External Brains Driving an MLAG Cluster
Juniper has introduced an interesting twist to the Stacking on Steroids architecture: the brains of the box (control plane) are outsourced. When you want to build a virtual chassis (Juniper’s marketing term for stack of core switches) out of EX8200 switches, you offload all the control-plane functionality (Spanning Tree Protocol, Link Aggregation Control Protocol, first-hop redundancy protocol, routing protocols) to an external box (XRE200).
The resulting architecture is very similar to Cisco’s VSS, the major difference being that the internal routing engine in an EX8200 participating in a virtual chassis performs only the most rudimentary functions (chassis/linecard monitoring and maintenance).
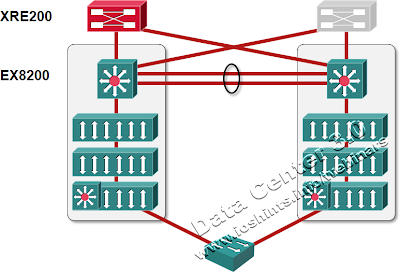
Juniper MLAG cluster with an external control plane
Theoretically you could scale the virtual chassis architecture to numerous EX8200 switches behaving like a single data center fabric. From that perspective, the virtual chassis approach is way better than Cisco’s VSS (which still looks like a hack to me). In reality, only two EX8200-series switches can be joined initially, making the virtual chassis a more expensive hack than the VSS (not only are you lobotomizing one supervisor module, you have to buy two more and lobotomize three out of four).
The Nasty Details
Not surprisingly, Juniper’s white paper1 is full of not-so-subtle hints comparing virtual chassis with VSS. For example: if the inter-switch link (Juniper’s term: intra-chassis link) goes down, you don’t lose half of your switching capacity (like you do with VSS). What they forget to mention is that the most common reason you’d lose a well-designed inter-switch link implemented as a port channel of multiple 10Gb connections terminated on different linecards is the failure of the supervisor module (in which case half of your switching capacity is dead anyway).
Furthermore, losing the inter-switch link between two Catalysts in a VSS system is equivalent to losing all the connections between the left- and right-hand sides in the above diagram, in which case the virtual chassis is at least as brain-dead as VSS (the whitepaper is curiously mum about that scenario). Another omission: when you lose the intra-chassis link between two EX8200 switches, hosts connected only to the left-hand switch (most probably) can no longer talk to hosts connected only to the right-hand switch.
Last but not least, when trying to compare apples to apples (which you can never expect a marketing whitepaper to do), we should also consider the extra power supplies, fans and other infrastructure needed in the XRE200 boxes.
Speaking of marketing misdirections, the EX8200 Virtual Chassis Technology “fact sheet” has some “excellent” FUD:
[virtual chassis behavior at inter-switch link loss] is a significant advancement over other vendors’ solutions, where the loss of the intra-chassis link leads to complete loss in connectivity between any nodes (access switches or core routers) interconnected via the aggregation layer.
If you’re unsure why that’s a bogus claim, maybe it’s time to watch the Data Center 3.0 for the Networking Engineers webinar ;)
Summary
Due to the current limitations, the virtual chassis offers no clear advantages over Cisco’s VSS or vPC solutions. However, the architecture (clean separation between control and data planes with numerous redundant paths between them) looks promising and once they manage to implement a reliable system beyond the two chassis, it might be an interesting solution.
Revision History
- 2022-05-08
- Cleanup
-
No longer available on Juniper’s web site, probably for a number of good reasons ;) ↩︎
What about MLAG on Cisco Nexus platform (vPC) where both control planes remain awake?
Do all fears remain or that idea is step forward?
Depending on the type of Ethernet frame arriving on the incoming interface of the switch the hashing is done in 2 different ways:
a/ If the packet is non IP, the hashing is done on src and dst MAC
addresses (for example FCoE snooped traffic ) , check also how many bits of the MAC address are really taken for the hash
b/ If the packet is IP, the hashing is done only on the L3 and L4 fields:
- IP Source Address
- IP Dest Address
- Src Port (L4 SrcPort)
- Src Dest (L4 DstPort)
Sometimes you can run into some performance degradation issues if the flows are not varying enough on the mentioned above values.
do u know what happen if XRE200 is failure. I can not find any failure scenario document about this like cisco vss white paper in juniper. Juniper just recommend two XRE200 for HA, but not as a requirement. So if just equipped ONE XRE200 in virtual chassis, what happen with these two chassises? one still active and another become dead to prevent loop or .......?
"Furthermore, losing the inter-switch link between two Catalysts in a VSS system is equivalent to losing all the connections between the left- and right-hand sides in the above diagram, in which case the virtual chassis is at least as brain-dead as VSS "
also your folllowing observation is not entirely correct at least for the XRE:-
"not only are you lobotomizing one supervisor module, you have to buy two more and lobotomize three out of four"
Juniper VC comes with a lot of HA features like GRES(graceful RE switchover),NSR(non-stop routing) and NSB (non-stop bridgiging) which gives you near hitless data convergence during RE failures and ISSU, the NSR and NSB features are implemented by running the same daemons responsible for routing,bridging snooping and other features parallely on the backup xre and syncing the kernel periodically with the master, so in case of a xre switchover you have all the protocol states intact in the backup which then takes over seamlessly & masks this transition to its peers, so replicating and concurrently running the daemons on the backup XRE isnt exactly same as lobotomizing it
also w.r.t to your observation:-
" once they manage to implement a reliable system beyond the two chassis, it will be a truly interesting solution." i would like you to know that the VC has been succesfuly tested with 4 members and is currently being tested with 8 members
#2 - "Lobotomizing supervisors": I see your point. It would be interesting to compare that with NSF from Cisco (VSS). Any good comparison documents or technical deep dive?
#3 - I know the 4-chassis solution is supported now (thanks for pointing that out). That will be covered in the upcoming update to the Data Center Fabric Architectures webinar.
#1 - w.r.t the missing link we should note that there are now 2 different points of failure i.e 1. "the direct link b/w the xres that is only for control traffic" & 2. the intra chassis lag link b/w the chassis that is for both control+data traffic, hence for the failure you initialy pointed out to happen both these points should fail at the same time, if only the missing link fails the xres could still sync with each other through the intra chassis link, when the intra chassis link fails in which case data traffic cannot move across chassis both xres would still be in sync so only traffic that has to be switched across chassis is affected not the traffic that has ingress/egress on same cahssis
#1-1: also with the 4 chassis implementation the intra chassis links can be fully meshed b/w each of
the members therby providing multiple redundant intra chassis path
#2 - w.r.t NSF i dont know much about it but AFAIK it still doesnt concurrently run the exact same
daemons on both the master and backup and hence it needs the help of NSF aware (cisco) neighbors to maintain or rather rebuild the protocol states whereas the forwarding states are maintained, plz correct me on this if i am mistaken. in case of Juniper HA the backup RE is exactly running the same processes as the master and hence there is no need for repopulating RIB or anything and the forwarding states that are maintained in the Kernel are synced across the master and backup, the PFE (packet forwarding engine) on the LC keeps forwarding the packets hitlessly in case there is no protocol triggered change during the switchover, so you actually get a 0(zero) packet drop scenario when there is no protocol triggered changes happening during switchover.
#2-2 Also the major difference here is that the Juniper HA mechanism is local to the system and doesnt need any awareness capability from peer , the peer can be any system be it Cisco, Juniper or HP