Does TRILL make sense at all?
It’s clear that major hypervisor vendors consider MAC-over-IP to be the endgame for virtual networking; they’re still squabbling about the best technology and proper positioning of bits in various headers, but the big picture is crystal-clear. Once they get there (solving “a few” not-so-trivial problems on the way), and persuade everyone to use virtual appliances, the network will have to provide seamless IP transport, nothing more.
At that moment, large-scale bridging will finally become a history (until the big layer pendulum swings again) and one has to wonder whether there’s any data center future for TRILL, SPB, FabricPath and other vendor-specific derivatives.
How large is Large-Scale anyway?
Most customers want to have large-scale bridging solutions to support VM mobility. The current state of the hypervisor market (vSphere 5, June 2012) is as follows:
- 32 hypervisor hosts in a high-availability cluster (where the VMs move automatically based on load changes);
- 350 hosts in a virtual distributed switch (vDS); you cannot move a running VM between two virtual distributed switches, and having hundreds of vSphere hosts with the classic vSwitch is a management nightmare.
The maximum reasonable size of a large-scale bridging solution is thus around 700 10GE ports (I don’t think there are too many applications that are able to saturate more than two 10GE server uplinks).
Assuming a Clos fabric with two spine nodes and 3:1 oversubscription at leaf nodes, you need ~120 non-blocking line-rate 10GE ports on the spine switch (or four spine switches with 60 10GE ports or 16 40GE ports) ... the only requirement is that STP should not block any links, which can be easily solved with multi-chassis link aggregation. There are at least five major data center switch vendors with products matching these requirements.
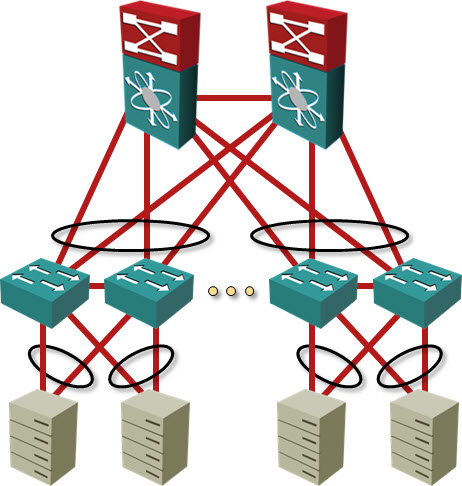
There are scenarios where you really need larger bridging domains (example: link customer’s physical servers with their VMs for thousands of customers); if your data center network is one of them, you should talk to Nicira or wait for Cisco's VXLAN-to-VLAN gateway. On the other hand, implementing large-scale bridging to support stretched HA clusters doesn’t make much sense.
Is there any need for TRILL?
As you’ve seen in the previous section, you can build layer-2 fabrics that satisfy reasonable real-life requirements with leaf-and-spine architecture using multi-chassis link aggregation (MLAG) between leaf and spine switches. Is TRILL thus useless?
Actually, it’s not. Every single MLAG solution is a brittle kludge that can potentially result in a split-brain scenario, and every MLAG-related software bug could have catastrophic impact (VSS or VPC bugs anyone?). It’s much simpler (and more reliable) to turn the layer-2 network into a somewhat-routed network transporting MAC frames and rely on time-proven features of routing protocols (IS-IS in this particular case) to work around failures. From the technology perspective, TRILL does make sense until we get rid of VLANs and move to MAC-over-IP.
TRILL is so awesome some vendors want to charge extra for the privilege to use it
Compared to MLAG, TRILL reduces the network complexity and makes the layer-2 fabric more robust ... but I’m not sure we should be paying extra for it (I’m looking at you, Cisco). After all, if a particular vendor’s solution results in a more stable network, I just might buy more gear from the same vendor, and reduce their support costs.
Charging a separate license cost for TRILL (actually FabricPath) just might persuade me to stick with MLAG+STP (after all, it does work most of the time), potentially making me unhappy (when it stops working). I might also start considering alternate vendors, because every single vendor out there supports MLAG+STP designs.
Server-facing MLAG – the elephant in the room
If your data center runs exclusively on VMware, you don’t need server-facing link aggregation; after all, the static LAG configuration on the switch and IP-based hash on vSphere is a kludge that can easily break.
If you use any other hypervisor or bare-metal servers, you might want to use LACP and proper MLAG to optimize the inter-VM or inter-server traffic flow.
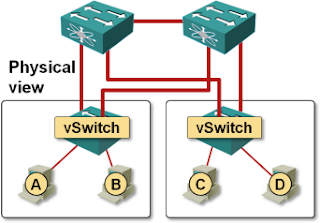
Unfortunately, Brocade is the only vendor that integrated TRILL-like VCS Fabric with MLAG. You can use MLAG with Cisco’s FabricPath, but they’re totally separated – MLAG requires VPC. We haven’t really gained much if we’ve got rid of MLAG on inter-switch links by replacing STP with TRILL, but remained stuck with VPC to support MLAG on server-to-switch links.
Conclusions
Assuming you’re not yet ready to go down the VXLAN/NVGRE path, TRILL is definitely a technology worth considering, just to get rid of STP and MLAG combo. However, be careful:
- Unless you’re running VMware vSphere or other similarly network-impaired operating system that’s never heard of LACP, you’ll probably need multi-chassis LAG for redundancy reasons ... and thus Brocade VCS Fabric is the only option if you don’t want to remain stuck with VPC.
- Even when running TRILL in the backbone, I would still run the full range of STP features on the server-facing ports to prevent potential bridging loops created by clueless physical server or VM administrators (some people actually think it makes sense to bridge between two virtual NICs in a regular VM). Cisco is the only vendor offering TRILL-like fabric and STP in the same product at the same time (while VDX switches from Brocade work just fine with STP, they start pretending it doesn’t exist the moment you configure VCS fabric).
Hmm, seems like there are no good choices after all. Maybe you should still wait a little bit before jumping head-on into the murky TRILL waters.
More information
You know I have to mention a few webinars at the end of every blog post. Here’s the list of the most relevant ones (you get all of them with the yearly subscription)
You touched on something I've been thinking about recently... Cisco hasn't provided any interesting proprietary 'hooks' in the DC environment in several years for mid-sized customers. The only two that come to mind are OTV (ugh) and now LISP. LISP is intriguing, but its also an open technology.
Without a doubt I prefer standards-based technologies, so I shouldn't be complaining. But it will be interesting to see Cisco competing on price in this space. And maybe not great for the industry, if it shrinks Cisco's R&D budget.
Jeremy
Great insights and a wonderful morning read as always.
You specifically mention both Cisco and Brocade in the context of MLAG and STP/TRILL feature support and behaviour; I'm curious if you have any similar reference or insights on Juniper's EX 4200/4500 and their Virtual Chassis.
While I don't believe there is currently anything TRILL-like outside a single VC stack (which under-the-hood is running IS-IS to create a "somewhat-routed network transporting MAC frames", as it were), there is certainly MLAG as well as STP for server/vswitch facing ports.
Curious on your thoughts where (if?) EX fits into the mid to high range DC switching game; QFabric seems to get all the attention but, as you've alluded to a number of times, remains out of reach (or just out of scope) for most.
I believe a combination of EX 4200/4500 VC stacks could be a great fit (price/performance) for the CLOS design you laid out in your first diagram, or another right-sized variant.
There are those of us who will never see or touch FabricPath or QFabric, but still have a keen interest in the options and features available to our market segment and how we can use them effectively to create an effecient, redundant, robust layer 2 switching environment, even if we don't get to call it a "fabric" :)
Cheers!
-Chris
Additionally you can use MLAG between different VC's, i.e. an EX3200/EX4200 Access switch (stack) connected up-to different Core/Agg EX8200 Switches running as a VC.
Alternately you can use the "closed" option being Juniper QFabric based switching (IMO FabricPath is also closed - it won't work with brocade, or anyone else) effectively take a QFX3500 turn it on as a std. switch up-to multiple EX8200's with MLAG, or connect turn it on as a QFabric node and connect it up-to a QFabric Interconnect getting rid of any need to configure protocols.
One other thing I've not seen anyone talking about is MTU in regards to network overlays. I'm curious if anyone has encountered issues with fragmentation when implementing overlay networks and how they have solved these.
BTW krisiasty, a particular nuisance with VPC is that you need a link between the VPC peers. Spine-leaf topologies (clos networks) don't require such connectivity but if you need VPC for say switch-server LAG you'll have to add that VPC peer link.
http://blog.ioshints.info/2011/11/busting-layer-2-data-center.html
http://blog.ioshints.info/2012/03/stretched-layer-2-subnets-server.html
#2 - You have to have jumbo frames in the transport network to run L2-over-IP. There are ways around this requirement (reduce MTU size on vNIC), but you wouldn't want to use them.
I am really enjoying your blog. I have read some of your posts about TRILL, some info from vendors and even the IEEE standard, and there is still one thing I fail to understand. I hope you can provide some light here.
I believe there are two important problems solved with STP: (i) broadcast storms and (ii) deadlock. Broadcast storms (i) are solved in TRILL by using a hop count, so that part is clear. Deadlock (ii) requires network loops to happen (so the STP prevents it), and it is irrelevant on lossy networks such as (classical) Ethernet since frame discarding also prevents it.
However, since TRILL is allowing for loops in the network, how are circular data dependency chains prevented, considering a lossless network (implementing 802.1Qbb, for example) with PAUSE frames? I believe that, in such case, a cycle might arise and the network might get blocked. I really fail to understand how such loops are prevented to happen (and thus block the network). The standard does not mention it at all, and no relevant info is found on the development group documents, vendors info or other sites.
Hope you can give some insight!! Thanks in advance,
Enrique
And no, I haven't seen this problem being addressed in any of the standards.
But assume that, since TRILL allows for multipath forwarding (erm... switching), you employ an alternative topology that does not rely on up-down routing. This is the case of the 2D or 3D torus (e.g., the Infiniband-based 3D torus in the Gordon Supercomputer at SDSC) or a flattened-butterfly (Kim et al, ISCA'07), for example. What do you think about those cases?
Thanks
I am positive the topologies you've mentioned have some interesting implications ... but so does the black hole evaporation ;))
Ivan I think we are talking a lot about vMotion but the "issue" is larger than that. Other than cold moving a VM from one cluster to another and keep its personality (for the reasons Alexander was mentioning) fast forward to where we are going to with this notion of a "virtual data center" (or "software defined data center"). We want to take a shared infrastructure (compute, network, storage) and carve it up into multiple independent entities (which contains virtual instances of those elements) where users can deploy workloads. So there may be some 3,5,10,40 clusters (depending on the size of the company) where you want to carve out those virtual elements and you can't do this if you have network constraints. You need to be able to deploy two workloads on a layer 2 segment and you also need to have the flexibility to allow those two workloads to be deployed one on cluster 3 and the other on cluster 36 (for example).
This has nothing to do with "new applications" type of things. I do agree completely that new workloads, new techniques, new best practices will allow (in the mid-long run) organizations to adapt to a cleaner / more simple L3 approach. This is about trying to fix a problem for "current workloads" that do require legacy techniques/best practices in the short-mid run.
At age 40 I think I won't have a chance to see those "new workloads" going mainstream just to give you a flavor of what I think is the pace the industry is moving. Imagine the opportunity.
Massimo Re Ferre' (VMware).
Deployment automation frameworks (Puppet, Chef etc) are pretty much a requirement for large public cloud deployments too so you would expect these to become mainstream in next couple of years. Once your organisation (the server guys) knows how to do this, there's a lot less need for large scale IP address preservation.
You still need to move VMs, but you can do it in more sensible scale and have network that is simple(r) to deploy and troubleshoot.
Ilja
As far as the 7+ years for Linux... It was circa 1998/1999 when IBM started to back it and it was around for much longer. It is indeed mainstream no doubt about it but it's (still) roughly 1/4th of the traditional Windows legacy market.
I don't know if I can define AWS as mainstream. Probably yes, although if I ask 100 "IT" people over here in Italy what Amazon does most of them would say they sell books online). They seem to be making 1B$ a year on it ... roughly what IBM still make with the AS/400.
Do you see what I mean when I say "opportunity" talking about VXLAN?
Last but not least I divide the world in three geographies: Silicon Valley, US, World.
Depending on where you are and the market you watch you may see different behaviors and what you see mainstream in a GEO it's not mainstream in another ;)
Massimo.
Interesting point about GEOs. On cloud I am assuming that in order to stop AWS et al HP, Dell and everyone else will start selling cloud F2F to companies of all sizes in next couple of years. That will bring rest of the world closer to Silicon Valley.
Additionally to support the vxlan opportunity it has to be said that is somewhat easier to build large L2 fault zone than migrate out of it in most cases. Paint and corner.
Having this said I don't think I am spending all of my career on this. I wouldn't mind working on (even more) leading edge stuff.... but I think it's good not to be too far ahead :)
Massimo.