VMware vSwitch does not support LACP
This is very old news to any seasoned system or network administrator dealing with VMware/vSphere: the vSwitch and vNetwork Distributed Switch (vDS) do not support Link Aggregation Control Protocol (LACP). Multiple uplinks from the same physical server cannot be bundled into a Link Aggregation Group (LAG, also known as port channel) unless you configure static port channel on the adjacent switch’s ports.
When you use the default (per-VM) load balancing mechanism offered by vSwitch, the drawbacks caused by lack of LACP support are usually negligible, so most engineers are not even aware of what’s (not) going on behind the scenes.
This is very old news to any seasoned system or network administrator dealing with VMware/vSphere: the vSwitch and vNetwork Distributed Switch (vDS) do not support Link Aggregation Control Protocol (LACP). Multiple uplinks from the same physical server cannot be bundled into a Link Aggregation Group (LAG, also known as port channel) unless you configure static port channel on the adjacent switch’s ports.
When you use the default (per-VM) load balancing mechanism offered by vSwitch, the drawbacks caused by lack of LACP support are usually negligible, so most engineers are not even aware of what’s (not) going on behind the scenes.
Let’s start with the simplest possible topology: an ESX server connected to a switch with two parallel links. Ideally, the two parallel links would be placed in a LAG, or one of them would be blocked by STP. As vSwitch supports neither LACP nor STP, both links are active and forwarding loops in the network are prevented by vSwitch’s split horizon switching.
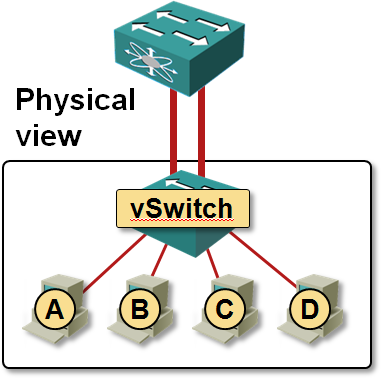
The upstream switch is not aware that the two parallel links terminate in the same physical device. It considers them connected to two separate hosts (or switches) and uses the standard source-MAC-address-based learning to figure out how to forward data to virtual machines A-D. Assuming that the VMs A and B use the first uplink and C and D use the second one, the switch builds the following view of the network in its MAC address table:

The split view of the ESX server is not a bad idea as long as the vSwitch performs per-VM load balancing – MAC address table is stable and all traffic flows are symmetrical; the only drawback is limited load balancing capability – a single VM can never use both links.
Do we really need static LAG?
The behavior of our small network becomes more erratic if we enable IP-hash-based load balancing on the vSwitch. All of a sudden the same source MAC address starts appearing on both links (the same VM can use both links for different TCP or UDP sessions) and the MAC address table on the switch becomes “somewhat” more dynamic.
VMware recommends enabling static LAG on the switch in combination with per-session vSwitch load balancing. This recommendation makes perfect sense, as it prevents MAC address table trashing, but it also disables detection of LAG wiring/configuration errors.
Update 2011-01-26 (based on readers’ comments)
Without synchronized ESX-switch configuration you can experience one of the following two symptoms:
- Enabling static LAG on the physical switch (pSwitch), but not using IP-hash-based load balancing on vSwitch: frames from the pSwitch will arrive to ESX through an unexpected interface and will be ignored by vSwitch. Definitely true if you use active/standby NIC configuration in vSwitch, probably also true in active/active per-VM-load-balancing configuration (need to test it, but I suspect loop prevention checks in vSwitch might kick in).
- Enabling IP-hash-based load balancing in vSwitch without corresponding static LAG on the pSwitch: pSwitch will go crazy with MACFLAP messages and might experience performance issues and/or block traffic from the offending MAC addresses (Duncan Epping has experienced a nice network meltdown in a similar situation).
More information
Interaction of vSwitch with link aggregation is just one of many LAG-related topics covered in my Data Center 3.0 for Networking Engineers webinar (buy a recording or yearly subscription).
http://kb.vmware.com/kb/1001938
http://www.yellow-bricks.com/2010/08/06/standby-nics-in-an-ip-hash-configuration/
If you're using vSphere 4.1 and a distributed vSwitch, you might also be in the Load Based Teaming option, http://kb.vmware.com/kb/1022590.
Cheers,
-Loren
Thank you for all the links. They give interesting insight into how vSwitch actually works, but the fundamental question remains: what happens (apart from MAC table trashing in the pSwitch) if you enable "IP-hash-based" LB in vSwitch but do not configure the EtherChannel on the pSwitch.
I wish that you could do port-security on etherchannels so that you can limit MACs to some reasonable number and sticky MAC learning to prevent MAC thrashing.
While we're in the neighborhood I'd like to remind everyone that you can run the port-channel hash with the 'test etherchannel load-balance interface' command. Fun.
Something funny happened - sorry if this shows up as a double post.
"Are you aware of the specific drawbacks of using per-session load balancing without static LAG on the switch?"
You're not suggesting that someone would run this way, ignore the "MAC is flapping" messages and let the CAM table thrash, are you?
Some Cisco platforms will drop frames for "flapping" destinations each time that message is logged. It's a loop prevention thing: don't forward frames that might loop endlessly.
The duration of the drop interval is in the tens of seconds each time the "flap" threshold (moves/interval) is exceeded.
Frustratingly, exactly what constitutes a "flap", whether traffic is dropped and for how long is platform and OS dependent.
Static LAG (channel-group X mode on) comes with its own set of drawbacks, of course. There are ways for things to go wrong that LACP would notice, but "on" will not.
I did not know what exactly the reaction to CAM table trashing would be (never tested it in the lab) and you provided just the answer I needed. Thank you!
I have the idea that programming TCAM is an expensive operation. Expensive relative to moving frames around anyway. I don't think it's something you want the switch to be doing thousands of times per second. :-)
...Never mind the logging overhead it creates.
I opened a TAC case a few years ago to find out exactly what constitutes "a flap". The answer was: "what platform?"
After a little digging, TAC replied:
------------------------------
The host flapping detection behavior is somewhat different between Cat4k
CatOS and Cat4k IOS. The big difference between Cat4k CatOS and Cat4k IOS
is, in CatOS, the cat4k drops traffic from the flapping host for
approximately 15 seconds. In IOS, the cat4k does not drop traffic because
of host flapping.
Both Cat4k CatOS and IOS use the following algorithm to declare a host
flapping:
If the supervisor see 4 or more moves between ports from a single source mac
in a window of around 15 seconds, then it declares the host to be flapping.
------------------------------
Assuming vPC/VSS/SMLT style MLAG isn't available, can the traditional vSwitch create two "IP-hash" aggregations to two different switches?
We'd need the vSwitch algorithm to do split-horizon bridging between two uplink bundles, and then do IP-hash link selection within these "mode on" aggregations.
If this sort of scheme isn't possible, then "IP-hash" balancing suggests that you can only have a single access switch for an ESX server. Not very resilient!
And no, a vSwitch cannot create two LAGs to different switches...that's been on my wishlist for a couple years now...
If you do this on the vswitch with the Service Console interface, the ESX host will likely become unmanageable via the network and you'll have to console into it to fix things.
There is no LACP in vSwitch, but it does have something that resembles static LAG.
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1004048
http://www.cisco.com/en/US/docs/solutions/Enterprise/Data_Center/vmware/VMware.html
VMware supports static LAG (or EtherChannel or Port Channel), but not LACP.
So my question may be redundant, but is this why when looking at the port statistics of the LAG group on a 48 port DGS-1210-48 switch, one of the members of the LAG group (2 intel nics on a Dell Vmware server) is receiving and transmitting, while the 2nd member is ONLY transmitting packets? Is this because the MAC address of the virtual vswitch can really only be assigned to one of the nics?
The vSwitch is set to Load Balance, route based on ip hash. The switch's LAG configuration is static. If we set it to LACP, we lose connection to the internal VMs. A third nic keeps us connected to the management interface.
Luke
Also, just because you have a LAG on the switch doesn't mean that the switch won't do load balancing solely based on destination MAC address (or a combination of source+destination MAC).
Hope this helps
Ivan