Category: Design
One-Arm Hub-and-Spoke VPN on Arista EOS
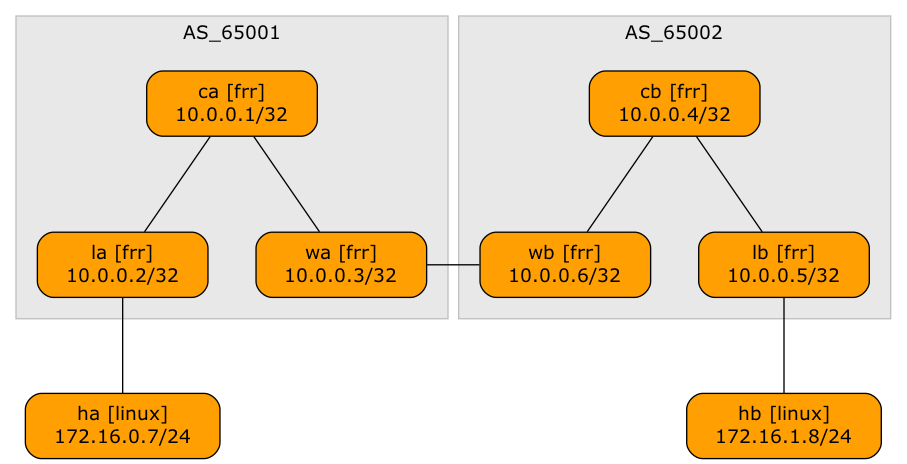
In September 2024, I described how you can build One-Arm Hub-and-Spoke VPN with MPLS/VPN. In that blog post, I mentioned that the solution doesn’t work on Arista EOS because it allocates MPLS labels to whole VRFs (per-VRF label allocation).
In early September, I received an email from Daniel Blažek telling me that Arista fixed this particular annoyance in the EOS release 4.34.2F. It still uses per-VRF label allocation, but now, you can assign a different label to the default route. Let’s see how that works with our one-arm hub-and-spoke topology:
EVPN Designs: Multi-Pod with IP-Only WAN Routers
In the multi-pod EVPN design, I described a simple way to merge two EVPN fabrics into a single end-to-end fabric. Here are a few highlights of that design:
- Each fabric is running OSPF and IBGP, with core (spine) devices being route reflectors
- There’s an EBGP session between the WAN edge routers (sometimes called border leaf switches)
- Every BGP session carries IPv4 (underlay) and EVPN (overlay) routes.
In that design, the WAN edge routers have to support EVPN (at least in the control plane) and carry all EVPN routes for both fabrics. Today, we’ll change the design to use simpler WAN edge routers that support only IP forwarding.
EVPN Designs: Multi-Pod Fabrics
In the EVPN Designs: Layer-3 Inter-AS Option A, I described the simplest multi-site design in which the WAN edge routers exchange IP routes in individual VRFs, resulting in two isolated layer-2 fabrics connected with a layer-3 link.
Today, let’s explore a design that will excite the True Believers in end-to-end layer-2 networks: two EVPN fabrics connected with an EBGP session to form a unified, larger EVPN fabric. We’ll use the same “physical” topology as the previous example; the only modification is that the WA-WB link is now part of the underlay IP network.
… updated on Sunday, September 28, 2025 11:23 +0200
EVPN Designs: Layer-3 Inter-AS Option A
A netlab user wanted to explore a multi-site design where every site runs an independent EVPN fabric, and the inter-site link is either a layer-2 or a layer-3 interconnect (DCI). Let’s start with the easiest scenario: a layer-3 DCI with a separate (virtual) link for every tenant (in the MPLS/VPN world, we’d call that Inter-AS Option A)
Lab topology
IBGP Is the Better EBGP
Whenever I was explaining how one could build EBGP-only data center fabrics, someone would inevitably ask, “But could you do that with IBGP?”
TL&DR: Of course, but that does not mean you should.
Anyway, leaving behind the land of sane designs, let’s trot down the rabbit trail of IBGP-only networks.
Comparing IGP and BGP Data Center Convergence
A Thought Leader1 recently published a LinkedIn article comparing IGP and BGP convergence in data center fabrics2. In it, they3 claimed that:
iBGP designs would require route reflectors and additional processing, which could result in slightly slower convergence.
Let’s see whether that claim makes any sense.
TL&DR: No. If you’re building a simple leaf-and-spine fabric, the choice of the routing protocol does not matter (but you already knew that if you read this blog).
EVPN Designs: EVPN IBGP over IPv4 EBGP
We’ll conclude the EVPN designs saga with the “most creative” design promoted by some networking vendors: running an IBGP session (carrying EVPN address family) between loopbacks advertised with EBGP IPv4 address family.

Oversimplified IBGP-over-EBGP design
There’s just a tiny gotcha in the above Works Best in PowerPoint diagram. IBGP assumes the BGP neighbors are in the same autonomous system while EBGP assumes they are in different autonomous systems. The usual way out of that OMG, I painted myself into a corner situation is to use BGP local AS functionality on the underlay EBGP session:
EVPN Designs: EVPN EBGP over IPv4 EBGP
In the previous blog posts, we explored three fundamental EVPN designs: we don’t need EVPN, IBGP EVPN AF over IGP-advertised loopbacks (the way EVPN was designed to be used) and EBGP-only EVPN (running the EVPN AF in parallel with the IPv4 AF).
Now we’re entering Wonderland: the somewhat unusual1 things vendors do to make their existing stuff work while also pretending to look cool2. We’ll start with EBGP-over-EBGP, and to understand why someone would want to do something like that, we have to go back to the basics.
… updated on Thursday, October 10, 2024 18:04 +0200
EVPN Designs: EBGP Everywhere
In the previous blog posts, we explored the simplest possible IBGP-based EVPN design and made it scalable with BGP route reflectors.
Now, imagine someone persuaded you that EBGP is better than any IGP (OSPF or IS-IS) when building a data center fabric. You’re running EBGP sessions between the leaf- and the spine switches and exchanging IPv4 and IPv6 prefixes over those EBGP sessions. Can you use the same EBGP sessions for EVPN?
TL&DR: It depends™.
One-Arm Hub-and-Spoke VPN with MPLS/VPN
All our previous designs of the hub-and-spoke VPN (single PE, EVPN) used two VRFs for the hub device (ingress VRF and egress VRF). Is it possible to build a one-arm hub-and-spoke VPN where the hub device exchanges traffic with the PE router over a single link?
TL&DR: Yes, but only on some devices (for example, Cisco IOS or FRRouting) when using MPLS transport.
Here’s a high-level diagram of what we’d like to achieve: