OMG: VTP Is Insecure
One of my readers sent me an interesting pointer:
I just watched a YouTube video by a security researcher showing how a five line python script can be used to unilaterally configure a Cisco switch port connected to a host computer into a trunk port. It does this by forging a single virtual trunk protocol (VTP) packet. The host can then eavesdrop on broadcast traffic on all VLANs on the network, as well as prosecute man-in-the-middle of attacks.
I’d say that’s a “startling revelation” along the lines of “OMG, VXLAN is insecure” – a wonderful way for a security researcher to gain instant visibility. From a more pragmatic perspective, if you enable an insecure protocol on a user-facing port, you get the results you deserve1.
While I could end this blog post with the above flippant remark, it’s more fun considering two fundamental questions.
Mixed Feelings about BGP Route Reflector Cluster ID
Here’s another BGP Route Reflector myth:
In a redundant design, you should use Route Reflector Cluster ID to avoid loops.
TL&DR: No.
While BGP route reflectors can cause permanent forwarding loops in sufficiently broken topologies, the Cluster ID was never needed to stop a routing update propagation loop:
Feedback: ipSpace.net Materials
Andy Lemin sent me such a wonderful review of ipSpace.net materials that I simply couldn’t resist publishing it ;)
ipSpace.net is probably my favorite networking resource out there. After spending years with other training content sites which are geared around certifications, ipspace.net provides a totally unique source of vendor neutral opinions, information, and anecdotes – the kind of information that is just not available anywhere else. And to top it off, is presented by a wonderful speaker who is passionate, smart and really knows his stuff!
The difference between an engineer who just has certs versus an engineer who has a rounded and wide view of the whole industry is massive. An engineer with certs can configure your network, but an engineer with all the knowledge this site provides, is someone who can question why and challenge how we can configure your network in a better way.
Worth Reading: We're a Decade Past Blade Server Market Peak
Stumbled upon a totally unexpected fun fact:
Every server vendor either peaked or hits the peak of maximum units sold per quarter in 2015. In the years that follow, the monthly averages drop.
Keep that in mind the next time Cisco sales team comes along with a UCS presentation.
Worth Reading: Non-Standard Standards, SRv6 Edition
Years ago, I compared EVPN to SIP – it has a gazillion options, and every vendor implements a different subset of them, making interoperability a nightmare.
According to Andrew Alston, SRv6 is no better (while being a security nightmare). No surprise there.
Lesson Learned: The Way Forward
I tried to wrap up my Lessons Learned presentation on a positive note: what are some of the things you can do to avoid all the traps and pitfalls I encountered in the almost four decades of working in networking industry:
- Get invited to architecture and design meetings when a new application project starts.
- Always try to figure out what the underlying actual business needs are.
- Just because you can doesn’t mean that you should.
- Keep it as simple as possible, but no simpler.
- Work with your peers and explain how networking works and why you face certain limitations.
- Humans are not perfect – automate as much as it makes sense, but no more.
Do a Cleanup Before Automating Your Network
Remington Loose sent me an interesting email describing his views on the right approach to network automation after reading my Network Reliability Engineering Should Be More than Software or Automation rant – he’s advocating standardizing network services and cleaning up your network before trying to deploy full-scale automation.
I think you are 100% right to start with a thorough cleanup before automation. Garbage in, garbage out. It is also the case that all that inconsistency and differentiation makes for complexity in automation (as well as general operations) that makes it harder to gain traction.
netsim-tools Release 1.1.2
Every time I’m writing netsim-tools release notes I’m amazed at the number of features we managed to put together in just a few weeks.
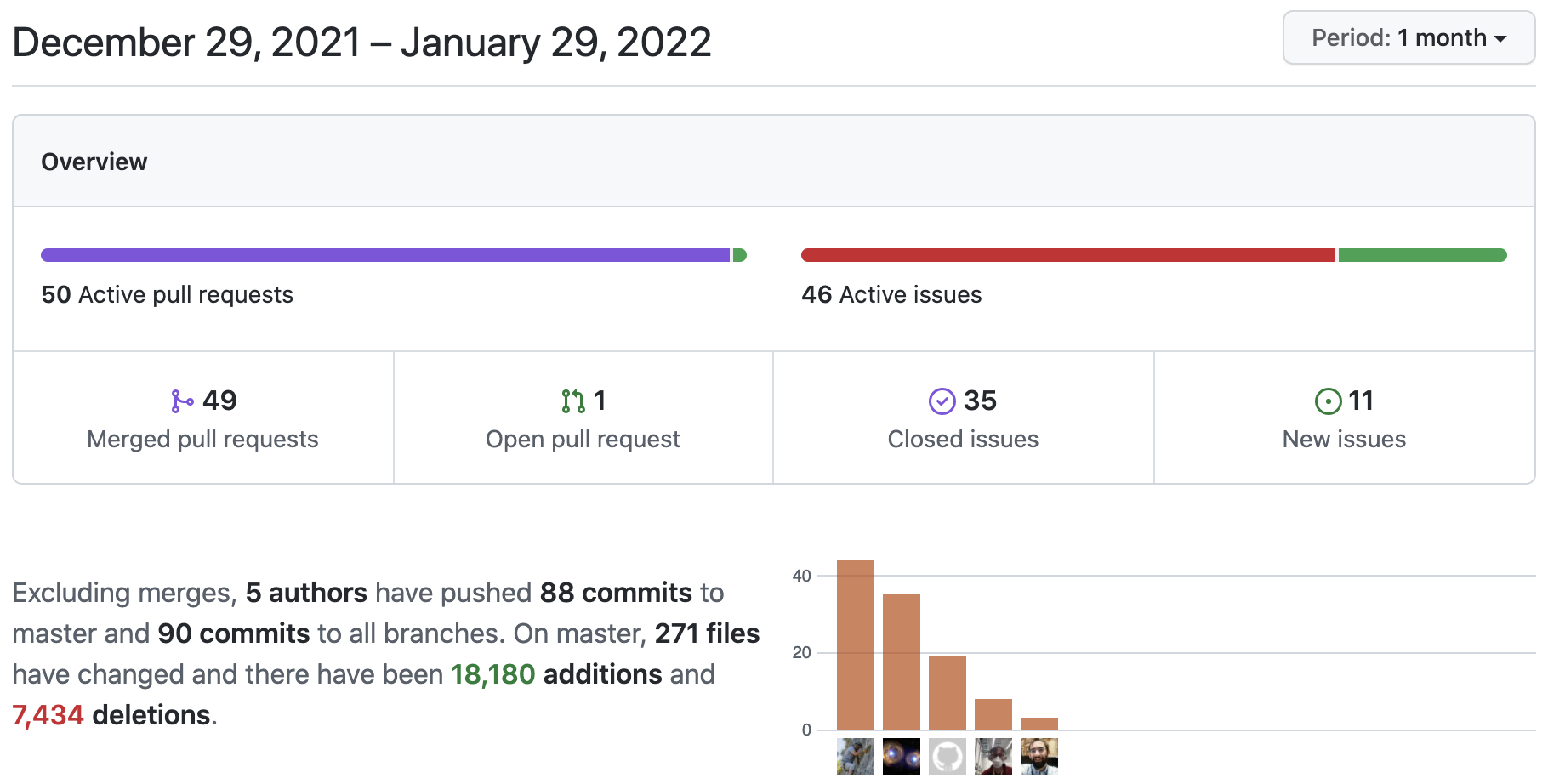
Here are the goodies from netsim-tools releases 1.1.1 and 1.1.2:
BGP Route Reflector Myths
New networking myths are continuously popping up. Here’s a BGP one I encountered a few days ago:
You don’t need IBGP sessions between BGP route reflectors
In general, that’s clearly wrong, as illustrated by this setup:
… updated on Monday, January 31, 2022 19:26 UTC
Sample Lab: SR-MPLS on Junos and SR Linux
Last week I published a link to Pete Crocker’s RSVP-TE lab, but there’s more: he created another lab using the same topology that uses SR-MPLS with IS-IS to get the job done.
Jeroen Van Bemmel did something similar for SR Linux: his lab topology has fewer devices (plus SR Linux runs in containers), so it’s easily deployable on machines without humongous amount of memory.
Worth Reading: The Network Does Too Much
Tom Hollingsworth published a more eloquent version of what I’ve been saying for ages:
- Complexity belongs to the end nodes;
- Network should provide end-to-end packet transport, not a fix for every stupidity someone managed to push down the stack;
- There’s nothing wrong with being a well-performing utility instead of pretending your stuff is working on unicorn farts and fairy dust.
Obviously it’s totally against the vested interest of any networking vendor out there to admit it.
Worth Exploring: Christoph Jaggi's New Web Site
Christoph Jaggi, the author of Ethernet Encryption webinar and ethernet encryptor market overviews launched a new site in which he collected tons material he created in the past – the network security and news and articles sections are definitely worth exploring.
Video: Kubernetes Architecture
Yesterday I mentioned the giant glob of complexity called Kubernetes (see also more nuanced take on the topic). If you want to slowly unravel it, Kubernetes Architecture video from the excellent Kubernetes Networking Deep Dive webinar by Stuart Charlton is a pretty good starting point.
MTU Settings in Virtual Network Devices
When I finally1 managed to get SR Linux running with netlab, I wanted to test how it interacts with Cumulus VX and FRR in an OSPF+BGP lab… and failed. Jeroen Van Bemmel quickly identified the culprit: MTU. Yeah, it’s always the MTU (or DNS, or BGP).
I never experienced a similar problem, so of course I had to identify the root cause:
Three Dimensions of BGP Address Family Nerd Knobs
Got into an interesting BGP discussion a few days ago, resulting in a wild chase through recent SRv6 and BGP drafts and RFCs. You might find the results mildly interesting ;)
BGP has three dimensions of address family configurability:
- Transport sessions. Most vendors implement BGP over TCP over IPv4 and IPv6. I’m sure there’s someone out there running BGP over CLNS1, and there are already drafts proposing running BGP over QUIC2.
- Address families enabled on individual transport sessions, more precisely a combination of Address Family Identifier (AFI) and Subsequent Address Family Identifier.
- Next hops address family for enabled address families.