Use VRFs for VXLAN-Enabled VLANs
I started one of my VXLAN tests with a simple setup – two switches connecting two hosts over a VXLAN-enabled (gray tunnel) red VLAN. The switches are connected with a single blue link.
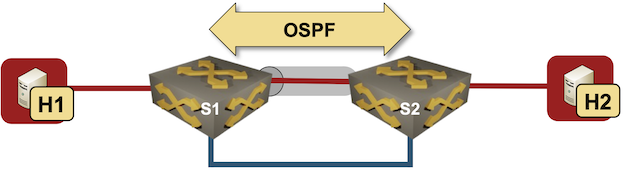
Test lab
I configured VLANs and VXLANs, and started OSPF on S1 and S2 to get connectivity between their loopback interfaces. Here’s the configuration of one of the Arista cEOS switches:
vlan 1000
name red
!
interface Ethernet1
switchport access vlan 1000
!
interface Ethernet2
description s1 -> s2
no switchport
ip address 10.1.0.1/30
ip ospf cost 20
!
interface Loopback0
ip address 10.0.0.1/32
!
interface Vlan1000
description VLAN red (1000) -> [h1,h2,s2]
ip address 172.16.0.1/24
!
interface Vxlan1
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 1000 vni 101000
vxlan vlan 1000 flood vtep 10.0.0.2
!
router ospf 1
network 0.0.0.0/0 area 0.0.0.0
max-lsa 12000
log-adjacency-changes detail
Everything looked fine, OSPF adjacencies where there, but the hosts weren’t able to ping each other.
Try to figure out what the problem is before moving on.
Gave up? Next hint: the switches would periodically generate weird OSPF messages – it looked like an adjacency would time out and be immediately reestablished. That weird event happened almost exactly every 40 seconds.
Oct 22 11:49:57 s1 Ospf: Instance 1: %OSPF-4-OSPF_ADJACENCY_TEARDOWN: NGB 10.0.0.2, interface 172.16.0.1 adjacency dropped: inactivity timer expired, state was: FULL
Oct 22 11:49:57 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <FULL> to <DOWN>
Oct 22 11:50:07 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <DOWN> to <DOWN>
Oct 22 11:50:07 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <DOWN> to <INIT>
Oct 22 11:50:07 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <INIT> to <2 WAYS>
Oct 22 11:50:07 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <2 WAYS> to <EXCH START>
Oct 22 11:50:12 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <EXCH START> to <EXCHANGE>
Oct 22 11:50:12 s1 Ospf: Instance 1: %OSPF-4-OSPF_STATE_CHANGE: NGB 10.0.0.2, intf 172.16.0.2 change from <EXCHANGE> to <FULL>
Oct 22 11:50:12 s1 Ospf: Instance 1: %OSPF-4-OSPF_ADJACENCY_ESTABLISHED: NGB 10.0.0.2, interface 172.16.0.1 adjacency established
Figured it out? Not yet? OK, here we go…
Just In Case You Gave Up ;)
Some of us learned the lesson the hard way1 when building networks transporting weird protocols over GRE tunnels: running the same routing protocol in the underlay and over the tunnel might not be the best idea you ever had.
VXLAN is a tunnel like any other tunnel2 and when you run the same routing protocol across the physical network and on a VXLAN-enabled VLAN interface you sometimes get the results you deserve. Just because you’re working with data center switches instead of with traditional routers doesn’t mean that you can ignore the realities of routing.
In my lab, S1:
- Established OSPF sessions with S2 over physical interfaces and VLAN interfaces
- Figured out that it’s best to use the VLAN interfaces to send the traffic to S2 loopback IP address3.
- Tried to encapsulate VLAN traffic into VXLAN and send that VXLAN packet over VLAN.
Due to the delay between initial database exchange and the SPF run, the OSPF adjacency got completely formed before the routing tables were messed up, and the routers only gave up after the dead interval.
Once the OSPF adjacency was gone, VXLAN traffic started flowing over the physical interface, VXLAN-encapsulated OSPF hellos (for Vlan1000 interface) were successfully exchanged between S1 and S2, and the whole network got bricked for another 40 seconds.
Solutions
Here are a few ideas:
- It might be a bad idea to use network 0.0.0.0/0 area 0 OSPF router configuration command if you want to have any control over what’s going on in your network4. Enabling OSPF on individual interfaces gives you better control.
- You could enable OSPF just on the physical interfaces and redistribute connected routes into OSPF.
- You could also enable OSPF everywhere (to avoid route redistribution) and make VLAN interfaces passive.
However, by far the best solution (if it fits into your design) is to use VRFs for VLAN interfaces. That achieves clean separation between overlay (tenant) traffic and underlay (transport) traffic. It also makes it impossible to mess up the transport network with tenant routing information, which is effectively what we did.
Build Your Own
Want to repeat the experiment?
- Install netlab on a Ubuntu host or VM
- Install Ansible, Docker and containerlab on that host
- Download Arista cEOS container
- Download the netlab topology file into an empty directory and execute netlab up
- Enjoy the show
The netlab topology files are in my GitHub repository:
-
Sometimes bricking a large network ;) ↩︎
-
Even though it transports Ethernet frames not IP packets over IP network ↩︎
-
I used OSPF cost to force that behavior. Inserting another switch between S1 and S2 would have the same effect. ↩︎
-
I used it in my lab because it would be too easy to spot the ip ospf area 0 command on the VLAN interface. Also, I’m using netlab to build labs, and get OSPF enabled on individual interfaces by default. ↩︎