Category: BGP
Configuring BGP Community Propagation is Confusing
A large number of vendors claim to use industry-standard CLI, which means “something that looks like Cisco IOS, but we can’t say that in public.” The implementations of that “standard” are full of quirks; as I was making fun of Cisco IOS last week, it’s only fair to look at how others deal with BGP community propagation.
netlab has BGP configuration templates for 14 different platforms1, including these implementations that look like Cisco IOS from a distance if you squint just right2: Arista EOS, Aruba CX, and FRRouting. You can check the configuration templates if you wish; here’s the TC&DB3 overview:
BGP Community Propagation on Cisco IOS/XE: The 90's Called
Just when I thought no vendor stupidity peculiarity could surprise me, Cisco IOS/XE proved me wrong.
I was improving a completely unrelated BGP functionality. I ran BGP integration tests on Cisco IOL (because it’s the fastest one to boot), and the BGP community propagation test failed. After verifying that I did not change the template and that the data structures had not changed, I checked the IOL release I was using.
Surprise 🎉🎉: the neighbor send-community configurations that worked since (at least) the IOS Classic release 15.x stopped working in Cisco IOS/XE release 17.16.01a.
Worth Reading: BGP Unnumbered in 2025
Gabriel sent me a pointer to a blog post by Rudolph Bott describing the details of BGP Unnumbered implementations on Nokia, Juniper, and Bird.
Even more interestingly, Rudolph points out the elephant I completely missed: RFC 8950 refers to RFC 2545, which requires a GUA IPv6 next hop in BGP updates (well, it uses the SHALL wording, which usually means “troubles ahead”). What do you do if you’re running EBGP on an interface with no global IPv6 addresses? As expected, vendors do different things, resulting in another fun interoperability exercise.
iBGP Local-AS Next Hop Requirements
Did you know you could use the neighbor local-as BGP functionality to fake an iBGP session between different autonomous systems? I knew Cisco IOS supported that monstrosity for ages (supposedly “to merge two ISPs that have different AS numbers”) and added the appropriate tweaks1 into netlab when I added the BGP local-as support in release 1.3.1. Someone couldn’t resist pushing us down that slippery slope, and we ended with IBGP local-as implemented on 18 platforms (almost a dozen network operating systems).
I even wrote a related integration test, and all our implementations passed it until I asked myself a simple question: “But does it work?” and the number of correct implementations that passed the test without warnings dropped to zero.
Passive BGP Sessions
The Dynamic BGP Peers lab exercise gave you the opportunity to build a large-scale environment in which routers having an approved source IP addresses (usually matching an ACL/prefix list) can connect to a BGP route reflector or route server.
In a more controlled environment, you’d want to define BGP neighbors on the BGP RR/RS but not waste CPU cycles trying to establish BGP sessions with unreachable neighbors. Welcome to the world of passive BGP sessions.
Run BGP Across a Firewall
When I asked my readers what they would consider a good use case for EBGP multihop (thanks again to everyone who answered!), many suggested running BGP across a layer-3 firewall (Running BGP across a “transparent” (bump-in-the-wire) firewall is trivial). I turned that suggestion into a lab exercise in which you have to establish an EBGP multihop session across a “firewall” simulated by a Linux host.
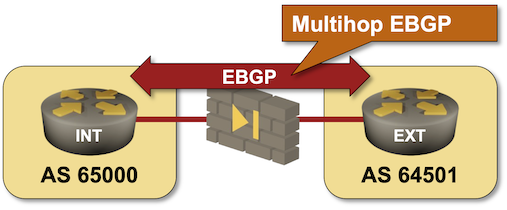
If you haven’t set up your own lab infrastructure, click here to start the lab in your browser using GitHub Codespaces. After starting your codespace, change the directory to basic/e-ebgp-multihop and execute netlab up.
The Curious Case of the BGP Connect State
I got this question from Paul:
Have you ever seen a BGP peer in the “Connect” state? In 20 years, I have never been able to see or reproduce this state, nor any mention in a debug/log. I am starting to believe that all the documentation is BS, and this does not exist.
The BGP Finite State Machine (FSM) (at least the one defined in RFC 4271 and amended in RFC 9687) is “a bit” hard to grasp but the basics haven’t changed from the ancient days of RFC 1771:
Use BGP Outbound Route Filters (ORF) for IP Prefixes
When a BGP router cannot fit the whole BGP table into its forwarding table (FIB), we often use inbound filters to limit the amount of information the device keeps in its BGP table. That’s usually a waste of resources:
- The BGP neighbor has to send information about all prefixes in its BGP table
- The device with an inbound filter wastes additional CPU cycles to drop many incoming updates.
Wouldn’t it be better for the device with an inbound filter to push that filter to its BGP neighbors?
IBGP Is the Better EBGP
Whenever I was explaining how one could build EBGP-only data center fabrics, someone would inevitably ask, “But could you do that with IBGP?”
TL&DR: Of course, but that does not mean you should.
Anyway, leaving behind the land of sane designs, let’s trot down the rabbit trail of IBGP-only networks.
Use Disaggregated BGP Prefixes to Influence Inbound Internet Traffic
As much as I love explaining how to use BGP in an optimal way, sometimes we have to do what we know is bad to get the job done. For example, if you have to deal with clueless ISPs who cannot figure out how to use BGP communities, you might be forced to use the Big Hammer of disaggregated prefixes. You can practice how that works in the next BGP lab exercise.