Blog Posts in November 2010
FCoE between data centers? Forget it!
Was anyone trying to sell you the “wonderful” idea of running FCoE between Data Centers instead of FC-over-DWDM or FCIP? Sounds great ... until you figure out it won’t work. Ever ... or at least until switch vendors drastically increase interface buffers on the 10GE ports.
FCoE requires lossless Ethernet between its “routers” (Fiber Channel Forwarders – see Multihop FCoE 101 for more details), which can only be provided with Data Center Bridging (DCB) standards, specifically Priority Flow Control (PFC). However, if you want to have lossless Ethernet between two points, every layer-2 (or higher) device in the path has to support DCB, which probably rules out any existing layer-2+ solution (including Carrier Ethernet, pseudowires, VPLS or OTV). The only option is thus bridging over dark fiber or a DWDM wavelength.
VMware Virtual Switch: no need for STP
During the Data Center 3.0 webinar I always mention that you can connect a VMware ESX server (with embedded virtual switch) to the network through multiple active uplinks without link aggregation. The response is very predictable: I get a few “how does that work” questions in the next seconds.
VMware did a great job with the virtual switch embedded in the VMware hypervisor (vNetwork Standard Switch – vSS – or vNetwork Distributed Switch – vDS): it uses special forwarding rules (I call them split horizon switching, Cisco UCS documentation uses the term End Host Mode) that prevent forwarding loops without resorting to STP or port blocking.
Cisco IOS Login Enhancements are not IPv6-aware
One of the comments to my “IPv6 in Data Center: after a year, Cisco is still not ready” post included the following facts:
Up through at least 15.0(1)M and 12.2(53)SE2 the IPv6 support for management protocols is spotty; syslog is there, SNMP traps and the RADIUS/TACACS control plane aren't.
Another bug along the same lines was discovered by Jónatan Jónasson: When the Cisco IOS Login Enhancements feature logs successful or failed login attempt, it reports the top 32 bits of the remote IPv6 address in IPv4 address format. Here’s a sample printout taken from a router running IOS release 15.0(1)M.
P#
%SEC_LOGIN-5-LOGIN_SUCCESS: Login Success [user: test]
[Source: 254.192.0.0] [localport: 23] at ...
P#who
Line User Host(s) Idle Location
* 0 con 0 idle 00:00:00
2 vty 0 test idle 00:00:06 FEC0::CCCC:1
It looks like the recommendation we’ve been making two years ago is still valid: use IPv4 for network management.
Content over IPv6: No Excuses!
Yesterday I spent the whole day at another fantastic IPv6 Summit organized by Jan Žorž of the go6 institute. He managed to get two networking legends: Patrik Fältström (he was, among numerous other things, a member of Internet Architecture Board) had the keynote speech (starts @ 11:40) and Daniel Karrenberg (of the RIPE fame) was chairing the technical panel discussion. My small contribution was a half-hour talk on the importance of IPv6-enabled content (starts @ 37:00).
IPv6 in Data Center: after a year, Cisco is still not ready
Today I’m delivering another IPv6 presentation, this time at the 4th Slovenian IPv6 Summit organized by tireless Jan Žorž from the go6 Slovenian IPv6 initiative. It’s thus just the right time to review the post I wrote a bit more than a year ago about lack of IPv6 readiness in Cisco’s Data Center products. Let’s see what has changed in a year:
Time-Based Static Routes
Before someone accuses me of being totally FCoE/DCB-focused, here’s an interesting EEM trick. Damian wanted to have time-dependent static routes to ensure expensive backup path is only established during the working hours. I told him to use cron with EEM to modify router configuration (and obviously lost him in the acronym forest)... but there’s an even better solution: use reliable static routing and modify just the track object’s state with EEM.
Confusopoly
Undoubtedly Scott Adams is following the Cisco/Brocade FCoE/QCN/TRILL "discussions".

FCoE, QCN and Frame Relay analogies
Just when I hoped we were finally getting somewhere with the FCoE/QCN discussion, Brocade managed to muddy the waters with its we-still-don’t-know-what-it-is announcement. Not surprisingly, networking consultants like my friend Greg Ferro of the Etherealmind fame responded to the shenanigan with statements like “FCoE ... is a technology so mindboggingly complicated that marketing people can argue over competing claims and all be correct.” Not true, the whole thing is exceedingly simple once you understand the architecture (and the marketing people always had competing claims).
Pretend for a minute that FC ≈ IP and LAN bridging ≈ Frame Relay, teleport into this parallel universe and allow me to tell you the whole story once again in more familiar terms.
Nexus 1000V: another IPv6 #FAIL
Just stumbled across this unbelievable fact in the Nexus 1000V release notes:
IPV6 ACL rules are not supported.
My first reaction: “You must be kidding, right? Are we still in 20th century?” ... and then it dawned on me: Nexus 1000V is using the NX-OS control plane and it’s still stuck in 4.0 release which did not support IPv6 ACLs (IPv6 support was added to NX-OS in release 4.1(2)).
Does FCoE need QCN (802.1Qau)?
One of the recurring religious FCoE-related debates of the last months is undoubtedly “do you need QCN to run FCoE” with Cisco adamantly claiming you don’t (hint: Nexus doesn’t support it) and HP claiming you do (hint: their switch software lacks FC stack) ... and then there’s this recent announcement from Brocade (more about it in a future post). As is usually the case, Cisco and HP are both right ... depending on how you design your multi-hop FCoE network.
Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
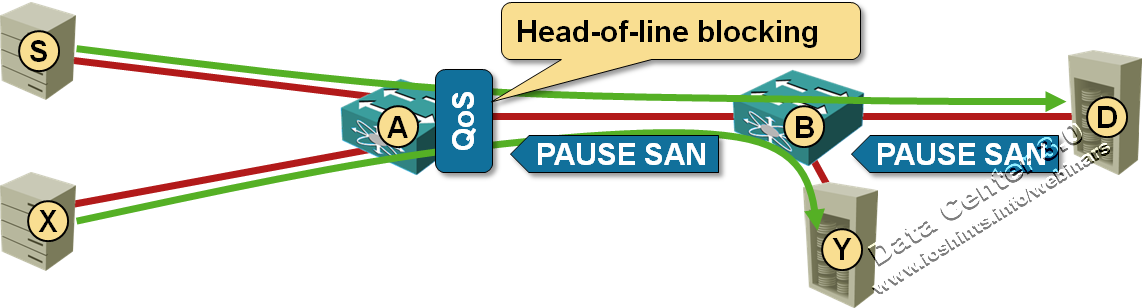
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.
… updated on Sunday, December 27, 2020 17:54 UTC
vCloud Disruptiveness: Nothing New
The vCloud Director: hand the network over to server admins post received several fantastic well-reasoned comments that you should read in their entirety. Jónatan Natti correctly pointed out (among other things) that we’ve often heard “And now a networking vendor is trying to persuade people with limited exposure to […] issues to rebuild […]" where […] could stand for Voice/PBX, SNA or storage.
Update 2020-12-27: The original blog post was written in 2010 when vCloud Director and the weird MAC-in-MAC encapsulation it used was all the craze in some circles (and in particular in vendor slide decks).
The hype I was making fun of didn’t last long. The encapsulation quickly got replaced by VXLAN, the whole product died a few years later, and now VMware NSX-T and VMware on AWS are the new miracle technologies.
DHCP the Microsoft way: almost standard
Srinivas sent me the following printout a few days ago and asked me whether I could explain the weird DHCP bindings (I removed the lease expiration column from the printout):
Switch#sh ip dhcp binding
Bindings from all pools not associated with VRF:
IP address Client-ID/ Type
Hardware address/
User name
192.168.101.140 0152.4153.2000.188b. Automatic
cfb7.f800.0000.0000.
00
192.168.101.141 0152.4153.2000.188b. Automatic
cfb7.f800.0001.0000.
00
vCloud Director: hand the network over to server admins
A few months ago VMware decided to kick away one of the more stubborn obstacles in their way to Data Center domination: the networking team. Their vCloud architecture implements VLANs, NAT, firewalls and a bit of IP routing within the VMware hypervisor and add-on modules ... and just to make sure the networking team has no chance of interfering, they implemented MAC-in-MAC encapsulation, making their cloudy dreamworld totally invisible to the lowly net admins.
VPLS is a technology, not just a service provider offering
The Internet Exchange and Peering Points Packet Pushers Podcast is as good as the rest of them (listen to it first and then continue reading), but also strangely relevant to the data center engineers. When you look beyond the peering policies, route servers and BGP tidbits, an internet exchange is a high-performance large-scale layer-2 network that some data center switching vendors are dreaming about ... the only difference being that the internet exchanges have to perform extremely well using existing products and technologies, not the shortest-path-bridging futures promised by the vendors.
IPv6 Addressing: How Wrong Can You Get It?
Mike was wondering whether his ISP is giving him what he needs to start an IPv6 pilot within his enterprise network. He wrote:
So I got an IPv6 assignment with a /120 mask (basically our IPv4/24 network mapped to IPv6) and two smaller networks to use for links between our external router and the ISP.
Dear Mike’s ISP: where were you when the rest of the world was preparing to deploy IPv6? Did you read IPv6 Unicast Address Assignment Considerations (RFC 5375) or IPv6 Address Allocation and Assignment Policy from RIPE or your regional registry?
Solving the MPLS/VPN QoS Challenge
Two weeks ago I wrote about the challenges you’ll encounter when trying to implement end-to-end QoS in an enterprise network that uses MPLS/VPN service as one of its transport components. Most of the issues you’ll encounter are caused by the position of the user-SP demarcation point. The Service Providers smartly “assume” the demarcation point is the PE-router interface… and everything up to that point (including their access network) is your problem.
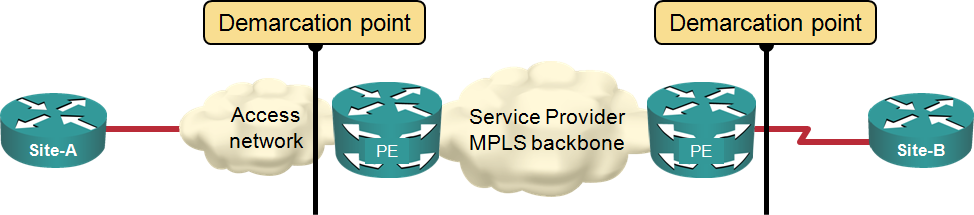
Typical MPLS/VPN demarcation point
What is MPLS-TP and is it relevant?
At the time when I was writing my MPLS books and developing MPLS courses for Cisco, everyone was ecstatically promoting GMPLS (Generalized MPLS) as the next unifying technology of everything, making someone so fed up with the fad that he wrote the Electricity over IP RFC.
GMPLS got implemented in high-end routers, but never really took off (at least I’ve never seen or even heard about it). Obviously the transport teams found the idea of routers requesting on-demand lambdas with IP-based protocols too hard to swallow.
External Brains Driving an MLAG Cluster
Juniper has introduced an interesting twist to the Stacking on Steroids architecture: the brains of the box (control plane) are outsourced. When you want to build a virtual chassis (Juniper’s marketing term for stack of core switches) out of EX8200 switches, you offload all the control-plane functionality (Spanning Tree Protocol, Link Aggregation Control Protocol, first-hop redundancy protocol, routing protocols) to an external box (XRE200).