TRILL and 802.1aq are like apples and oranges
A comment by Brad Hedlund has sent me studying the differences between TRILL and 802.1aq and one of the first articles I’ve stumbled upon was a nice overview which claimed that the protocols are very similar (as they both use IS-IS to select shortest path across the network). After studying whatever sparse information there is on 802.1aq and the obligatory headache, I’ve figured out that the two proposals have completely different forwarding paradigms. To claim they’re similar is the same as saying DECnet phase V and MPLS Traffic Engineering are similar because they both use IS-IS.
TRILL forwarding
Within the backbone, TRILL is a true layer-3 protocol: TRILL header has a hop count, RBridges have layer-3 addresses and the layer-2 header changes as the packet is propagated across the backbone. Even though TRILL still retains the bridging paradigm at the edges, its core properties ensure it behaves like any other (well designed) L3 protocol.
As you can see in the diagram, once the ingress RBridge receives the end-user’s MAC frame, the frame is encapsulated in a layer-3 TRILL header with layer-3 addresses of ingress and egress RBridge. The TRILL datagram gets a new MAC header, which is changed every time the packet is forwarded by an RBridge; the layer-3 addresses in the TRILL header obviously stay unchanged, just the hop count is decreased.
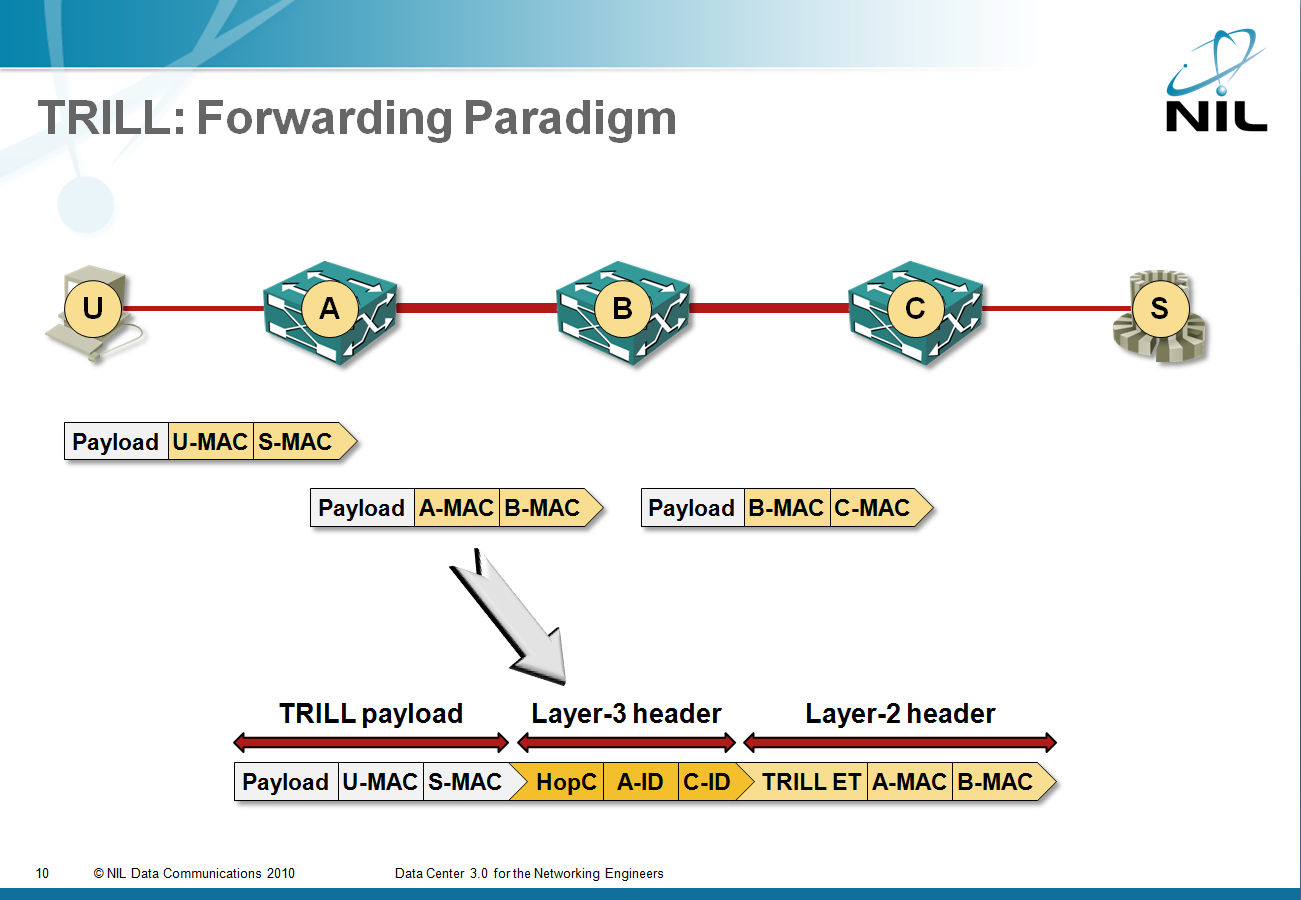
Benefits: a layer-3 protocol has numerous advantages over a layer-2 protocol; read my “Bridging and Routing: is there a difference?” and “Bridging and Routing, Part II” posts.
Drawbacks: TRILL cannot be implemented with those existing (low-cost) ASICs that are hard-coded to support only 802.1ad and 802.1ah. It can be implemented, however, with any forwarding architecture that is generic enough to be able to insert and remove L2/L3 headers on ingress/egress points and swap L2 headers and modify L3 headers while forwarding the datagrams.
802.1aq forwarding
802.1aq is actually a modified way of populating the bridging FIB (Forwarding Information Base), while the forwarding paradigm stays unchanged. 802.1aq can use 802.1ad (Q-in-Q) forwarding or 802.1ah (Provider Backbone Bridging or MAC-in-MAC) forwarding. I sincerely hope nobody will implement Q-in-Q forwarding (SPBV), as it’s a total confusion (on the other hand, troubleshooting that would be excellent job security), so let’s focus on MAC-in-MAC forwarding (SPBM).
The ingress PBB (Provider Backbone Bridge) takes the user’s MAC frame and encapsulates it in 802.1ah MAC frame. The destination MAC address in the 802.1ah MAC frame is the egress PBB and there’s no hop count that can be used to detect loops (or allow the network operator to traceroute across the network). The new frame is bridged across the 802.1aq backbone; because the FIB building mechanisms are modified, the backbone is no longer limited to a single spanning tree (which makes 802.1aq different from 802.1ah). Throughout the backbone forwarding process, the frame is unchanged (and the destination MAC address remains the address of the egress PBB).
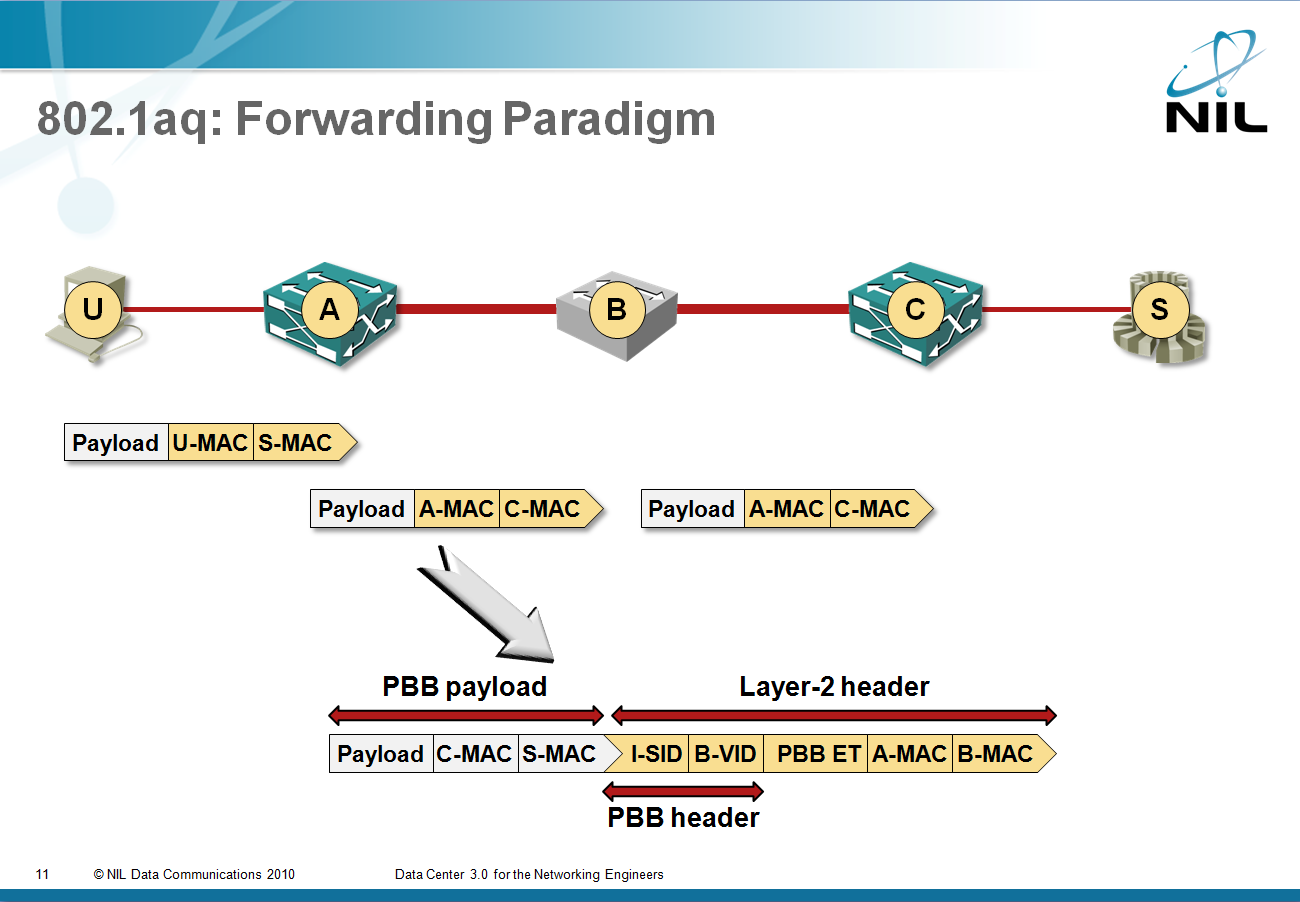
Benefits: 802.1aq can use existing ASICs
Drawbacks: 802.1aq has no relation to routing and none of the routing functionality. A loop generated by the control-plane protocol (for example, due to buggy implementation or distributed nature of IS-IS computations) can cause a network meltdown.
Cisco FabricPath
According to the comment Brad made, the current FabricPath implementation does not change MAC header on every hop, so it seems to be aligned with the 802.1aq framework. Please allow me to refrain from commenting what this really means for the marketing claims about FabricPath.
And, last but not least, if you’d like to know more about L2/L3 switching in Data Center and emerging DC technologies, watch my Data Center 3.0 for Networking Engineers webinar (buy a recording or yearly subscription).
Based on control-plane being loop free once it converged, all paths in a stable domain are loop-free by the virtue of the routing protocol that created them. However, unstable domain will surely create flooding problems, unless they implement some special ordered FIB programming to overcome transient loops.
* Loops are always a forwarding-plane phenomena (usually generated by control plane).
* Permanent control-plane-generated loops are not possible with a bug-less single area link-state routing domain.
* Temporary loops could arise during the network convergence phase.
Temporary loops are a fact of life in a distributed forwarding network with asynchronous computation. The question is: how do you detect them and deal with them and whether they affect the network performance.
It's impossible for an outsider to evaluate this question in the 802.1aq domain, as the drafts are well-hidden behind the paywall.
Forwarding plane loops normally form in two cases: when you overlay routing over a physical topology, i.e. when routing protocol is not completely aware of the underlying link level mesh or when you implement route summarization, hiding specific routing information.
It is worth making a definition: control plane loop is formed when the same routing prefix (used to create a forwardin entry) comes back to the domain of origin. It is possible to detect these loops using control-plane mechanisms (path-tracing). Forwarding plane loops appear when routers do not have *consistent* view of the topology, e.g. due to summarization, reconvergence, hiding suboptimal paths etc, but not loops in routing information distribution. This distinction is important because control plane loops are detectable in advance, while forwarding loops are not.
In case of the above BGP example, the forwarding plane loop is a result of full-mesh reduction and information minimization in route reflectors. Like said before, the forwarding plane loops are much harder to detect in advance, and therefore a data-plane mitiation mechanism is highly recommended.
It is possible to completely avoid the forwarding plane loops by ensuring that forwarding information is always consistent among all forwarders. For example EIGRP achieves this by engaging every node in the topology in duffusing computation upon a change. BGP route reflectors could be made loop-free by using tunneling techniques, such as MPLS, which avoids BGP-based forwarding decision on core routers.
As for bashing PBT for the lack of TTL label, it is curious to recall how Cell-Mode MPLS was operating (or even ATM separately). Lacking the support for the TTL field as well, both technologies were able to function "perfectly", thanks to the fact that signaling protocols had full topology information and were able to detect control plane loops (e.g. by using path-vector TLV in LDP). Cell Mode MPLS was based on ordered LDP control mode, which allowed for proper ("source-routed") forwarding path establishment upon a topology change. This prevented temporary IP forwarding tables inconsistencies from affecting cell-based pre-built paths. In the same manner, ATM was using pre-signaled source-routed SVCs, not to mention that PNNI was link-state at every level of hierarchy, thus allowing for full topology awareness.
I haven't looked into 802.1aq specs in depth by any means, but if the forwarding paths are somehow programmed by edge nodes (e.g. by building distribution trees based on link-state information), then forwarding loops could be fully eliminated in the same manner as described above. But I can't make any other comments on that until some thorough reading.
Of course, from a vendor standpoint a new hardware revenue stream (e.g. Nexus vs 6500) is more attractive compared to a simple control plane upgrade for the customers :) Using SPBV allows for completely preserving existing forwarding plane and hence the hardware; SPBM requires proper handing of stacked MAC addresses in the edge devices, which could be challenging for existing hardware (though I can't be sure here). If only IEEE wasn't that slow and rigid, they might have delivered something interesting for the data-center switches already.
Interesting to notice how the PBT "legacy" intertwines the with the core ideas of SPB. After all, PBT was originally proposed as a solution that reduces the control plane and replaces it with rich management plane, found in classic transport networks.
To finilize, I'm not saying that flow-based load-balancing is not possible within the 802.1aq framework at all. For example, you may use control plane for distribution of a globally significant hash function used to map flows to the same SPTs. But this does not seem to be in focuse of IEEE group, at least at the moment.
- as if the organisation that is so paranoid about loops that it has hitherto used xSTP would not provide such mechanisms.
The mechanism of SPB exploits the richer knowledge available to nodes with link state, to block under topology change only trees where a node may have "moved" sufficiently wrt its parent and children's last known position that a loop is possible. Such trees are unblocked when the node has regained a synchronised topology view with its neighbours.
- otherwise, in the absence of danger of looping, trees continue to forward during reconvergence,
- preserving this very attractive property of link state.
Nigel Bragg
I understand the underlying reasons for the decision to use Q-in-Q or MAC-in-MAC (reuse existing chipset); only real-life experience will show whether the loop avoidance mechanisms work as expected (and I sincerely hope they do).
You state:
"802.1aq has no relation to routing and none of the routing functionality. A loop generated by the control-plane protocol (for example, due to buggy implementation or distributed nature of IS-IS computations) can cause a network meltdown"
Well, in my opinion, both TRILL and SPBM use IS-IS to populate the forwarding tables and as such both benefit of the advantages of using a link state protocol. Inferring that one is a layer 3 protocol simply because the outer L2 encapsulation changes at every hop or because of the presence of a TTL field, is missing the point.
The fact that one only populates the FIB with the immediate next hop MAC (TRILL) while the other populates the FIB with the final destination node MAC (802.1aq) does not really change the substance of what is being achieved.
As for SPBM being loop prone that is not true. Using a TTL field is not the only way to implement loop suppression; it just happens to be the historical way used with IP. With SPBM the loop suppression is achieved by enforcing RPF (Reverse Path Forwarding) check on the source B-MAC of received frames (which of course is not possible with TRILL since the encapsulation changes at every hop). RPF is nothing new and is in fact used by IP routers when forwarding IP Multicast.
So even if the hypothetical transient loop did form, due to transient asymmetrical reconvergence of the control plane or whatever, TRILL might end up looping packets as many times as the inception value of the TTL field, whereas SPBM would suppress the loops immediately. So in theory SPBM is superior to TRILL on this point; in practice it's just two different approaches to solve the same problem.
John Scaglietti
Thanks for the comment. Since I wrote the post, several people have sent me details on 802.1aq loop avoidance methods and I have to admit it's an amazing work. It looks like the "distributed nature of IS-IS computations" is out of the picture; 802.1aq takes care of that.
I have to study the standard a bit more to figure out the details of the RPF part, but if your forwarding tables are out-of-sync, the RPF check might not help you, as it would rely on incorrect information, resulting in either dropped traffic (that should have been forwarded) or forwarding loops.
So, the question of software bugs remains. TRILL has a belt-and-braces approach (loops induced by the control plane are caught by the data plane), whereas 802.1aq relies solely on correct operation of the control plane.
Would you agree with that?
Ivan
Concerning access to the IEEE documents. You will find that if you simply ask that access to the documents for the purposes of studying/writing about them is easy to obtain. So there is one more step than just grabbing the draft of the IETF server but its not a big deal. Certainly no $$ required. Drop one of us an email and we'll be happy to send interested parties a user id and password/link. Intelligent comments and review are more than welcome.
The above statement about bugs in the control plane being able to cause loops. Actually you need very carefully crafted software to cause loops when RPFC is enabled. That is because you need to actually form TWO loops not just one. There has to be a forward loop AND a simultaneous and overlapping reverse loop. Unless you perfectly line up both loops in space and time data packets cannot loop in either direction.
Basically a packet looping based on the DA has to verify properly against the reverse loop in the SA.
Peter Ashwood-Smith
http://www.ieee802.org/1/files/public/docs2010/aq-ashwood-interop1-1110-v02.pdf
Basically real switches were tested in a topology of 37 devices, 5 real, 32 emulated. Hardware datapaths, equal cost, and OA&M were shown.
We will be doing much more Interop testing in the new Year so stay tuned and we will keep the Wikipedia entry for IEEE 802.1aq up to date as we go.
http://nanog.org/meetings/nanog50/agenda.php
I thought the debate was particularly interesting:
http://nanog.org/meetings/nanog50/presentations/Monday/great_debate_TRILL_vs_802.wmv