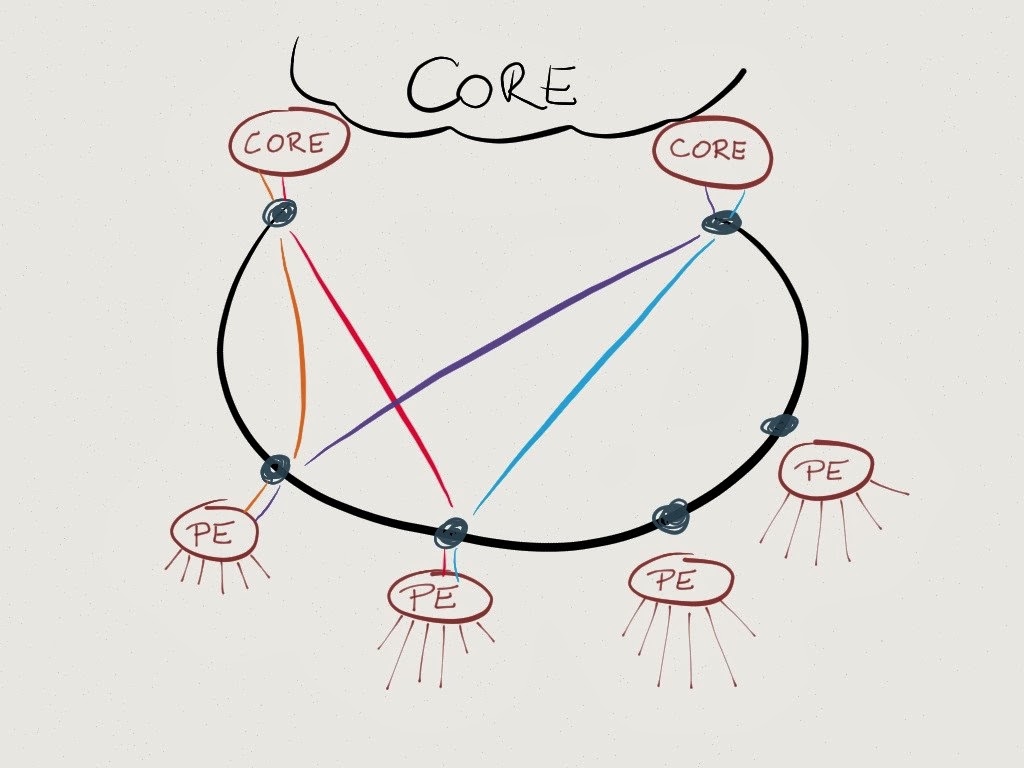
Deutsche Telekom presentations are not very explicit when it comes to the core network (upstream of core routers). If I understood correctly, they have a full mesh between the core routers, but it doesn’t matter that much. Their primary customer base (at least in the Croatian pilot) are residential customers that communicate with servers outside of DT network, and DT tries to keep traffic away from the core by establishing extensive peering relationships between external content providers and as many core routers as possible.
Simplified routing
Having a simple logical topology greatly simplifies the routing. They use a single simple IGP instance with no MPLS whatsoever.
Customer VPNs are implemented with IP encapsulation (L2TPv3 or equivalent), they wouldn’t gain anything by deploying MPLS TE in their topology, and they decided to forgo MPLS fast reroute.
IGP-based LFA would be a good enough fast reroute mechanism in their topology, but (as far as I understood) they decided not to use it. The answer I got from Ian Farrer during his PLNOG presentation was brilliant: “I couldn’t find a single business use case that would require 50 msec failover, and we can easily get 200 msec convergence with IGP.”
The cherry on the top of the already-beautiful cake: they hate the complexities of dual stack, so the access network (horseshoes) is IPv6-only.
End result: extremely simple and reliable network. Easy to operate, easy to troubleshoot, built with traditional technologies, and using traditional equipment (they decided to use ASR 9000s for PE and core routers).
More information
More information
- Ian Farrer’s PLNOG presentation
- Peter Lothberg’s Terastream IPv6 Details from RIPE67 (video)
- Building Large-Scale IPv6 Service Provider Networks
- IPv6-Only Data Centers
One correction you should make in the blog post: The reality is they are still using transport systems. The ASR9K doesn't have a coherent tunable 100G interface and coherent tunable CFP aren't quite out just yet and there is no router support for them. The only vendor shipping a coherent tunable 100G port is Juniper on the PTX.
In the presentation posted they use the terms "physical" and "logical" for the packet/optical piece. The "logical" solution (what they are doing today) involves using the management/control plane to make the 100GE CFP port on the router look like a tunable port by managing a 1:1 relationship with the coherent tunable port on the transport shelf, in this case Cisco M6, they even show a diagram stating "iOverlay" which is a Cisco term. Cisco makes the M6 look like a transparent extension to the ASR9K but it's really connected via a transponder. Cisco is pushing this over router coherent optics now because they can't get the density on the router. For instance the new NCS6K will likely never have built-in DWDM optics, they will always use an add-on shelf (NCS4K/2K) and then make the transponder interconnect really cheap using CPAK/MPO cables. You will be able to "tune" the port on the routers since there is a 1:1 relationship. It looks like they have done some testing with Coriant (old NSN) and ALU transport gear as well.
The rest of the "transport system" is just passive mux/demuxes and amps if you aren't using the ROADM modules. If you don't need a multi-degree ROADM then all you need is a mux/demux.
I wasn't given an answer to this question of mine.