Blog Posts in October 2022
Worth Exploring: NetTowel
A few months ago, Urs Baumann created NetTowel, a very nice CLI wrapper around several popular libraries, including Jinja2, TTP, NetMiko and netaddr. Although it seems he got busy with other things in recent months, and the development stalled a bit, the tool is definitely worth exploring.
Could I Use netlab instead of GNS3?
I’m often getting questions like “I’m using GNS3. Could I replace it with netlab?”
TL&DR: No.
You need a set of functions to build a network lab:
- Virtualization environment (netlab supports VirtualBox, libvirt, Docker, and Podman)
- An orchestration tool/system that will deploy network device images in such an environment (netlab supports Vagrant and containerlab)
- A tool that will build orchestration system configuration (netlab core functionality)
Leave BGP Next Hops Unchanged on Reflected Routes
Here’s the last question I’ll answer from that long list Daniel Dib posted weeks ago (answer to Q1, answer to Q2).
I am trying to understand what made the BGP designers decide that RR should not change the BGP Next Hop for IBGP-learned routes.
History of Ethernet Encapsulations
Henk Smit conscientiously pointed out a major omission I made when summarizing Peter Paluch’s excellent description of how bits get parsed in network headers:
EtherType? What do you mean EtherType? There are/were 4 types of Ethernet encapsulation. Only one of them (ARPA encapsulation) has an EtherType. The other 3 encapsulations do not have an EtherType field.
What is he talking about? Time for another history lesson1.
Network Automation Considered Harmful
Some of the blog comments never cease to amaze me. Here’s one questioning the value of network automation:
I think there is a more fundamental reason than the (in my opinion simplistic) lack of skills argument. As someone mentioned on twitter
“Rules make it harder to enact change. Automation is essentially a set of rules.”
We underestimated the fact that infrastructure is a value differentiator for many and that customization and rapid change don’t go hand in hand with automation.
Whenever someone starts using MBA-speak like value differentiator in a technical arguments, I get an acute allergic reaction, but maybe he’s right.
Use VRFs for VXLAN-Enabled VLANs
I started one of my VXLAN tests with a simple setup – two switches connecting two hosts over a VXLAN-enabled (gray tunnel) red VLAN. The switches are connected with a single blue link.
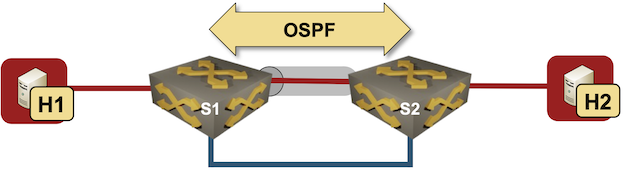
Test lab
I configured VLANs and VXLANs, and started OSPF on S1 and S2 to get connectivity between their loopback interfaces. Here’s the configuration of one of the Arista cEOS switches:
Video: EVPN Multihoming Taxonomy and Overview
I promised you a blog post explaining the intricacies of implementing MLAG with EVPN, but (as is often the case) it’s taking longer than expected. In the meantime, enjoy the EVPN Multihoming Taxonomy and Overview video from Lukas Krattiger’s EVPN Multihoming versus MLAG presentation (part of EVPN Deep Dive webinar).
New Webinar: Internet Routing Security
I’m always in a bit of a bind when I get an invitation to speak at a security conference (after all, I know just enough about security to make a fool of myself), but when the organizers of the DEEP Conference invited me to talk about Internet routing security I simply couldn’t resist – the topic is dear and near to my heart, and I planned to do a related webinar for a very long time.
Even better, that conference would have been my first on-site presentation since the COVID-19 craze started, and I love going to Dalmatia (where the conference is taking place). Alas, it was not meant to be – I came down with high fever just days before the conference and had to cancel the talk.
Why Do We Need IBGP Full Mesh?
Here’s another question from the excellent list posted by Daniel Dib on Twitter:
BGP Split Horizon rule says “Don’t advertise IBGP-learned routes to another IBGP peer.” The purpose is to avoid loops because it’s assumed that all of IBGP peers will be on full mesh connectivity. What is the reason the BGP protocol designers made this assumption?
Time for another history lesson. BGP was designed in late 1980s (RFC 1105 was published in 1989) as a replacement for the original Exterior Gateway Protocol (EGP). In those days, the original hub-and-spoke Internet topology with NSFNET core was gradually replaced with a mesh of interconnections, and EGP couldn’t cope with that.
… updated on Thursday, October 20, 2022 13:54 UTC
On Applicability of MPLS Segment Routing (SR-MPLS)
Whenever I compare MPLS-based Segment Routing (SR-MPLS) with it’s distant IPv6-based cousin (SRv6), someone invariably mentions the specter of large label stacks that some hardware cannot handle, for example:
Do you think vendors current supported label max stack might be an issue when trying to route a packet from source using Adj-SIDs on relatively big sized (and meshed) cores? Many seem to be proposing to use SRv6 to overcome this.
I’d dare to guess that more hardware supports MPLS with decent label stacks than SRv6, and if I’ve learned anything from my chats with Laurent Vanbever, it’s that it sometimes takes surprisingly little to push the traffic into the right direction. You do need a controller that can figure out what that little push is and where to apply it though.
netlab Router-on-a-Stick Example
In early June 2022 I described a netlab topology using VLAN trunks in netlab. That topology provided pure bridging service for two IP subnets. Now let’s go a step further and add a router-on-a-stick:
- S1 and S2 are layer-2 switches (no IP addresses on red or blue VLANs).
- ROS is a router-on-a-stick routing between red and blue VLANs.
- Hosts on red and blue VLANs should be able to ping each other.

Lab topology
netlab Release 1.3.3: Bug Fixes
Just FYI: I pushed out netlab release 1.3.3 yesterday. It’s a purely bug fix release, new functionality and a few breaking changes are coming in release 1.4 in a few weeks.
Some of the bugs we fixed weren’t exactly pleasant; if you’re using release 1.3.2 you might want to upgrade with pip3 install --upgrade networklab.
EVPN VLAN-Aware Bundle Service
In the EVPN/MPLS Bridging Forwarding Model blog post I mentioned numerous services defined in RFC 7432. That blog post focused on VLAN-Based Service Interface that mirrors the Carrier Ethernet VLAN mode.
RFC 7432 defines two other VLAN services that can be used to implement Carrier Ethernet services:
- Port-based service – whatever is received on the ingress port is sent to the egress port(s)
- VLAN bundle service – multiple VLANs sharing the same bridging table, effectively emulating single outer VLAN in Q-in-Q bridging.
And then there’s the VLAN-Aware Bundle Service, where a bunch of VLANs share the same MPLS pseudowires while having separate bridging tables.
OSPF External Routes (Type-5 LSA) Mysteries
Daniel Dib posted a number of excellent questions on Twitter, including:
While forwarding a received Type-5 LSA to other areas, why does the ABR not change the Advertising Router ID to it’s own IP address? If ABR were able to change the Advertising Router ID in the Type-5 LSA, then there would be no need for Type-4 LSA which meant less OSPF overhead on the network.
TL&DR: The current implementation of external routes in OSPF minimizes topology database size (memory utilization)
Before going to the details, try to imagine the environment in which OSPF was designed, and the problems it was solving.
Cumulus Linux NVUE: an Incomplete Data Model
A few weeks ago I described how Cumulus Linux tried to put lipstick on a pig reduce the Linux data plane configuration pains with Network Command Line Utility. NCLU is a thin shim that takes CLI arguments, translates them into FRR or ifupdown configuration syntax, and updates the configuration files (similar to what Ansible is doing with something_config modules).
Obviously that wasn’t good enough. Cumulus Linux 4.4 introduced NVIDIA User Experience1 – a full-blown configuration engine with its own data model and REST API2.
netlab Release 1.3.2: Mikrotik RouterOS 7, Additional EVPN Platforms
The star of the netlab release 1.3.2 is Mikrotik RouterOS version 7. Stefano Sasso did a fantastic job adding support for VLANs, VRFs, OSPFv2, OSPFv3, BGP, MPLS, and MPLS/VPN, plus the libvirt box-building recipe.
Jeroen van Bemmel contributed another major PR1 adding VLANs, VRFs, VXLAN, EVPN, and OSPFv3 to Nokia SR OS.
Other platform improvements include:
Worth Reading: VXLAN Drops Large Packets
Ian Nightingale published an interesting story of connectivity problems he had in a VXLAN-based campus network. TL&DR: it’s always the MTU (unless it’s DNS or BGP).
The really fun part: even though large L2 segments might have magical properties (according to vendor fluff), there’s no host-to-network communication in transparent bridging, so there’s absolutely no way that the ingress VTEP could tell the host that the packet is too big. In a layer-3 network you have at least a fighting chance…
Video: Traffic Filtering in the Age of IPv6
Christopher Werny covered another interesting IPv6 security topic in the hands-on part of IPv6 security webinar: traffic filtering in the age of dual-stack and IPv6-only networks, including filtering extension headers, filters on Internet uplinks, ICMPv6 filters, and address space filters.
… updated on Thursday, November 3, 2022 16:36 UTC
More Arista EOS BGP Route Reflector Woes
Most BGP implementations I’ve worked with split the neighbor BGP configuration into two parts:
- Global configuration that creates the transport session
- Address family configuration that activates the address family across a configured transport session and changes the parameters that affect BGP updates
AS numbers, source interfaces, peer IPv4/IPv6 addresses, and passwords clearly belong to the global neighbor configuration.
EVPN/MPLS Bridging Forwarding Model
Most networking engineers immediately think about VXLAN and data center switches when they hear about EVPN. While that’s the most hyped use case, EVPN standardization started in 2012 as a layer-2 VPN solution on top of MPLS transport trying to merge the best of VPLS and MPLS/VPN worlds.
If you want to understand how any technology works, and what its quirks are, you have to know how it was designed to be used. In this blog post we’ll start that journey exploring the basics of EVPN used in a simple MLPS network with three PE-routers:
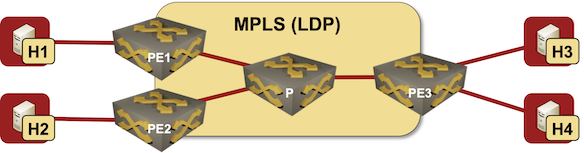
Lab topology
Repost: What's Wrong with Network Automation
Responding to my Infrastructure as Code Sounds Scary blog post, Deepak Arora posted an interesting (and unfortunately way too accurate) list of challenges you might encounter when trying to introduce network automation in an enterprise environment.
He graciously allowed me to repost his thoughts on my blog.
Why don’t we agree on that :
netlab EVPN/VXLAN Bridging Example
netlab release 1.3 introduced support for VXLAN transport with static ingress replication and EVPN control plane. Last week we replaced a VLAN trunk with VXLAN transport, now we’ll replace static ingress replication with EVPN control plane.
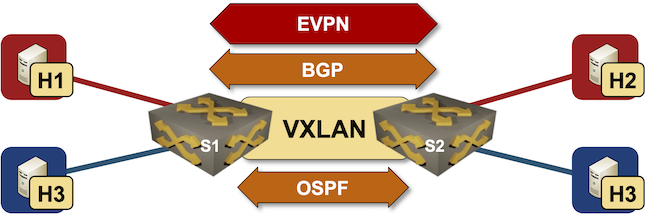
Lab topology
Worth Reading: QUIC Is Not a TCP Replacement
Bruce Davie makes an excellent point in his QUIC Is Not a TCP Replacement article – QUIC not a next-generation TCP, it’s a reliable RPC transport protocol.
What Bruce forgot to mention is that we had a production-grade RPC transport protocol for years – SCTP (Stream Control Transmission Protocol) – but it had two shortcomings:
- It wasn’t invented by the right people;
- It used a different IP protocol number and thus upset every ossified middlebox in the Internet. QUIC hides on top of UDP (because adding extra headers makes at least as much sense as junk DNA).
Worth Reading: EVPN/VXLAN with FRR on Linux Hosts
Jeroen Van Bemmel created another interesting netlab topology: EVPN/VXLAN between SR Linux fabric and FRR on Linux hosts based on his work implementing VRFs, VXLAN, and EVPN on FRR in netlab release 1.3.1.
Bonus point: he also described how to do multi-vendor interoperability testing with netlab.
If only he wouldn’t be publishing his articles on a platform that’s almost as user-data-craving as Google.