How ARP Killed a Static Route
The amount of weird stuff we discover in netlab integration tests is astounding, or maybe I have a knack for looking into the wrong dark corners (my wife would definitely agree with that). Today’s special: when having two next hops kills a static route.
TL&DR: default ARP settings on a multi-subnet Linux host are less than optimal.
We use these principles when creating netlab integration tests:
- They should contain a single device-under-test and a bunch of attached probes.
- They should test a single feature.
- They should not rely on the device-under-test. All validation has to be done on probes.
How do you test static routes under these restrictions? Here’s what we did:
- Connect a device under test to a Linux node (running FRRouting) with a loopback interface.
- Configure a static route for the loopback interface on the device-under-test with the next hop pointing to the Ethernet IP address of the Linux node.
- On the Linux node, ping the Ethernet interface of the device-under-test from the loopback IP address.
The outgoing ICMP request packet should always be sent (the destination IP address is directly connected). The reply, however, will come back only when the device under test has a correctly configured static route for the source IP address of the ICMP request packet.
Here’s a sample network topology (the test where we discovered this quirk was a bit more convoluted):

This is the corresponding netlab lab topology:
---
provider: clab
module: [ routing ]
nodes:
dut:
device: vjunos-switch
routing.static:
- node: probe
nexthop.node: probe
probe:
device: frr
links: [ dut-probe ]
As expected, every correctly configured device easily passes this test. Mission accomplished.
$ netlab connect probe
Connecting to container clab-X-probe, starting bash
Use vtysh to connect to FRR daemon
probe(bash)# ping -c 3 10.1.0.1 -I 10.0.0.2
PING 10.1.0.1 (10.1.0.1) from 10.0.0.2: 56 data bytes
64 bytes from 10.1.0.1: seq=0 ttl=64 time=0.484 ms
64 bytes from 10.1.0.1: seq=1 ttl=64 time=0.759 ms
64 bytes from 10.1.0.1: seq=2 ttl=64 time=0.661 ms
--- 10.1.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.484/0.634/0.759 ms
Not really. There might be more than one link between the devices, in which case netlab configures multiple static routes for the same destination. Let’s rerun the test with the following topology:
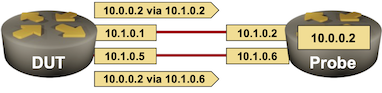
Two links, two next hops for the same destination
Here’s the relevant netlab topology if you want to rerun the experiment. The only change is in line 13 (two links instead of one).
provider: clabmodule: [ routing ]nodes:dut:device: vjunos-switchrouting.static:- node: probenexthop.node: probeprobe:device: frrlinks: [ dut-probe, dut-probe ]
Most devices pass this test with flying colors, but the ping command fails with vJunos-switch until we ping the switch from the directly-connected Linux interface:
probe(bash)# ping 10.1.0.1 -I 10.0.0.2
PING 10.1.0.1 (10.1.0.1) from 10.0.0.2: 56 data bytes
^C
--- 10.1.0.1 ping statistics ---
5 packets transmitted, 0 packets received, 100% packet loss
probe(bash)# ping -c 1 10.1.0.1
PING 10.1.0.1 (10.1.0.1): 56 data bytes
64 bytes from 10.1.0.1: seq=0 ttl=64 time=2.248 ms
--- 10.1.0.1 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 2.248/2.248/2.248 ms
probe(bash)# ping -c 3 10.1.0.1 -I 10.0.0.2
PING 10.1.0.1 (10.1.0.1) from 10.0.0.2: 56 data bytes
64 bytes from 10.1.0.1: seq=0 ttl=64 time=0.437 ms
64 bytes from 10.1.0.1: seq=1 ttl=64 time=0.775 ms
64 bytes from 10.1.0.1: seq=2 ttl=64 time=0.489 ms
--- 10.1.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.437/0.567/0.775 ms
This is clearly a gigantic WTAF moment, but fortunately, I experienced similar stuff before and immediately suspected we had to warm the ARP cache on one of the devices. Next step: A packet capture on the link that the ICMP request should be traversing. It might make your jaw drop 😳
$ netlab capture probe eth1 ip or arp
Starting packet capture on probe/eth1: sudo ip netns exec clab-X-probe tcpdump -i eth1 --immediate-mode -l -vv ip or arp
tcpdump: listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
11:31:43.900846 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 10.1.0.1 tell 10.0.0.2, length 28
11:31:44.903669 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 10.1.0.1 tell 10.0.0.2, length 28
11:31:45.927675 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 10.1.0.1 tell 10.0.0.2, length 28
11:31:47.901226 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 10.1.0.1 tell 10.0.0.2, length 28
I can’t decide what’s weirder:
- Linux is sending an ARP request from the IP address belonging to another interface
- Junos is not answering that ARP request.
Side note: Pinging 10.1.0.1 from 10.1.0.2 warms the ARP cache on Linux and the Junos switch, so the subsequent ICMP packet sent from the loopback interface’s IP address needs no ARP resolution.
Reading RFC 826 is useless. It’s so underspecified that it’s impossible to answer whether Linux violates it (probably not). Furthermore, as I’m reading it, the receiver of an ARP request should respond to anything and enter any address information into its ARP table. I’m probably missing something (including some weird Linux sysctl parameter); comments are most welcome.
But Why Did It Work with a Single Link?
Here’s the head-scratching part: why did a single-link test work while the two-link test requires an ARP warmup exercise?
It turns out that Junos (like any other decent network device) preemptively resolves the next hops of the static routes. That creates an ARP entry on both ends of the link, and the ping works.
admin@dut> show configuration routing-options
static {
route 10.0.0.2/32 next-hop 10.1.0.2;
}
admin@dut> show route table inet.0
inet.0: 4 destinations, 4 routes (4 active, 0 holddown, 0 hidden)
Limit/Threshold: 1048576/1048576 destinations
+ = Active Route, - = Last Active, * = Both
10.0.0.1/32 *[Direct/0] 00:02:29
> via lo0.0
10.0.0.2/32 *[Static/5] 00:02:26
> to 10.1.0.2 via ge-0/0/0.0
10.1.0.0/30 *[Direct/0] 00:02:29
> via ge-0/0/0.0
10.1.0.1/32 *[Local/0] 00:02:29
Local via ge-0/0/0.0
admin@dut> show arp
MAC Address Address Name Interface Flags
52:55:0a:00:00:02 10.0.0.2 probe fxp0.0 none
aa:c1:ab:81:dd:60 10.1.0.2 10.1.0.2 ge-0/0/0.0 none
02:00:00:00:00:10 128.0.0.16 fpc0 em1.0 none
Total entries: 3
However, the vJunos-switch VM does that only for one of the next hops. In the two-link scenario, the static route has two next hops, but we can see only a single ARP entry in the ARP table:
admin@dut> show configuration routing-options
static {
route 10.0.0.2/32 next-hop [ 10.1.0.2 10.1.0.6 ];
}
admin@dut> show route table inet.0
inet.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden)
Limit/Threshold: 1048576/1048576 destinations
+ = Active Route, - = Last Active, * = Both
10.0.0.1/32 *[Direct/0] 00:13:08
> via lo0.0
10.0.0.2/32 *[Static/5] 00:13:05
to 10.1.0.2 via ge-0/0/0.0
> to 10.1.0.6 via ge-0/0/1.0
10.1.0.0/30 *[Direct/0] 00:13:08
> via ge-0/0/0.0
10.1.0.1/32 *[Local/0] 00:13:08
Local via ge-0/0/0.0
10.1.0.4/30 *[Direct/0] 00:13:08
> via ge-0/0/1.0
10.1.0.5/32 *[Local/0] 00:13:08
Local via ge-0/0/1.0
admin@dut> show arp
MAC Address Address Name Interface Flags
52:55:0a:00:00:02 10.0.0.2 probe fxp0.0 none
aa:c1:ab:b7:35:90 10.1.0.6 10.1.0.6 ge-0/0/1.0 none
02:00:00:00:00:10 128.0.0.16 fpc0 em1.0 none
Total entries: 3
The ARP cache on Linux mirrors that:
$ netlab connect probe arp
Connecting to container clab-X-probe, executing arp
ge-0-0-1.0.dut (10.1.0.5) at 0c:00:8b:48:ac:02 [ether] on eth2
ge-0-0-0.0.dut (10.1.0.1) at <incomplete> on eth1
Ultimately, my incredible “luck” (I chose the wrong interface to ping) created this perfect storm, and I don’t want to tell you how much time we wasted chasing this particular gremlin.
Of Course, There’s a sysctl Hack
A few days after I wrote this blog post, Stefano Sasso encountered the same weird behavior when testing static routes on VyOS. This time, he found the nerd knob to tweak to make Linux behave like a reasonable multi-subnet device. We added that setting to the Linux and FRR initial configuration script, hoping we won’t encounter yet another even weirder variant in the future.
This is a long term "issue" with Linux that cannot be changed because of the "never break userspace" promise. Most Linux-based NOS will change arp_announce to 2, arp_notify to 1 and arp_ignore to 1 to match the behavior f most commercial NOS.
Cumulus does that: net.ipv4.conf.default.arp_announce = 2 net.ipv4.conf.all.arp_notify = 1 net.ipv4.conf.default.arp_notify = 1 net.ipv4.conf.default.arp_ignore=1
(source: https://docs.nvidia.com/networking-ethernet-software/cumulus-linux-512/Layer-3/Address-Resolution-Protocol-ARP/)
Thanks a million! Will add these settings to Linux/FRR initial configuration templates.
On a tangential topic: a pointer to a list of recommended sysctl settings would be highly appreciated.
RFC 1122 describes »two different conceptual models for multihoming«, the strong ES model (addresses belong to specific interfaces) and the weak ES model (addresses belong to whole host). Linux' default settings follow weak ES model.
Another example of a very dangerous setting (which is often enabled by default) is Large Receive Offloading (LRO). For end hosts this optimization can be useful, but it is should never be used when forwarding packets.
Thanks Ivan! Meanwhile JunOS has added "Layer 2 Mapping" to IS-IS, which binds IS-IS next-hops directly to ARP/ND MAC entries (on Ethernet interfaces): https://www.juniper.net/documentation/us/en/software/junos/is-is/topics/concept/isis-layer2-mapping.html