Category: DCB
Building a Greenfield Data Center
The following design challenge landed in my Inbox not too long ago:
My organization is the in the process of building a completely new data center from the ground up (new hardware, software, protocols ...). We will currently start with one site but may move to two for DR purposes. What DC technologies should we be looking at implementing to build a stable infrastructure that will scale and support technologies you feel will play a big role in the future?
In an ideal world, my answer would begin with “Start with the applications.”
FCoE between data centers? Forget it!
Was anyone trying to sell you the “wonderful” idea of running FCoE between Data Centers instead of FC-over-DWDM or FCIP? Sounds great ... until you figure out it won’t work. Ever ... or at least until switch vendors drastically increase interface buffers on the 10GE ports.
FCoE requires lossless Ethernet between its “routers” (Fiber Channel Forwarders – see Multihop FCoE 101 for more details), which can only be provided with Data Center Bridging (DCB) standards, specifically Priority Flow Control (PFC). However, if you want to have lossless Ethernet between two points, every layer-2 (or higher) device in the path has to support DCB, which probably rules out any existing layer-2+ solution (including Carrier Ethernet, pseudowires, VPLS or OTV). The only option is thus bridging over dark fiber or a DWDM wavelength.
FCoE, QCN and Frame Relay analogies
Just when I hoped we were finally getting somewhere with the FCoE/QCN discussion, Brocade managed to muddy the waters with its we-still-don’t-know-what-it-is announcement. Not surprisingly, networking consultants like my friend Greg Ferro of the Etherealmind fame responded to the shenanigan with statements like “FCoE ... is a technology so mindboggingly complicated that marketing people can argue over competing claims and all be correct.” Not true, the whole thing is exceedingly simple once you understand the architecture (and the marketing people always had competing claims).
Pretend for a minute that FC ≈ IP and LAN bridging ≈ Frame Relay, teleport into this parallel universe and allow me to tell you the whole story once again in more familiar terms.
Does FCoE need QCN (802.1Qau)?
One of the recurring religious FCoE-related debates of the last months is undoubtedly “do you need QCN to run FCoE” with Cisco adamantly claiming you don’t (hint: Nexus doesn’t support it) and HP claiming you do (hint: their switch software lacks FC stack) ... and then there’s this recent announcement from Brocade (more about it in a future post). As is usually the case, Cisco and HP are both right ... depending on how you design your multi-hop FCoE network.
Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.
PFC/ETS and storage traffic: the real story
Data Center Ethernet (or DCB or CEE, depending on who you are) is a hot story these days and it’s no wonder that misconceptions galore. However, when I hear several CCIEs I highly respect talk about “Priority Flow Control can be used to stop all the other traffic when storage needs more bandwidth”, I get worried. Exactly the opposite is true: you use PFC to stop the overzealous storage traffic (primarily FCoE, but also iSCSI) to make sure you don’t drop it.
Introduction to 802.1Qaz (Enhanced Transmission Selection – ETS)
Enhanced Transmission Selection (ETS) is the second part of the Data Center Bridging puzzle (I’ve already described Priority Flow Control). It specifies two different technologies:
- Queuing mechanisms in bridges
- Data Center Bridging eXchange protocol: a Control/Negotiation protocol that allows bridges and hosts to negotiate QoS parameters in a bridged network.
Although some bridges from some vendors supported numerous QoS mechanisms in the past, 802.1Qaz is the first attempt to standardize a richer set of QoS behaviors than the strict priority queuing defined in 802.1p.
What exactly is a Nexus 4000?
Someone mentioned a while ago in a comment to one of my blog posts that the Nexus 4000 switch already supports multihop FCoE. Now that we know what multihop FCoE really is, let’s see how Nexus 4000 fits into the picture.
The Cisco Nexus 4000 Series Design Guide starts with a confusing set of claims:
- The Cisco Nexus 4000 Series Switches provide the Fibre Channel Forwarder (FCF) function.
- Nexus 4000 is a FCoE Initialization Protocol (FIP) snooping bridge.
Introduction to 802.1Qbb (Priority-based Flow Control — PFC)
Yesterday I wrote that you don’t need DCB technologies to implement FCoE in your network. The FC-BB-5 standard is quite explicit (it also says that 802.1Qbb is the other option):
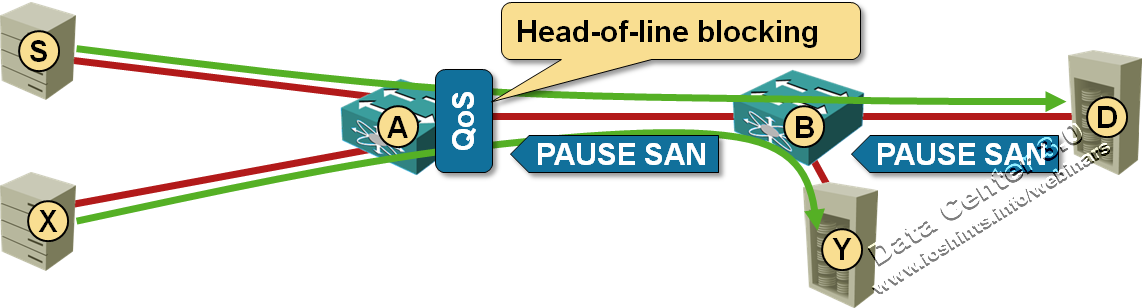
Lossless Ethernet may be implemented through the use of some Ethernet extensions. A possible Ethernet extension to implement Lossless Ethernet is the PAUSE mechanism defined in IEEE 802.3-2008.
The PAUSE mechanism (802.3x) gives you lossless behavior, but results in undesired side effects when you run LAN and SAN traffic across a converged Ethernet infrastructure.
DCB and TRILL have nothing in common
The emerging Ethernet bridging technologies have been hyped to an extent where the lines between them completely blurred, resulting in statements like “we need DCB and TRILL for FCoE”. Actually, none of that is true, but let’s focus on DCB and TRILL first.