netlab: How do I Specify VLAN Interface Parameters
Similarly to how it handles VRFs, netlab automatically creates VLANs on a lab device if the device uses them on any access- or trunk link or if the VLAN is mentioned in the node vlans dictionary.
If the VLAN is an IRB VLAN (which can be modified globally or per node with the VLAN mode parameter), netlab also creates the VLAN (or SVI, or BVI) interface. But how do you specify the parameters of the VLAN interface?
How Does Netlab Deal with Server Reboots?
Now and then, someone asks how netlab deals with reboots (or power failures or crashes) of the server it’s running on.
TL&DR: It doesn’t. However…
netlab is a CLI command that acts as an umbrella orchestration layer for Vagrant and Containerlab. It does not run as a cron job, init script, or service and thus cannot be invoked when a server is booted.
Per-Prefix and Per-VRF MPLS/VPN and EVPN Labels/VNIs
Long, long time ago1, in an ancient town far, far away2, an old-school networking Jedi3 was driving us toward a convent4 where we had an SDN workshop5. While we were stuck in the morning traffic jam, an enthusiastic engineer sitting beside me wanted to know my opinion about per-prefix and per-VRF MPLS/VPN label allocation.
At that time, I had lived in a comfortable Cisco IOS bubble for way too long, so my answer was along the lines of “Say what???” Nicola Modena6 quickly expanded my horizons, and I said, “Gee, I have to write a blog post about that!” As you can see, it took me over a decade.
Lab: Configure IS-IS on Point-to-Point Links
From a very high-level perspective, OSPF and IS-IS are quite similar. Both were created in the Stone Age of networking, and both differentiate between multi-access LAN segments and point-to-point serial interfaces. Unfortunately, that approach no longer works in the Ethernet Everywhere world where most of the point-to-point links look like LAN segments, so we always have to change the default settings to make an IGP work better.
That’s what you’ll do in today’s lab exercise, which also explains the behind-the-scenes differences between point-to-point and multi-access links and the intricate world of three-way handshake.
NOG.HR: A NOG Meeting Worth Attending
I never know what to expect when I’m invited to speak at a regional (or in-country) Network Operator Group (NOG) meeting. Sometimes, it turns out to be a large conference (PLNOG and ITNOG come to mind); other times, it’s just a few people gathered around free donuts and coffee1. Last week’s Croatian NOG (NOG.HR) meeting was in the Goldilocks zone between the extremes: plenty of interested networking engineers, but not large enough to be overpowering.
Also, it was such a nice experience ;)
Comparing IP and CLNP: Finding Adjacent Nodes
Now that we know a bit more about addresses in a networking stack (read the whole series) and why CLNP uses node addresses while TCP/IP uses interface addresses, let’s see how they solve common addressing problems like finding adjacent nodes.
Let’s start with the elephant in the room: how do you know whether you can reach a host you want to communicate with directly? In the following diagram, how does A know whether B is sitting next to it?
MUST READ: Egress Peer Engineering
Dmytro Shypovalov wrote a great series of detailed posts on Egress Peer Engineering:
- Poor Man’s Traffic Engineering
- Egress Peer Engineering: Basics
- Egress Peer Engineering: Building Blocks
Have fun!
Using BGP NO_EXPORT Community to Filter Transit Routes
In previous BGP policy lab exercises, we covered several mechanisms you can use to ensure your autonomous system is not leaking transit routes (because bad things happen when you do, particularly when your upstream ISP is clueless).
As you probably know by now, there’s always more than one way to get something done with BGP. Today, we’ll explore how you can use the NO_EXPORT community to filter transit routes.
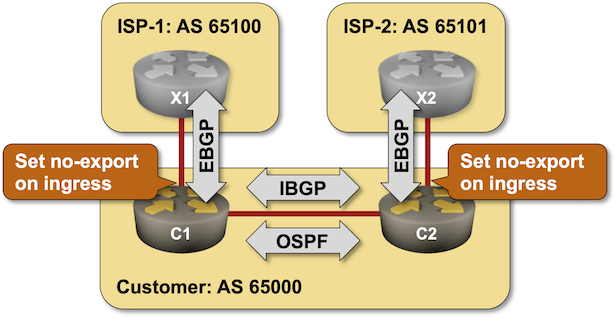
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to policy/d-no-export and execute netlab up.
Packet Pushers: Chat with Eric Chou
A while ago, Eric Chou invited me to a friendly chat in his Network Automation Nerds podcast.
The episode was published a few days ago; I hope you’ll enjoy listening to it.
IS-IS Labs: Explore IS-IS Data Structures
In the first exercise in the IS-IS labs series, you configured IS-IS routing for IPv4. Before moving on to more complex topics, let’s explore the data structures IS-IS created to represent your network.
