Stackable Data Center Switches? Do the Math!
Imagine you have a typical 2-tier data center network (because 3-tier is so last millennium): layer-2 top-of-rack switches redundantly connected to a pair of core switches running MLAG (to get around spanning tree limitations) and IP forwarding between VLANs.
Next thing you know, a rep from your favorite vendor comes along and says: “did you know you could connect all ToR switches into a virtual fabric and manage them as a single entity?” Is that a good idea?
This blog post was written in the days when the data center switching vendors loved proprietary approaches to layer-2 fabrics. Those same vendors now admire EVPN and VXLAN, but you might still get exposed to “interesting” ideas, so it’s better to be prepared.
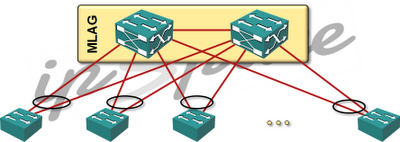
Typical layer-2 leaf-and-spine design
Assuming you have typical 64-port 10GE ToR switches and use pretty safe 3:1 oversubscription ratios, you have 48 10GE server-facing ports and 16 10GE (or 4 40GE) uplinks. If the core switch is non-blocking (please kick yourself if you bought an oversubscribed core switch in the last year or two), every server has equidistant bandwidth to every other server (servers connected to the same ToR switch are an obvious exception).
Unless you experience some nasty load balancing issues where numerous elephant flows hash onto the same physical link, every server gets ~3.33 Gbps of bandwidth toward any other server.
Now let’s connect the top-of-rack switches into a stack. Some vendors (example: Juniper) use special cables to connect them; others (HP, but also Juniper) connect them via regular 10GE links. In most scenarios I’ve seen so far you connect the switches in a ring or a daisy chain.
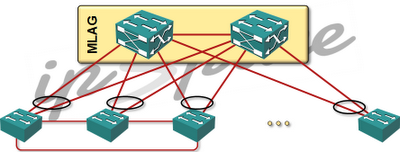
Introducing stackable leaf switches
What happens next depends on the traffic profile in your data center. If most of your server traffic is northbound (example: VDI, simple web hosting), you probably won’t notice a difference, but if most of your traffic is going between servers (east-west traffic), the stacking penalty will be huge.
The moment you merge the ToR switches into a stack (regardless of whether it’s called Virtual Chassis or Intelligent Resilient Framework) the traffic between servers connected to the same stack stays within the stack, and the only paths it can use are the links connecting the ToR switches.
Now do the math. Let’s assume we have four HP 5900 ToR switches in a stack, each switch with 48 server-facing 10GE ports and 4 40GE uplinks. The total uplink bandwidth is 640 Gbps (160 Gbps per switch times four ToR switches) and if half of your traffic is server-to-server traffic (it could be more, particularly if you use Ethernet for storage or backup connectivity), the total amount of server-to-server bandwidth in your network is 320 Gbps (which means you can push 640 Gbps between the servers using marketing math).
Figuring out the available bandwidth between ToR switches is a bit trickier. Juniper’s stacking cables work @ 128 Gbps. HP’s 5900s can use up to four physical ports in an IRF link; that would be 40Gbps if you use 10GE ports and 80Gbps if you use all four 40GE ports on an HP5900 for two IRF links.
You might get lucky with traffic distribution and utilize multiple segments in the ring/chain simultaneously, but regardless of how lucky you are, you’ll never get close to the bandwidth you had before you stacked the switches together, unless you started with a large oversubscription ratio.
Furthermore, by using 10GE or 40GE ports to connect the ToR switches in a ring or daisy chain, you’ve split the available uplink ports into two groups: inter-server ports (within the stack) and northbound ports (uplinks to the core switch). In a traditional leaf-and-spine architecture you’re able to fully utilize the all the uplinks regardless of the traffic profile; the utilization of links in a stacked ToR switch design depends heavily on the east-west versus northbound traffic ratio (the pathological case being known as Monkey Design).
Conclusion: daisy-chained stackable switches were probably a great idea in campus networks and 1GE world; be careful when using switch stacks in data centers. You might have to look elsewhere if you want to reduce the management overhead of your ToR switches.
More information
Leaf-and-spine architecture is just the simplest example of the Clos architecture. You’ll find fabric designs guidelines (including numerous L2- and L3-designs) in the Leaf-and-Spine Fabric Architectures.
I am going to disagree since I believe there are scenarios when you will benefit from stacking on ToR in HP case.
Suppose all your servers have 4x 10G port and you bundle them to LACP NIC team. You connect those ports to four 5900s in IRF. HP allows to change LAG hashing algorithm to „local first“ – that means if there is connection local to the switch that one is prefered and used. When one server talk to another one - server will use hash and let say it will use first 5900. This 5900 will prefer local connection to second server since there is direct link to it. With this stacking link is not going to be used for your inter-server traffic if all servers have active connections to all nodes of your ToR stack.
In this case inside of your 5900s IRF pod you are always one switch away from one server to another.
Uplinks to core in such case needs to be on every 5900 – agree on that.
Tomas
However, my scenario was a bit different - I have a running network (thus no server-side port channel) and stack the switches.
Will write a follow-up blog post ;)
Ivan
When I recently heard a Juniper presentation, I couldn't help but think, is management overhead really that much of a concern? These are machines who do the management (the config archiving etc.) not humans, I'd think there is little cost associated, once the management system has been bought, therefore little savings.
To me, Virtual Chassis seems like a solution looking for a problem.
http://en.wikipedia.org/wiki/Elephant_flow
I think the wikipedia entry is bogus:
- It is not clear who coined "elephant flow",
- but the term began occurring in published
- Internet network research in 2001...
RFC 1072 dates back to 1988
Non-TCP applications, on the other hand, might break (or slow down significantly) when receiving out-of-order packets.
• 128 Gbps Virtual Chassis module with 2 x 64 Gbps ports.
And as far as I know, this is still marketing. When you display vc-port
show virtual-chassis vc-port (EX4200 Virtual Chassis)
user@switch> show virtual-chassis vc-port
fpc0:
-------------------------------------------------------------------------–
Interface Type Trunk Status Speed Neighbor
or ID (mbps) ID Interface
PIC / Port
vcp-0 Dedicated 1 Up 32000 1 vcp-1
vcp-1 Dedicated 2 Up 32000 0 vcp-0
This means "line speed" is just 32 Gbps.
So this is less than the 80 Gbps you get with an HP switch
just a detail. In a real design I would never virtualize more than two switch in a TOR as one (IRF. VSS, VC, or whatever...)