A Day in a Life of an Overlaid Virtual Packet
I explain the intricacies of overlay network forwarding in every overlay-network-related webinar (Cloud Computing Networking, VXLAN deep dive...), but never wrote a blog post about them. Let’s fix that.
First of all, remember that most mainstream overlay network implementations (Cisco Nexus 1000V, VMware vShield, Microsoft Hyper-V) don’t change the intra-hypervisor network behavior: a virtual machine network interface card (VM NIC) is still connected to a layer-2 hypervisor switch. The magic happens between the internal layer-2 switch and the physical (server) NIC.
Nicira’s NVP is a bit different (Open vSwitch can do much more than simple layer-2 forwarding), but as it performs L2-only forwarding within a single logical subnet, we can safely ignore the differences.

Typical overlay virtual networking architecture
The diagrams were taken from the VXLAN course and thus use VXLAN terminology. Hyper-V uses similar concepts and slightly different acronyms and encapsulation format.
The TCP/IP stack in a VM (or any other network-related software working with the VM NIC driver) is totally oblivious to its virtual environment – it looks like the VM NIC is connected to a real Ethernet segment, and so when the VM TCP/IP stack needs to send a packet, it sends a full-fledged L2 frame (including source and destination VM MAC address) to the VM NIC.
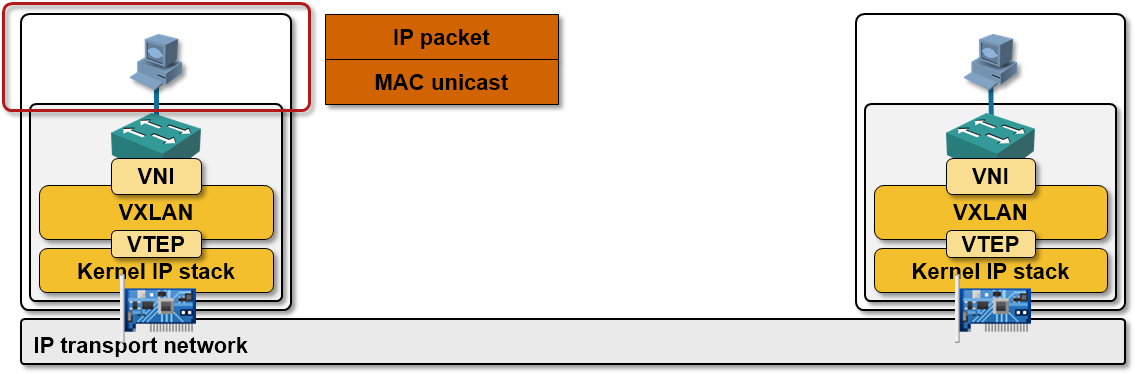
A VM sends a layer-2 frame through its VM NIC
The first obvious question you should ask is: how does the VM know the MAC address of the other VM? Since the VM TCP/IP stack thinks the VM NIC connects to an Ethernet segment, it uses ARP to get the MAC address of the other VM.
Second question: how does the ARP request get to the other VM? Please allow me to handwave over this tiny little detail for the moment; BUM (Broadcast, Unknown Unicast, Multicast) flooding is a topic for another blog post.
Now let’s focus on what happens with the layer-2 frame sent through the VM NIC once it hits the hypervisor switch. If the destination MAC address belongs to a VM residing in the same hypervisor, the frame gets delivered to the destination VM (even Hyper-V does layer-2 forwarding within the hypervisor, as does Nicira’s NVP unless you’ve configured private VLANs).
If the destination MAC address doesn’t belong to a local VM, the layer-2 forwarding code sends the layer-2 frame toward the physical NIC ... and the frame gets intercepted on its way toward the real world by an overlay virtual networking module (VXLAN, NVGRE, GRE or STT encapsulation/decapsulation module).
The overlay virtual networking module uses the destination MAC address to find the IP address of the target hypervisor, encapsulates the virtual layer-2 frame into an VXLAN/(NV)GRE/STT envelope and sends the resulting IP packet toward the physical NIC (with the added complexity of vKernel NICs in vSphere environments).
Every single overlay virtual networking solution needs jumbo frames in the transport network to work well - you really wouldn't want to reduce the MTU size on every single VM NIC
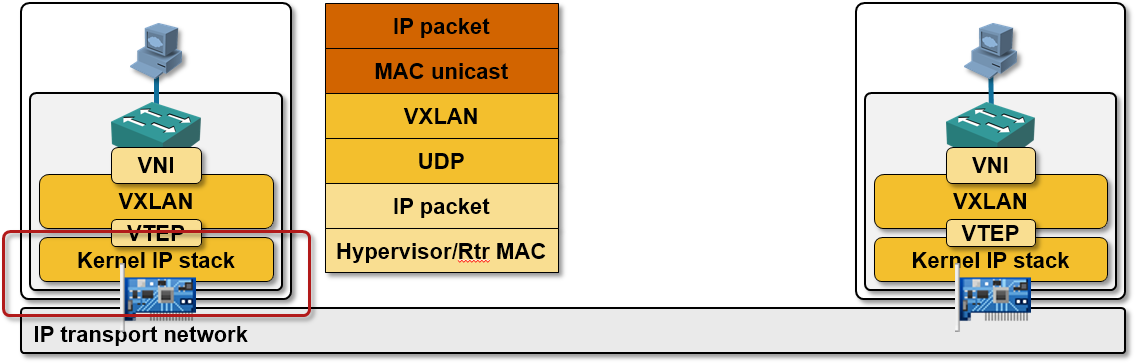
Encapsulated virtual packet is sent toward the physical NIC
Glad you asked the third question: how does the overlay networking module know the IP address of the target hypervisor??? That’s the crux of the problem and the main difference between VXLAN and Hyper-V/NVP. It’s clearly a topic for yet another blog post (and here’s what I wrote about this problem a while ago). For the moment, let’s just assume it does know what to do.
The physical network (which has to provide nothing more than simple IP transport) eventually delivers the encapsulated layer-2 frame to the target hypervisor, which uses standard TCP/IP mechanisms (match on IP protocol for GRE, destination UDP port for VXLAN and destination TCP port for STT) to deliver the encapsulated layer-2 frame to the target overlay networking module.
Things are a bit more complex: in most cases you’d want to catch the encapsulated traffic somewhere within the hypervisor kernel to minimize the performance hit (each trip through the userland costs you extra CPU cycles), but you get the idea.
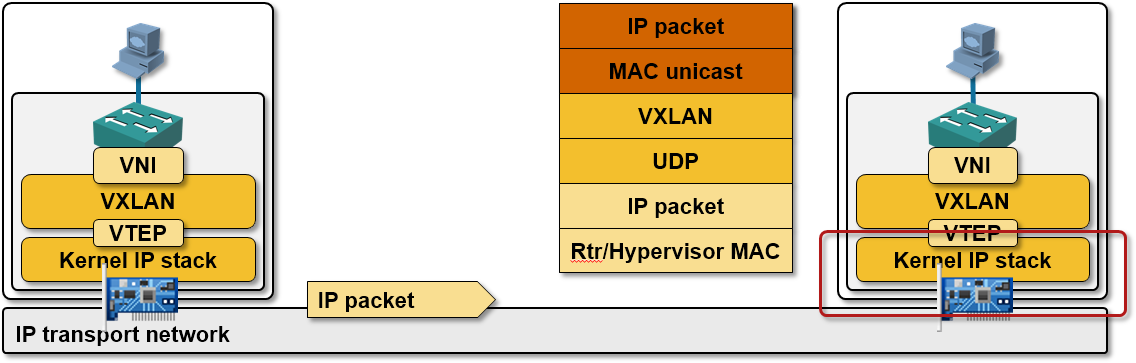
Last step: the target overlay networking module strips the envelope and delivers the raw layer-2 frame to the layer-2 hypervisor switch which then uses the destination MAC address to send the frame to the target VM-NIC.
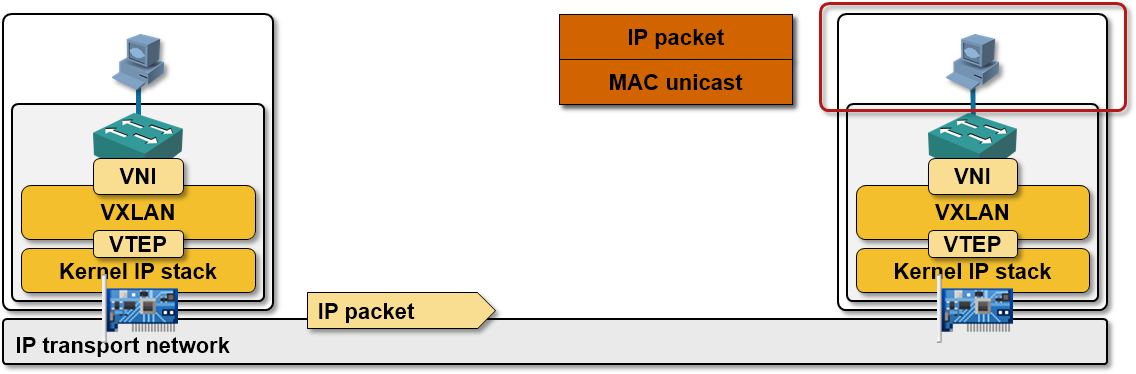
Summary: all major overlay virtual networking implementations are essentially identical when it comes to frame forwarding mechanisms. The encapsulation wars are thus stupid, with the sole exception of TCP/IP offload, and some vendors have already started talking about multi-encapsulation support.

You meant "vSwitch", not "vShield", right? ;)
ARP reply is sent as unicast and wouldn't leave the hypervisor if the two VMs reside on the same VXLAN segment - same behavior as traditional Ethernet switches.
Gratuitous ARP reply (used for shared IP takeover) is sent to broadcast address ==> flooded.
Steven Iveson