Long-distance vMotion and the traffic trombone
Few days ago I wrote about the impact of vMotion on a Data Center network and the traffic flow issues. Now let’s walk through what happens when you move a running virtual machine (VM) between two data centers (long-distance vMotion). Imagine we’re moving a web server that is:
- Serving a few Internet clients (with firewall/NAT and/or load balancing somewhere in the path);
- Getting most of its data from a database server sitting nearby;
- Reading and writing to a local disk.
The traffic flows are shown in the following diagram:
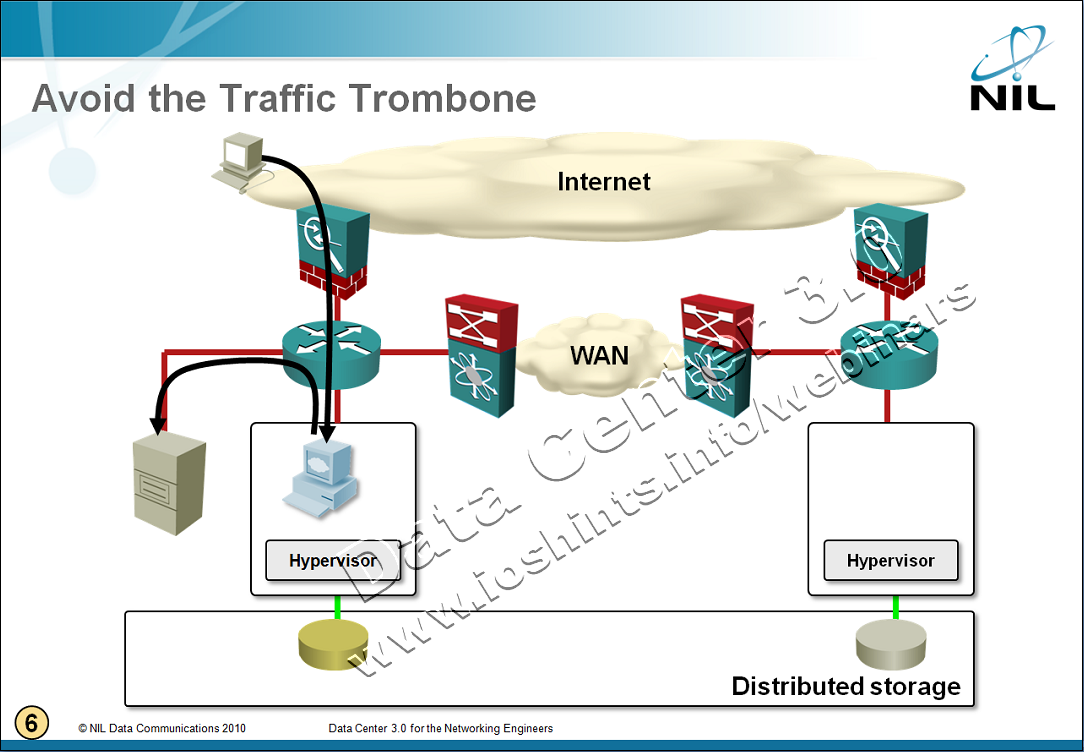
After you move the VM, its sessions remain intact. The traffic to/from the Internet still has to pass through the original firewall/load balancer (otherwise you’d lose the sessions) and the database traffic is still going to the original database server (otherwise the web applications would generate “a few” database errors).
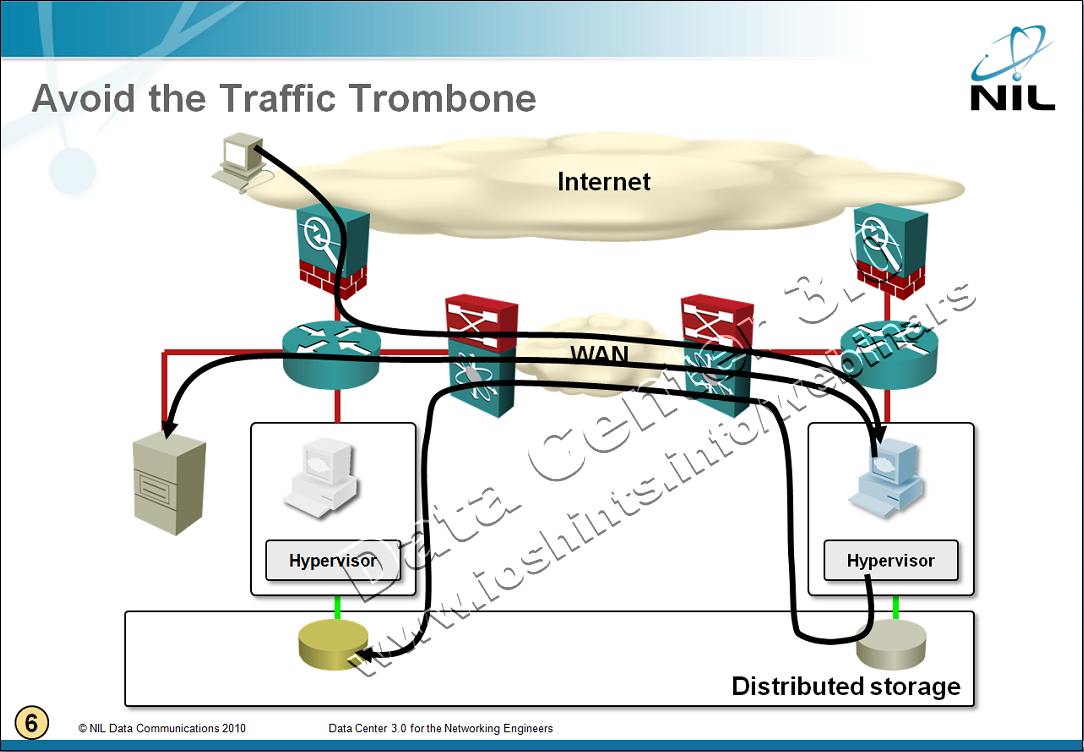
Even worse, in many cases all disk write requests generated by the VM would have to go back to the primary data center. The resulting traffic flow spaghetti mess was aptly named the traffic trombone by Greg Ferro.
Notes
- Storage vMotion can be used to transfer the virtual disk file to another logical disk (LUN) with a primary copy in the second data center, effectively localizing the SAN traffic.
- (Speculative) SAN write requests might be quickly optimized if the virtual disk file (VMDK) is stored in a truly distributed NFS store (as opposed to active/standby block storage).
To give you a real-world (actually a lab) example: Cisco and VMware published a white paper describing how they managed to move a live Microsoft SQL server to a backup data center ... resulting in ~15% performance degradation and unspecified increase in WAN traffic.
What do you think?
Now that you know what’s behind the scenes of long-distance vMotion, please tell me why it would make sense to you and where you’d use it in your production network ... or, even better, what business problems are your server admins trying to solve with it.
Oh, and I simply have to mention the Data Center 3.0 for Networking Engineers webinar, it’s full of down-to-earth facts like this one (buy a recording or yearly subscription).
For all versions, except ESXi 5.0 Enterprise Plus, the limit of vMotion is maximum 5 ms roundtrip time between the hosts. With the Enterprise + license the limit is increased to 10 ms.
UNREAL TOURNAMENT EXTREME H.A.!!!!!111 ;)
(Depending on the firewall / load balancer requirements, this scenario may also require some amount of virtualization in the network infrastructure to ensure firewalling / LB state is shared among both sites.)
However, the current routing protocols are too slow (the convergence would take a few seconds unless you want to tweak OSPF really badly) and we lack a mechanism to detect host movement reliably - we would need L3 functionality in the vSwitch or some other registration mechanism.
Obviously there's no L3 switching in the vSwitch or NX1K and even if it would be there, it would eat CPU cycles as it would have to participate in the routing protocol.
All other migration factor are subject to discussion, with management and control plane overhead being among the main show-stoppers.