Segment Routing vs LDP in Hub-and-Spoke Networks
I got an interesting question that nicely illustrates why Segment Routing (the MPLS variant) is so much better than LDP. Imagine a redundant hub-and-spoke network with hundreds of spokes. Let’s settle on 500 spokes – IS-IS supposedly has no problem dealing with a link-state topology of that size.
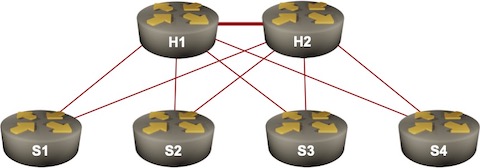
Let’s further assume that all routers advertise only their loopbacks1 and that we’re using unnumbered hub-to-spoke links to minimize the routing table size. The global routing table thus contains ~500 entries. MPLS forwarding tables (LFIB) contain approximately as many entries as each router assigns a label to every prefix in the routing table2. What about the LDP table (LIB – Label Information Base)?
The LIB tables on spokes contain ~1000 entries – each hub router is advertising it label bindings for all entries in its forwarding table. So far so good. What about the LIB tables on the hub routers? They contain 250.000 entries – each spoke router is advertising its 500 label bindings to both hubs even though we never want to use spokes as transit routers between hubs.
Now let’s assume we use numbered hub-to-spoke links. The routing table size increases to 1500 entries (peanuts), the hub LIB size increases to 750.000 entries.
A knee-jerk reaction could be to “fix” the LDP behavior with downstream-on-demand allocation, but keep in mind there’s a reason for the default behavior: after a topology change, all routers already have the labels from the new downstream neighbors because everyone assigns and advertises a label to everything just in case it might be needed. After a careful consideration, you might decide to use unsolicited downstream allocation on hub routers and downstream-on-demand on spokes3, and reduce the LIB size by orders of magnitude.
You might also fine-tune the LDP label allocation on the spoke routers (don’t assign labels to other spokes) or LDP label advertisement (don’t advertise labels for other spokes to the hub routers), but you just piled layers of kludges on top of a suboptimal4 network design. Segment routing is ridiculously simple compared to all that:
- No need for LDP – labels are advertised in IGP together with IP prefixes
- No LDP-to-IGP synchronization headaches.
- No black holes or broken LSPs after link reestablishement
- No LIB scaling issues
- Single label per device (unless you configure adjacency SIDs)
There’s just a tiny little detail: you have to configure segment identifiers on all devices, but then you have to configure loopbacks as well, and you wanted to automate device configuration builds and deployments anyway, right?
Or maybe I’m just overreacting and solving imaginary scaling problems at scale? Leave a comment!
More Information
You probably know there are tons of good MPLS books out there; you might also want to watch these webinars:
In 2014 when I did the first prototype implementation of MPLS-SR node labels, I was stunned that just with an incremental add of 500 Lines of code to the vanilla ipv4/ipv6 IS-IS codebase I got full any-to-any connectivity, no sync issues, no targeted sessions for R-LFA .... essentially labeled transport comes for free. Later I did ask George Swallow and Yakov Rekhter (The original MPLS design team) "Why did you not do this right from the start ?" and the answer was not pretty: "IGPs have been done in San Jose and the MPLS design team was mostly located in the Boxborough office. At the time there was lots of stability issues with IGPs and management has asked us not to touch any IGP code"
(Besides, there was only one good programmer in Boston: Dan Tappan. Everybody else there was an "architect". I don't believe east-coast would have done better.
The issue is much simpler. UUnet and iMCI were designing their new backbones with routers at the edge, and all Fore ATM switches in the middle. That was a $100M market that cisco was losing out on. At the same time, Ipsilon came with their proprietary technology with some flow-based, connection-oriented, doing IP-packet switching over ATM circuits. Lots of people at ISPs (and even at the IETF) loved the idea of having circuits. Old telephone people never change.
So Yakhov came with MPLS (first called tag-switching). It was basically the idea of using connections (LSPs) to compete with Fore and Ipsilon. And nobody thought of doing "connectionless labels". That is how we ended up with LDP and TE-RSVP. Because the people who made the purchasing decisions, and the VCs that invested in new technology, all wanted connection-oriented technology. And then BGP-MPLS-VPNs came. Another crappy idea. But it allowed ISPs to "sell a managed service". Another reason why ISPs wanted MPLS.
Yakhov once told me that they seriously thought about using the existing source-routing IP-header option. They decided to not use it, because IP-options had a bad rep. If have often thought: "I wish they had done TE via IP-source-routing". I guess we got it after all, we just call it SRv6 now. :)
The simple fact is, when MPLS came about, nobody thought of doing "connectionless labels". I guess the connection-oriented mind-set was still active in many people.
Hi Henk, great piece of history info there :)) ! Can you also tell me why you consider BGP-MPLS-VPN a crap idea? I always value your thoughts, so would like to hear your reasons very much.
For such a simple network you could also use LISP or VRF-light or something else. One implementation example is SDA.
MPLS is designed for large WAN networks, where you have a lot of P (core routers) in a complex topology. Then you can spare resources by having BGP free LSRs. If you have only two P routers, MPLS is a total overkill and not needed. MPLS is not the optimum solution for DC or LAN network.
> If you have only two P routers, MPLS is a total overkill and not needed.
Unless you need MPLS-based services like VPLS (which was the original use case in this scenario) or need many VPNs. VRF Lite works well only for a very limited set number of VPNs.
Would there be any scale/complexity based argument for/against SRv6 in this context?
(i.e. besides local preference)
MPLS-SR as an LDP replacement makes perfect sense, and as Hannes notes, IGP distribution of labels is probably how it should have been done in the first place. MPLS-SR for traffic engineering though is debatable, there are many tradeoffs in the goal to reduce 'network state', if one thinks control plane state is a problem and label stack depth si constraints is not a problem. Turns out that state information is pretty helpful in simulating scenarios for network resiliency, or troubleshooting when the s*it hits the fan.
Good point regarding state information being helpful in troubleshooting. But what about the scale limitations in the MID points? With SR-TE MID points doesn't need scale like RSVP. To address the label stack depth issues knobs are there to limit the depth of stack like anycast SID.
there's no free lunch here. use of anycast SIDs means that you're going to lose some degree of explicit path control and you're going to lose visibility into the nature of the flows from a diagnostic perspective if you need to figure out how you want to rebalance traffic.
it turns out that control-plane state that can be correlated to interfaces (and their load) is actually really useful. it's really important to know the tradeoffs you're working with.
Carrying label inside LGP is natural and therefore, makes perfect sense and is much better than using LDP; it also simplifies the network and reduces the number of moving parts. For that reason, I think it should be implemented independent of SR.
If we have that feature, and implement valley-free routing policy -- which is easier done in DV than LS protocols due to the nature of DV -- than we can limit the number of entries at the hubs without using SR, IMO.
Or you could configure per-vrf label mode?
Hi Minh,
> I always value your thoughts
Thanks. But maybe you shouldn't. :) I am just another idiot with an opinion. I have been out of the industry for a long time (over a decade). And my practical knowledge about today's real networks is limited. (Hopefully that'll change in the next 2 years).
> why
Because I think BGP-MPLS-VPNs are over-complicated. And you don't get enough return for that extra complexity. Note, I think that about a lot of technologies. I like simple, I like elegant. And I think vendors should focus on optimizing their implementations. In stead of throwing in new features and new protocol extensions. Same thing about providers: imho they should focus on simplifying their designs, and getting rid of obscure features, in stead of asking for more.
(Ivan likes to complain about vendors introducing more technological complexity. But imho the providers are worse. They ask for these knobs and stuff. And once it is in, you can never take it out. And once one vendors does it, all vendors need to implement it. You wouldn't believe the nonsense I've heard some ISPs ask for).
If I ever get to do job-interviews again (not as an applicant, I'm staying put), one of my questions will be: "what is your favorite rule from rfc1925". FYI, mine is rule 12.
Another factor related to BGP-MPLS-VPNs is that I don't like the basic design. The Internet became a success because of a number of design principles. One is: "dumb network, smart hosts". We, as an industry, sometimes forget about those basic principles. BGP-MPLS-VPNs are the opposite of this. I understand why, because if gives an opportunity for ISPs to sell a service. But imho, large VPNs should be done by the customers themselves, on their equipment. Like DMVPNs and other SD-WAN technologies.