Category: BGP
Changing VPNv4 route attributes within the MPLS/VPN network
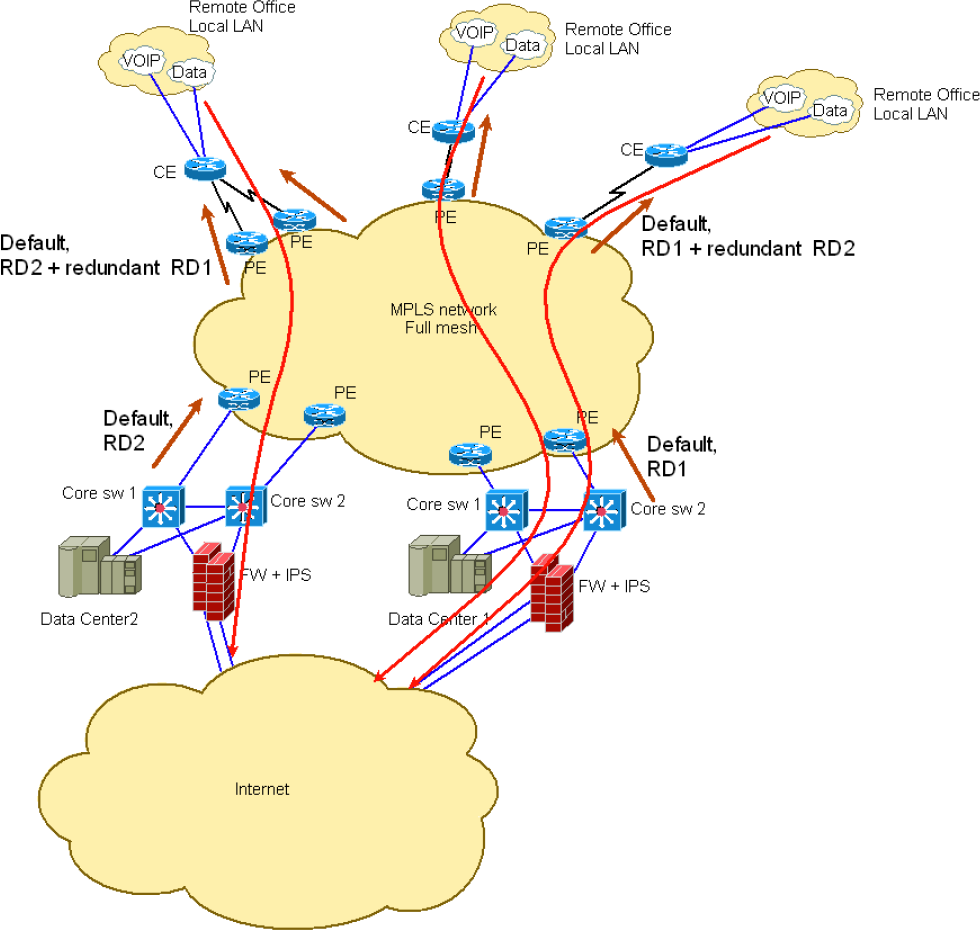
John (not a real name for obvious reasons) sent me an interesting challenge after attending my Enterprise MPLS/VPN Deployment webinar. He’s designed an MPLS/VPN network approximated by the following diagram:
Using BGP in Phase 1 DMVPN network
If you’re building a DMVPN network with large spoke-to-hub ratio, BGP is one of the better options – it has no scalability limitations associated with multicast flooding; the only parameter you have to consider is the number of BGP sessions the hub router can handle (and according to this presentation, ASR can handle 2000+ spokes).
Chinese BGP incident: was it a traffic hijack?
You’re probably familiar with the April fat fingers incident in which Chinanet (AS 23724) originated ~37.000 prefixes for about 15 minutes. The incident made it into the annual report of US Congress’ U.S.-China Economic and Security Review Commission (page 243 of this PDF) and the media was more than happy to pick it up (Andree Toonk has a whole list of links in his blog post). We might never know whether the misleading statements in the report were intentional or just a result of clueless technical advisors, but the facts are far away from what they claim:
Introduction to LISP
I’ve been mentioning LISP several times during the last months. It seems to be the only viable solution to the global IP routing table explosion. All other proposals require modifying layers above IP and while that’s where the problem should have been solved, expecting those layers to change any time soon is like waiting for Godot.
If you’re interested in LISP, start with the introduction to LISP I wrote for Search Telecom, continue with the LISP tutorial from NANOG 45 and (for the grand finale) listen to three Google Talks from Dino (almost four hours).
BGP: time to grow up
If you’re in the Service Provider business, this is (hopefully) old news: on Friday, RIPE decided to experiment with the Internet causing routers running IOS-XR to hiccup. They stopped the experiment in less than half an hour and only 2% of the Internet was affected according to Renesys analysis (a nice side effect: Tassos had great fun decoding the offending BGP attribute from hex dumps).
My first gut reaction was “something’s doesn’t feel right”. A BGP bug in IOS-XR affects only 2% of the Internet? Here are some possible conclusions:
And we thought BGP was insecure
Every now and then an incident reminds us how vulnerable BGP is. Very few of these incidents are intentional (the Pakistan vs. YouTube is a rare exception) and few of them are propagated far enough to matter on a global scale (bugs in BGP implementations are scarier). Most of these incidents could be prevented with either Secure BGP or Secure Origin BGP but it looks like they will not be implemented any time soon.
Editing AS-path access lists
Jerry sent me an interesting question:
I was wondering if there's a way to modify an as-path access-list much like we do with regular access lists, simply by adding/ removing lines according to their sequence numbers.
I'm not aware of any such mechanism in Cisco IOS (but then maybe I’m missing something), but his question made me wonder: if you’re maintaining large AS-path access lists, do you edit them on the router (I guess not) or off-line (on a NMS platform) and download them when they need to be changed?
Secure BGP
One of the decades-long grudges most people have with BGP is that it’s so easy to insert bogus routing information into the Internet if your upstream ISP happens to be a careless idiot (as Google discovered when Pakistan decided to use blackhole routing for Youtube and leaked the routes). There are two potential solutions that use X.509 certificates to authenticate BGP information: Secure BGP (which uses optional transitive attributes) authenticates the originator as well as the whole AS-path (using AS-by-AS certificates), while the significantly simpler Secure Origin BGP (which uses new BGP messages) authenticates only the originator of the routing information.
This is how you design a useful protocol
A post in the My CCIE Training Guide pointed me to the GoogleTechTalk given by Yakov Rekhter (one of the fathers of BGP) in 2007. You should watch the whole video (it helps you understand numerous BGP implementation choices), but its most important message is undoubtedly the Design by Pragmatism approach:
- They had a simple, manageable problem (get from a spanning-tree Internet topology to a mesh topology).
- They did not want to solve all potential future problems; they left that marvelous task to IDRP (which still got nowhere the last time I've looked).
- They started with simple specifications (three napkins), had two interoperable implementations in a few months, and wrote the RFC after BGP was already in production use.
- They rolled it out, learnt from its shortcomings and fixed it.
- They gradually made it easily extensible: TLV encoding, optional attributes, capabilities negotiations. This approach made it possible to carry additional address families in BGP and use it for applications like MPLS VPN and VPLS.
One could only hope that the IPv6 architects had used the same approach ... but as Yakov said in his talk, that’s “water under the bridge”.
QPPB in MPLS VPN
TL&DR: QPPB works in MPLS VPNs… with a few limitations (at least in Cisco IOS implementation).
And now for the long story: A while ago I’ve noticed that my LinkedIn friend Joe Cozzupoli changed his status to something like “trying to get QPPB to work in MPLS VPN environment”. I immediately got in touch with him and he was kind enough to send me working configurations; not just for the basic setup, but also for Inter-AS Option A, B and C labs.
Knowing that QPPB relies on CEF, I doubted it would work as well on VRF interfaces as it does in pure IP environments, so I decided to do a few tests of my own. Here are the limitations I found:
Display the rejected BGP routes
Jernej sent me an interesting question: “does Cisco IOS have an equivalent to the Extremeware’s show bgp neighbor a.b.c.d rejected-routes command which displays all routes rejected by inbound filters?”
Short answer: it doesn’t.
… updated on Tuesday, December 29, 2020 09:51 UTC
Disable Flapping BGP Neighbors
It looks like we’re bound to experience a widespread BGP failure once every few months. They all follow the same pattern:
- A “somewhat” undertested BGP implementation starts advertising paths with “unexpected” set of attributes.
- A specific downstream BGP implementation (and it could be a different implementation every time) a few hops down the road hiccups and sends a BGP notification message to its upstream neighbor.
- BGP session must be reset following a notification message; the routes advertised over it are lost and withdrawn, causing widespread ripples across the Internet.
- The offending session is reestablished seconds later and the same set of routes is sent again, causing the same failure and a session reset. If the session stays up long enough, some of the newly received routes might get propagated and will flap again when the session is reset.
- The cyclical behavior continues until a manual intervention.
Questions on BGP AS-Path Filters in Non-Transit Networks
I’ve sent a link to my Filter excessively prepended AS-paths article as an answer to a BGP route-map question to the NANOG mailing list and got several interesting questions from Dylan a few hours later. As they are pretty common, you might be interested in them as well.
In my environment, we are not doing full routes. We have partial routes from AS X and then fail to AS Y. Is their any advantage for someone like me to do this, as we are not providing any IP transit so we are not passing the route table to anyone else?
Aggressive BGP Fall-Over Behavior
Soon after I wrote the Designing Fast Converging BGP Networks article (you’ll find it somewhere in this list, one of my regular readers sent me an interesting problem: BGP sessions would be lost in his (IS-IS based) core network if he would use fall-over on IBGP neighbors and the BGP router would have a primary and a backup path to the IBGP neighbor.
It turned out to be an interesting side effect of aggressive route table purge following a link failure: the route to BGP neighbor was removed from the routing table before IS-IS ran SPF and installed an alternate route, and BGP decided it’s time to give up and terminate the session.
For more details, read the What Exactly Happens after a Link Failure blog post.
Internet anarchy: I’ll advertise whatever I like
We all know that the global BGP table is exploding (see the Active BGP entries graph) and that it will eventually reach a point where the router manufacturers will not be able to cope with it via constant memory/ASIC upgrades (Note: a layer-3 switch is just a fancy marketing name for a router). The engineering community is struggling with new protocol ideas (for example, LISP) that would reduce the burden on the core Internet routers, but did you know that we could reduce the overall BGP/FIB memory consumption by over 35% (rolling back the clock by two and a half years) if only the Internet Service Providers would get their act together.
Take a look at the weekly CIDR report (archived by WebCite on June 22nd), more specifically into its Aggregation summary section. The BGP table size could be reduced by over 35% if the ISPs would stop announcing superfluous more specific prefixes (as the report heading says, the algorithm checks for an exact match in AS path, so people using deaggregation for traffic engineering purposes are not even included in this table). You can also take a look at the worst offenders and form your own opinions. These organizations increase the cost of doing business for everyone on the Internet.
Why is this behavior tolerated? It’s very simple: advertising a prefix with BGP (and affecting everyone else on the globe) costs you nothing. There is no direct business benefit gained by reducing the number of your BGP entries (and who cares about other people’s costs anyway) and you don’t need an Internet driver’s license (there’s also no BGP police, although it would be badly needed).
Fortunately, there are some people who got their act together. The leader in the week of June 15th was JamboNet (AS report archived by Webcite on June 22nd) that went from 42 prefixes to 7 prefixes.
What can you do to help? Advertise the prefixes assigned to you by Internet Registry, not more specific ones. Check your BGP table and clean it. Don’t use more specific prefixes solely for primary/backup uplink selection.