Midokura’s MidoNet: a Layer 2-4 virtual network solution
Almost everyone agrees the current way of implementing virtual networks with dumb hypervisor switches and top-of-rack kludges (including Edge Virtual Bridging – EVB or 802.1Qbg – and 802.1BR) doesn’t scale. Most people working in the field (with the notable exception of some hardware vendors busy protecting their turfs in the NVO3 IETF working group) also agree virtual networks running as applications on top of IP fabric are the only reasonable way to go ... but that’s all they currently agree upon.

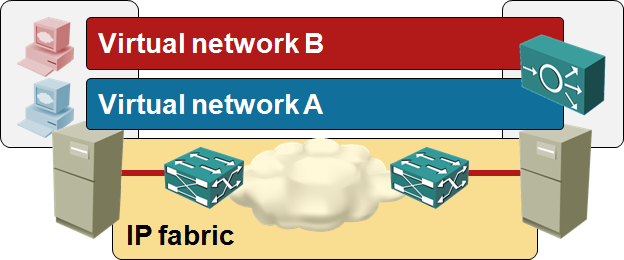
Traditional VLAN-based virtual networks implemented in the physical switches
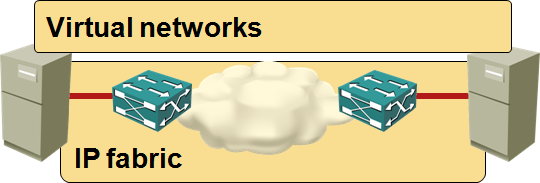
Virtual networks implemented in the hypervisor switches on top of an IP fabric
A brief overview of where we are
Cisco, VMware and Microsoft disappointingly chose the easiest way out: VXLAN and NVGRE are MAC-over-IP virtual networks with no control plane. They claim they need layer-2 virtual networks to support existing applications (like Microsoft’s load balancing marvels) and rely on flooding (emulated with IP multicast) to build the remote-MAC-to-remote-IP mappings in hypervisor virtual switches.
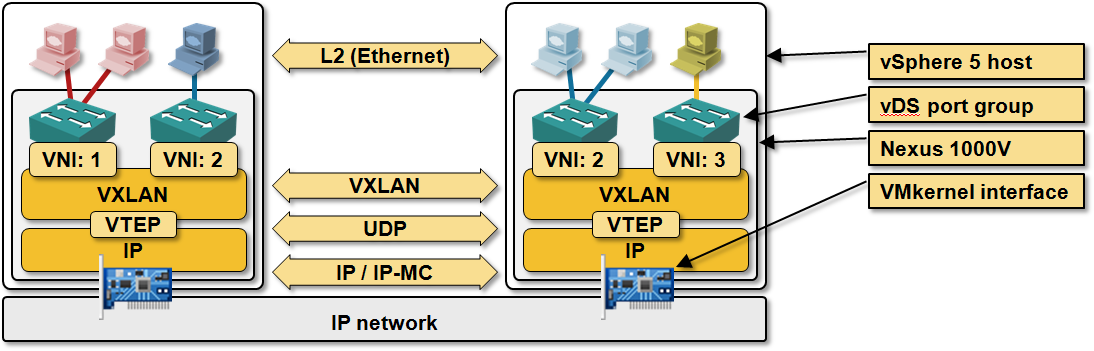
VXLAN architecture
Nicira’s Network Virtualization Platform is way better – it has a central control plane that uses OpenFlow to distribute MAC-to-IP mapping information to individual hypervisors. The version of their software I’m familiar with implemented simple layer-2 virtual networks; they were promising layer-3 support, but so far haven’t updated me on their progress.
The Missing L3-4 Problem
We know application teams trying to deploy their application stacks on top of virtual networks usually need more than a single virtual network (or security zone). A typical scale-out application has multiple tiers that have to be connected with load balancers or firewalls.
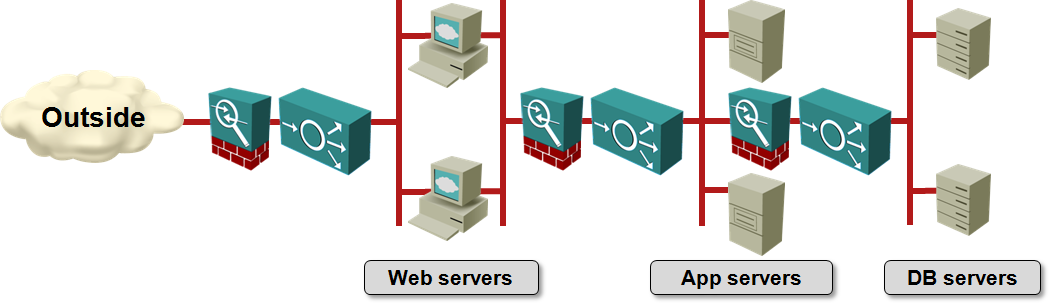
Simplified scale-out application architecture
All the vendors mentioned above are dancing around that requirement claiming you can always implement whatever L3-7 functionality you need with software appliances running as virtual machines on top of virtual networks. A typical example of this approach is vShield Edge, a VM with baseline load balancing, NAT and DHCP functionality.
Load balancer as a VM appliance
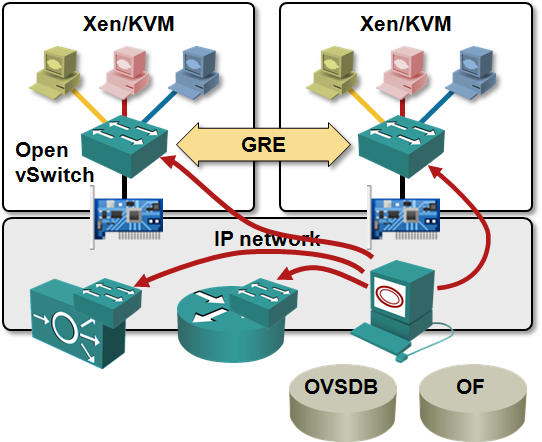
To keep the record straight: VMware, Cisco, Juniper and a few others offer hypervisor-level firewalls; traffic going between security zones doesn’t have to go through an external appliance (although it still goes through a VM if you’re using VMware’s vShield Zones/App). Open vSwitch used by Nicira’s NVP could be easily configured to provide ACL-like functionality, but I don’t know how far Nicira got in implementing it.
Midokura’s MidoNet: a L2-4 virtual SDN
A month ago Ben Cherian left a comment on my blog saying “Our product, MidoNet, supports BGP, including multihoming and ECMP, for interfacing MidoNet virtual routers with external L3 networks.” Not surprisingly, I wanted to know more and he quickly organized a phone call with Dan Mihai Dimitriu, Midokura’s CTO. This is one of the slides they shared with me ... showing exactly what I was hoping to see in a virtual networks solution:
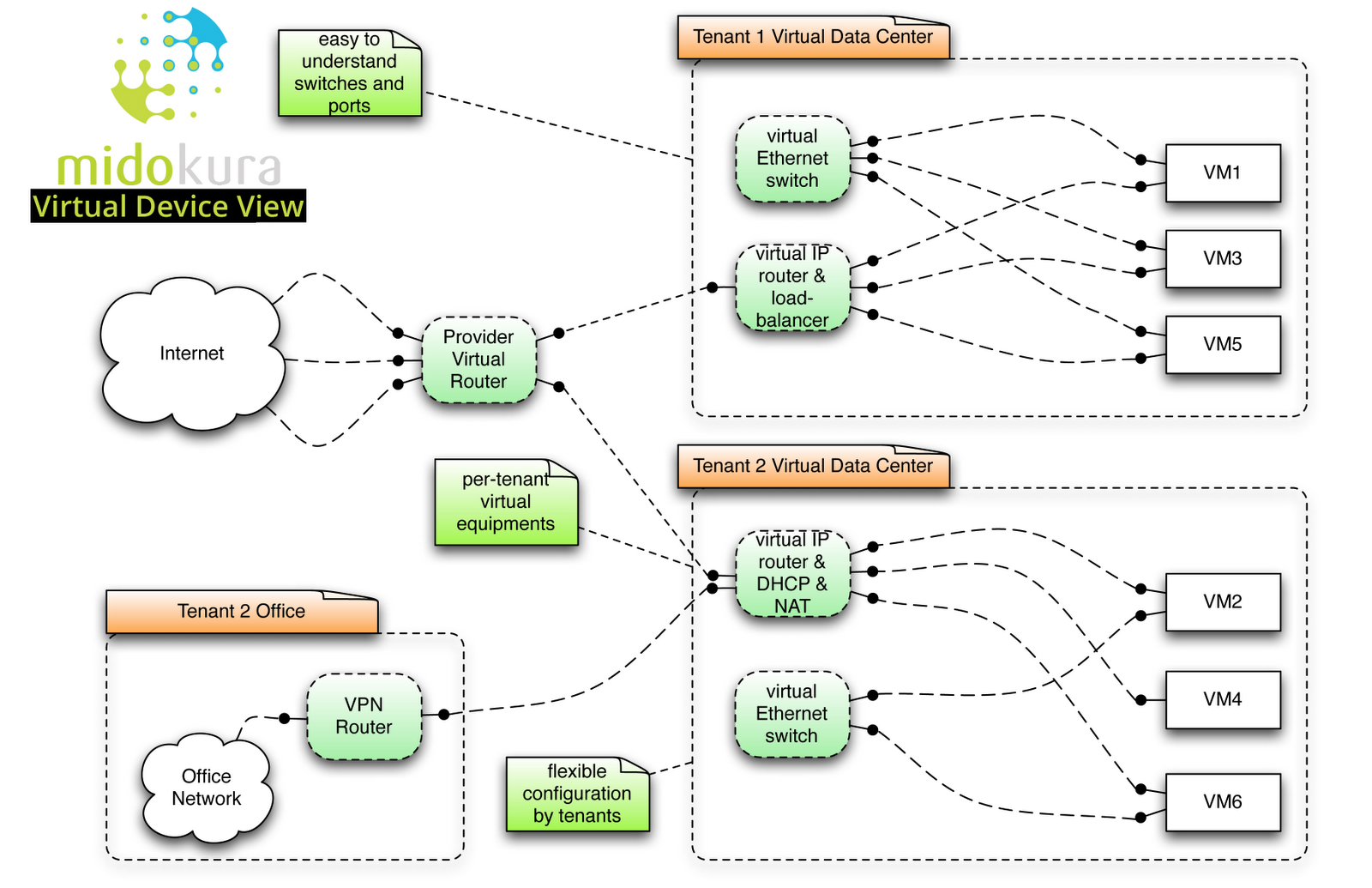
Typical MidoNet virtual network topology
As expected, they decided to implement virtual networks with GRE tunnels between hypervisor hosts. A typical virtual network topology mapped onto underlying IP transport fabric would thus like this:
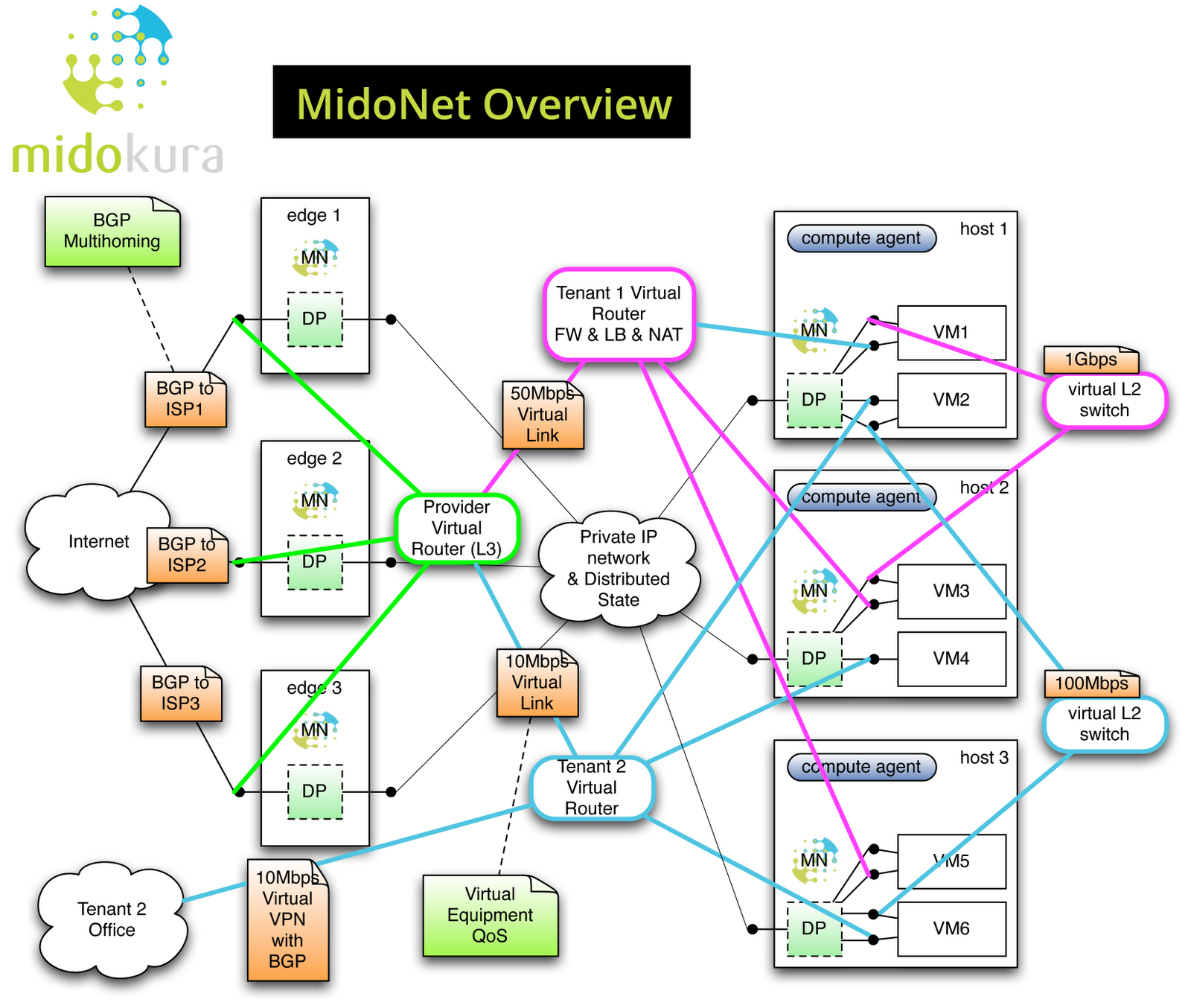
MidoNet virtual networks implemented with commodity
compute nodes on top of an IP fabric
Short summary of what they’re doing:
- Their virtual networks solution has layer-2 virtual networks that you can link together with layer-3 virtual routers.
- Each virtual port (including VM virtual interface) has ingress and egress firewall rules and chains (inspired by Linux iptables).
- Virtual routers support baseline load balancing and NAT functionality.
- Virtual routers are not implemented as virtual machines – they are an abstract concept used by hypervisor switches to calculate the underlay IP next hop.
- As one would expect in a L3 solution, hypervisors are answering ARP and DHCP requests locally.
- The edge nodes run EBGP with the outside world, appearing as a single router to external BGP speakers.
Interestingly, they decided to go against the current centralized control plane religion, and implemented most of the intelligence in the hypervisors. They use Open vSwitch (OVS) kernel module as the switching platform (proving my claim that OVS provides all you need to implement L2-4 functionality), but replaced the OpenFlow agents and centralized controller with their own distributed software.
MidoNet packet forwarding process
This is how Dan and Ben explained a day in the life of an IP packet passing through the MidoNet overlay virtual networks (I haven’t set it up to see how it really works):
Their forwarding agents (running in user space on all hypervisor hosts) intercept traffic belonging to unknown flows (much like the ovs-vswitchd), but process the unknown packets locally instead of sending them to central OpenFlow controller.
The forwarding agent receiving an unknown packet would check the security rules, consult the virtual network configuration, calculate the required flow transformation(s) and egress next hop, install the flow in the local OVS kernel module, insert flow data in a central database for stateful firewall filtering of return traffic, and send the packet toward egress node encapsulated in a GRE envelope with the GRE key indicating the egress port on the egress node.
According to Midokura, the forwarding agents generate the most-generic flow specification they can – load balancing obviously requires microflows, simple L2 or L3 forwarding doesn’t. While the OVS kernel module supports only microflow-based forwarding, the forwarding agent doesn’t have to recalculate the virtual network topology for each new flow.
The egress OVS switch has pre-installed flows that map GRE keys to output ports. The packet is thus forwarded straight to the destination port without going through the forwarding agent on the egress node. Like in MPLS/VPN or QFabric, the ingress node performs all forwarding decisions, the “only” difference being that MidoNet runs as a cluster of distributed software switches on commodity hardware.
Asymmetrical return traffic is no longer an issue because MidoNet uses central flow database for stateful firewall functionality – all edge nodes act as a single virtual firewall.
The end result: MidoNet (Midokura’s overlay virtual networking solution) performs simple L2-4 operations within the hypervisor, and forwards packets of established flows within the kernel OVS.
Midokura claims they achieved linerate (10GE) performance on commodity x86 hardware ... but of course you shouldn’t blindly trust me or them. Get in touch with Ben and test-drive their solution.
Update 2012-10-07: For more details and a longer (and more comprehensive) analysis, read Brad Hedlund's blog post.
Why not go with OpenFlow?
How are convergence times calculated?
What happens with wrong flows that are setup before state is consistent? Are they a drop & retry? Is the flow forwarded to the correct destination by the previous destination as if nothing had happened?
Many thanks, innovative solution. ;)
Pablo Carlier. - (Disclaimer: I am a Cisco Systems Engineer).
If that's the case then install a few OC12 PCI express cards in your UCS chassis or blade enclosure and toss those ASRs out.
I hear Cisco has similar functionality with their CRS.
We created this virtual device model in order to provide a familiar interface that blends be best of VRFs, Amazon VPC, and L2 switching.
The VRF model seems to map well to the multi-tenant IaaS cloud (OpenStack) use case. Our OpenStack plugin creates a virtual router per "project" (virtual data center, VPC, whatever term you like), and attaches multiple L2 networks to it. The service provider's virtual router is wired to each of the projects for routing global IPs.
There should be a lot more companies doing this.
And why were these never mentioned on the packetpushers website or in the podcast ? ;-)
No really, I've been searching for a similar to their solution for months now. I know it kind of looks like it they are going against the whole networking industry, but this really is the natural evolution.
As for packetpushers, you'd have to ask the podcast hosts.
Finally, send me an email if you'd like to get in touch with Midokura but can't find their contact details.
I meant I've not seen any other company or open source project which has a virtual router on the hypervisor. And I only found this article yesterday. I can setup routing software on Linux, if Linux is running the hypervisor, but then you have to figure it all out on yourself.