… updated on Thursday, November 10, 2022 07:58 UTC
Using EVPN/VXLAN with MLAG Clusters
There’s no better way to start this blog post than with a widespread myth: we don’t need MLAG now that most vendors have implemented EVPN multihoming.
TL&DR: This myth is close to the not even wrong category.
As we discussed in the MLAG System Overview blog post, every MLAG implementation needs at least three functional components:
- Forwarding table synchronization – members of an MLAG cluster have to synchronize MAC and ARP tables.
- Synchronized control plane protocols – members of an MLAG cluster must use the same system ID for LACP and should synchronize STP state (often implemented with running STP on a single member of the MLAG cluster)
- Configuration synchronization – having different access lists configured on individual members of a link aggregation group is a fabulous recipe for lengthy troubleshooting sessions.
EVPN multihoming solves the forwarding table synchronization. An MLAG implementation could use ICCP (RFC 7275) to synchronize LAG membership and LACP (but not STP). I’m unaware of any standard technology that would address configuration synchronization.
EVPN multihoming is thus an excellent building block of an MLAG implementation, but you still need other bits, some of which are not standardized. Multi-vendor MLAG or MLAG cluster across numerous nodes (beyond the usual two) thus remains firmly in the PowerPoint domain.
That must be sad news for the true believers in the powers of EVPN, but at least EVPN provides everything you need to synchronize the forwarding tables, right? After all:
- MLAG cluster members use Ethernet Segment Identifiers (ESI) to identify links connected to the same CE device or CE network.
- PE devices use the ESI information to identify other members in an MLAG cluster and elect a dedicated forwarder (in active/standby deployments).
- MLAG cluster members use ESI information from MAC+IP updates to synchronize the MAC and ARP tables.
- Ingress PE devices can use ESI membership to implement optimal load balancing toward all MLAG cluster members, making the anycast gateway kludges irrelevant.
That is almost correct, apart from the last bit.
EVPN MAC-Based Load Balancing
Let’s use the same data center fabric we discussed in the Combining MLAG Clusters with VXLAN Fabric blog post:
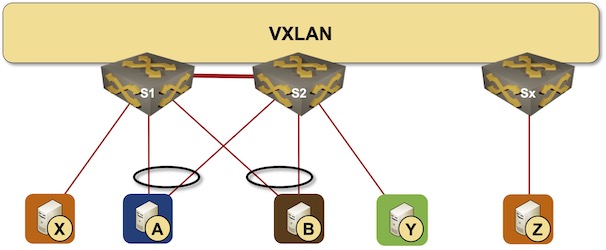
MLAG cluster connected to a VXLAN fabric
Now assume that S1 and S2 use different VTEP IP addresses (please note that the details are way more convoluted than the following simplified explanation):
- S1 and S2 advertise an ESI based on the LACP System ID of host A (ESI-A).
- S1 advertises MAC-A with ESI-A and VTEP-A as the VXLAN next hop.
- S2 doesn’t have to advertise MAC-A (although it could do so) – every other PE device knows that S1 and S2 serve the same Ethernet segment and that they could use either to reach MAC-A.
So far, so good. Now for the wrench in the works: while almost all IP forwarding tables support multiple entries for the same IP prefix, the same trick cannot be used in MAC forwarding table. Using more than one entry for the same MAC address in the MAC forwarding table results in (multicast) flooding across specified outgoing interfaces.
Software-based forwarding is relatively easy to fix: FRR uses nexthop objects to implement ECMP across multiple VTEPs (see comment by TA). TA claims a similar forwarding structure is used by Mellanox ASICs, and according to DM, “all vendors have some working implementation of this.”
According to Junos Dynamic Load Balancing in an EVPN-VXLAN Network, Juniper implemented nexthop objects for VTEP load balancing in all QFX switches, including the old QFX5100 that uses Broadcom Trident II chipset. OTOH, there’s a blog post from a non-Juniper JNCIE describing the EVPN/ESI limitations of QFX-series switches and claiming that “This behavior is well documented and there are some talks about Broadcom working with the vendors to improve gateway load-balancing with ESI functionality.” (HT: Daniel)
Does that mean that VXLAN-enabled ASICs always supported this functionality but it took Broadcom and networking vendors years to implement it? I guess we’ll never know due to the wonderful Broadcom documentation policy, but if you have lab results proving that traffic from a single ingress switch toward a single MLAG-connected MAC address gets distributed across a pair of egress switches I’d be glad to know about them.
In the meantime, some vendors (example: Cisco) keep using anycast VTEP IP addresses described in the Combining MLAG Clusters with VXLAN Fabric blog post with EVPN control plane. Yet again, I can’t comment whether that’s due to hardware limitations, code reuse, or backward compatibility.
Anyway, even when using anycast IP address, using EVPN as the control plane protocol instead of dynamic MAC learning does provide a significant benefit – the egress PE devices can advertise whatever next hop they wish in the MAC+IP update messages. An EVPN/VXLAN MLAG implementation could use this functionality to differentiate between multihomed and orphan nodes:
- MAC addresses of orphan nodes are advertised with unicast VTEP IP address
- Members of an MLAG cluster advertise the MAC addresses of multihomed nodes with the shared anycast VTEP IP address.
While the above solution works great in a steady state, any single link failure might turn a multihomed node into an orphan node, triggering an interesting sequence of update messages (the details are left as an exercise for the reader).
Once you implement proxy ARP and anycast gateway, you can go one step further: advertise MAC+IP information with anycast VTEP IP address and add an IP prefix (EVPN RT5) for the node IP address (a /32 or /128 prefix) with the unicast VTEP IP address. IP traffic is thus load-balanced between unicast VTEP IP addresses while MAC-based forwarding uses the anycast VTEP IP address.
Coming back to the “EVPN multihoming makes MLAG obsolete” myth: for every complex problem, there’s a solution that is simple, neat, and wrong (and works best in PowerPoint). MLAG is no exception.
Next: MLAG Clusters without a Physical Peer Link Continue
Revision History
- 2022-11-10
- Rewritten the “MAC load balancing” section based on readers’ comments.
Thanks! This answer some questions I've had for a long time.
The other question I have had is how does failover speed compare when a link is lost in EVPN ESI MLAG versus LACP? And is there a control mechanism to detect a bad link that still has link status but is not forwarding like the LACP heartbeats?
... and you gave me a topic for another blog post ;) Thank you!
Long story short:
"However, the forwarding hardware limitations require anycast VTEP IP addresses"
I can't comment on how other implementations work, but FRR/Cumulus implementation of MAC-ECMP does not fallback on anycast. What you said about forwarding hardware requiring a single destination for a MAC is accurate, but their implementation achieves MAC-ECMP by pointing the fdb entry (mac) at single destination that is an ECMP container holding the VTEP address of each member of the remote ESI rather than pointing to a single VTEP address.
In Linux, the ECMP container is implemented using "nexthop" objects (one nexthop "group" pointing to several nexthop entries). FRR populates an ES cache based on "per ES" Type-1 routes, which maintains a list of active VTEP addresses per ESI. One NHG is allocated in the kernel per known ESI and one NHE is allocated per active VTEP. When a MAC is learned via the remote ESI, the VXLAN driver's fdb entry points to the ID of the nexthop group ("nhid") for a hash lookup to select which underlay DIP will be used.
In Mellanox ASICs the same principle applies - an ECMP container is allocated based on the kernel NHG and it contains underlay VTEP addresses. So the hardware fdb points to the ECMP container to select a remote underlay DIP for the VXLAN tunnel (not anycast) and then the encapsulated packet goes through the route lookup based on the DIP returned by the ECMP hash lookup.
JunOS also implements ECMP with underlay/overlay networks. I think all vendors have some working implementation of this. Not sure why Ivan isn't aware of that.
JunOS adds multiple entries to a unilist, then an indirect next hop list, then finally a chained composite next hop list (when using EVPN-VXLAN).
Most of the complaints in this blog are a non-issue.
@DM: I believe that's true for MX/QFK10K/vMX/vQFX, but not for the older Trident2/2+/Tomahawk-based boxes (i.e. QFX5100/5110/5200). Afaik, those can only loadbalance in the underlay, not the overlay.
See for example this (albeit older) whitepaper: https://www.juniper.net/documentation/en_US/release-independent/solutions/information-products/pathway-pages/lb-evpn-vxlan-tn.pdf
Or this blog: https://danhearty.wordpress.com/2020/04/25/evpn-vxlan-virtual-gateway-qfx5k-forwarding/
@Daniel/Ivan I believe those assumptions are outdated.
See release notes at bottom of this page: https://www.juniper.net/documentation/us/en/software/junos/evpn-vxlan/topics/concept/evpn-vxlan-dynamic-load-balancing.html
Thank you both. Rewrote the blog post based on your comments.
@DM: I'm positive MX works as described. I remain skeptical about the older Broadcom ASICs, but whatever.
Significant cost uplift to license switches to build EVPN DC fabric as compared to MLAG which is base feature on any DC class switch.