Category: vMotion
vMotion Enhancements in vSphere 6
VMware announced several vMotion enhancements in vSphere 6, ranging from “finally” to “interesting”.
vMotion across virtual switches. Finally. The tricks you had to use previous were absolutely bizarre.
Is Data Center Trilogy Package the Right Fit to Understand Long Distance vMotion Challenges?
A reader sent me this question:
My company will have 10GE dark fiber across our DCs with possibly OTV as the DCI. The VM team has also expressed interest in DC-to-DC vMotion (<4ms). Based on your blogs it looks like overall you don't recommend long-distance vMotion across DCI. Will the "Data Center trilogy" package be the right fit to help me better understand why?
Unfortunately, long-distance vMotion seems to be a persistent craze that peaks with a predicable period of approximately 12 months, and while it seems nothing can inoculate your peers against it, having technical arguments might help.
vMotion and VXLAN
A while ago I wrote “vMotion over VXLAN is stupid and unnecessary” in a comment to a blog post by Duncan Epping, assuming everyone knew the necessary background details. I was wrong (again).
Migrating a cold VM into a foreign subnet
Moving a running VM into a foreign subnet is Mission Impossible due to stale ARP entries (anyone telling you otherwise is handwaving over a detail or two - maybe their VM doesn't communicate with other VMs in the same subnet), but it's entirely feasible to migrate a cold VM into a foreign subnet if you can fix IP routing. Here's how you can do the trick with Enterasys switches.
Hot and Cold VM Mobility
Another day, another interesting Expert Express engagement, another stretched layer-2 design solving the usual requirement: “We need inter-DC VM mobility.”
The usual question: “And why would you want to vMotion a VM between data centers?” with a refreshing answer: “Oh, no, that would not work for us.”
Long-Distance vMotion, Stretched HA Clusters and Business Needs
During a recent vMotion-over-VXLAN discussion Chris Saunders made a very good point: “Folks should be asking a better question, like: Can I use VXLAN and vMotion together to meet my business requirements.”
Yeah, it’s always worth exploring the actual business needs.
Based on a true story ...
A while ago I was sitting in a roomful of extremely intelligent engineers working for a large data center company. Unfortunately they had been listening to a wrong group of virtualization consultants and ended up with the picture-perfect disaster-in-waiting: two data centers bridged together to support a stretched VMware HA cluster.
Virtualized Squashed Complexity Sausage
Straight from RFC 6670 (section 3.4):
[...] as is usually the case with communications technologies, simplification in one element of the system introduces an increase (possibly a non-linear one) in complexity elsewhere. This creates the "squashed sausage" effect, where reduction in complexity at one place leads to significant increase in complexity at a remote location.
This is probably the most concise description of the great idea of using long-distance vMotion for “mission-critical” craplications, and applies equally well to the kludges used to compensate the simplicity of virtual switches.
Long-Distance Workload Mobility in Perspective
Sometime in 2012, Chuck Hollis described how some of EMC customers use long-distance workload mobility. Not surprisingly, he focused on the VPLEX Metro part of the solution and didn’t even mention the earth-flattening requirements this idea imposes on the network. I guess you already know my views on that topic, but regardless of my personal opinions, he got me curious.
Video: Networking requirements for VM mobility
You’re probably sick and tired of me writing and talking about networking requirements for VM mobility (large VLAN segments that some people want to extend across the globe), but just in case you have to show someone a brief summary, here’s a video taken from the Data Center Fabric Architectures webinar.
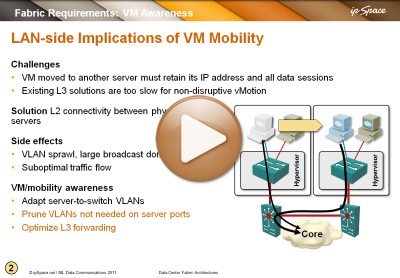
You’ll also find VM mobility challenges described to various degrees in Introduction to Virtual Networking, VMware Networking Deep Dive and Data Center Interconnects webinars
Follow-the-Sun Workload Mobility? Get Lost!
Based on what I wrote about the latency and bandwidth challenges of long-distance vMotion and why it rarely makes sense to use it in disaster avoidance scenarios, I was asked to write an article to tackle the idea that is an order of magnitude more ridiculous: using vMotion to migrate virtual machines around the world to bring them close to the users.
That article has disappeared a long time ago in the haze of mergers, acquisitions and SEO optimizations, so I’m reposting it here:
Long-distance vMotion for Disaster Avoidance? Do the Math First
The proponents of inter-DC layer-2 connectivity (required by long-distance vMotion) inevitably cite disaster avoidance (along with buzzword-bingo-winning business agility) as one of the primary requirements after they figure out stretched clusters might not be such a good idea (and there’s no way to explain the dangers of split subnets to some people). When faced with the disaster avoidance “requirement”, ask them to do some basic math first.
Large-Scale Bridging = Nuked Earth
If you’re not working for a data center fabric vendor, you’ll probably enjoy the excellent analogy Ethan Banks made after reading my TRILL-over-WAN post:
Think of a network topology like a road map. There's boulevards, major junction points, highways, dead ends, etc. Now imagine what that map looks like after it's been nuked from orbit: flat. Sure, we blew up the world, but you can go in a straight line anywhere you want.
... and don’t forget to be nice to the people asking for inter-DC VM mobility ;)
High Availability Fallacies
I’ve already written about the stupidities of risking the stability of two data centers to enable live migration of “mission critical” VMs between them. Now let’s take the discussion a step further – after hearing how critical the VM the server or application team wants to migrate is, you might be tempted to ask “and how do you ensure its high availability the rest of the time?” The response will likely be along the lines of “We’re using VMware High Availability” or even prouder “We’re using VMware Fault Tolerance to ensure even a hardware failure can’t bring it down.”
vSphere 5.0 new networking features: disappointing
I was sort of upset that my vacations were making me miss the VMware vSphere 5.0 launch event (on the other hand, being limited to half hour Internet access served with early morning cappuccino is not necessarily a bad thing), but after I managed to get home, I realized I hadn’t really missed much. Let me rephrase that – VMware launched a major release of vSphere and the networking features are barely worth mentioning (or maybe they’ll launch them when the vTax brouhaha subsides).
Automatic edge VLAN provisioning with VM Tracer from Arista
One of the implications of Virtual Machine (VM) mobility (as implemented by VMware’s vMotion or Microsoft’s Live Migration) is the need to have the same VLAN configured on the access ports connected to the source and the target hypervisor hosts. EVB (802.1Qbg) provides a perfect solution, but it’s questionable when it will leave the dreamland domain. In the meantime, most environments have to deploy stretched VLANs ... or you might be able to use hypervisor-aware features of your edge switches, for example VM Tracer implemented in Arista EOS.