Unequal-Cost Multipath with BGP DMZ Link Bandwidth
In the previous blog post in this series, I described why it’s (almost) impossible to implement unequal-cost multipathing for anycast services (multiple servers advertising the same IP address or range) with OSPF. Now let’s see how easy it is to solve the same challenge with BGP DMZ Link Bandwidth attribute.
I didn’t want to listen to the fan noise generated by my measly Intel NUC when simulating a full leaf-and-spine fabric, so I decided to implement a slightly smaller network:
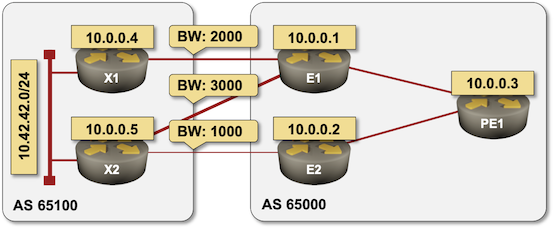
X1 and X2 are Cisco IOS devices advertising the same prefix – 10.42.42.0/24. E1 and E2 have the same function as the ToR switches in a leaf-and-spine fabric with a slight twist: every link between AS 65000 and AS 65001 has a different bandwidth. PE1 is an equivalent of a spine switch in a leaf-and-spine fabric.
After we get BGP and OSPF up and running, E1 receives two copies of 10.42.42.0/24 prefix (one from X1 and another one from X2), but it only uses one of them for packet forwarding.
e1#sh ip bgp 10.42.42.0
BGP routing table entry for 10.42.42.0/24, version 2
Paths: (2 available, best #1, table default)
Advertised to update-groups:
1 2
Refresh Epoch 1
65100
10.1.0.10 from 10.1.0.10 (10.0.0.4)
Origin IGP, metric 0, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 2
65100
10.1.0.14 from 10.1.0.14 (10.0.0.5)
Origin IGP, metric 0, localpref 100, valid, external
rx pathid: 0, tx pathid: 0
e1#sh ip route 10.42.42.0
Routing entry for 10.42.42.0/24
Known via "bgp 65000", distance 20, metric 0
Tag 65100, type external
Last update from 10.1.0.10 00:00:45 ago
Routing Descriptor Blocks:
* 10.1.0.10, from 10.1.0.10, 00:00:45 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 65100
MPLS label: none
The caveat: default value of BGP maximum-paths on Cisco IOS is one. After changing that to eight (because why not), E1 uses both prefixes… but in 1:1 ratio.
e1#sh ip route 10.42.42.0
Routing entry for 10.42.42.0/24
Known via "bgp 65000", distance 20, metric 0
Tag 65100, type external
Last update from 10.1.0.14 00:00:05 ago
Routing Descriptor Blocks:
10.1.0.14, from 10.1.0.14, 00:00:05 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 65100
MPLS label: none
* 10.1.0.10, from 10.1.0.10, 00:00:05 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 65100
MPLS label: none
Time to enter the magical world of DMZ Link Bandwidth. We have to configure:
- neighbor dmzlink-bw on all EBGP neighbors to attach DMZ Link Bandwidth extended BGP community to all BGP prefixes received from EBGP neighbors1.
- bgp dmzlink-bw within an address family to use the link bandwidth extended community to calculate traffic shares.
router bgp 65000
!
address-family ipv4
bgp dmzlink-bw
neighbor 10.1.0.10 dmzlink-bw
neighbor 10.1.0.14 dmzlink-bw
maximum-paths 8
After configuring DMZ Link Bandwidth on E1 and E2, you’ll notice additional communities attached to BGP prefix 10.42.42.0/24… and a modified traffic share on E1 (E2 has only one link into AS 65001).
e1#show ip bgp 10.42.42.0
BGP routing table entry for 10.42.42.0/24, version 5
Paths: (2 available, best #1, table default)
Multipath: eBGP iBGP
Advertised to update-groups:
1 2
Refresh Epoch 2
65100
10.1.0.10 from 10.1.0.10 (10.0.0.4)
Origin IGP, metric 0, localpref 100, valid, external, multipath, best
DMZ-Link Bw 250 kbytes
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 3
65100
10.1.0.14 from 10.1.0.14 (10.0.0.5)
Origin IGP, metric 0, localpref 100, valid, external, multipath(oldest)
DMZ-Link Bw 375 kbytes
rx pathid: 0, tx pathid: 0
e1#show ip route 10.42.42.0
Routing entry for 10.42.42.0/24
Known via "bgp 65000", distance 20, metric 0
Tag 65100, type external
Last update from 10.1.0.14 00:01:43 ago
Routing Descriptor Blocks:
10.1.0.14, from 10.1.0.14, 00:01:43 ago
Route metric is 0, traffic share count is 3
AS Hops 1
Route tag 65100
MPLS label: none
* 10.1.0.10, from 10.1.0.10, 00:01:43 ago
Route metric is 0, traffic share count is 2
AS Hops 1
Route tag 65100
MPLS label: none
Now for a sprinkle of Pure Magic™ – let’s inspect the BGP table and IP routing table on PE1 without doing anything else but configuring maximum-paths and bgp dmzlink-bw on it:
pe1#show ip bgp 10.42.42.0
BGP routing table entry for 10.42.42.0/24, version 9
Paths: (2 available, best #1, table default)
Multipath: eBGP iBGP
Advertised to update-groups:
1
Refresh Epoch 1
65100, (Received from a RR-client)
10.0.0.1 (metric 2) from 10.0.0.1 (10.0.0.1)
Origin IGP, metric 0, localpref 100, valid, internal, multipath, best
DMZ-Link Bw 625 kbytes
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 3
65100, (Received from a RR-client)
10.0.0.2 (metric 2) from 10.0.0.2 (10.0.0.2)
Origin IGP, metric 0, localpref 100, valid, internal, multipath(oldest)
DMZ-Link Bw 125 kbytes
rx pathid: 0, tx pathid: 0
The 10.42.42.0/24 prefix received from E2 contains the expected DMZ Link Bandwidth (1000 kbps), while the prefix received from E1 contains the sum of all DMZ Link Bandwidths in E1 BGP table, resulting in perfect UCMP traffic ratio. Problem solved.
pe1#show ip route 10.42.42.0
Routing entry for 10.42.42.0/24
Known via "bgp 65000", distance 200, metric 0
Tag 65100, type internal
Last update from 10.0.0.2 00:11:18 ago
Routing Descriptor Blocks:
10.0.0.2, from 10.0.0.2, 00:11:18 ago
Route metric is 0, traffic share count is 23
AS Hops 1
Route tag 65100
MPLS label: none
* 10.0.0.1, from 10.0.0.1, 00:11:18 ago
Route metric is 0, traffic share count is 120
AS Hops 1
Route tag 65100
MPLS label: none
Unfortunately, there’s always another twist in every saga. While the IP routing table entry on PE1 looks great, and the overview part of the CEF table entry looks equally impressive…
pe1#sh ip cef 10.42.42.0/24 internal
10.42.42.0/24, epoch 2, flags [rnolbl, rlbls], RIB[B], refcnt 6...
sources: RIB
feature space:
IPRM: 0x00018000
Broker: linked, distributed at 4th priority
ifnums:
GigabitEthernet2(8): 10.1.0.1
GigabitEthernet3(9): 10.1.0.5
path list 7F72505C4090, 3 locks, per-destination, flags 0x269
path 7F724DEDA0D8, share 23/23, type recursive, for IPv4
recursive via 10.0.0.2[IPv4:Default], fib 7F72AE3E3B88, 1 terminal fib...
path list 7F72505C4130, 3 locks, per-destination, flags 0x49 [shble, rif, hwcn]
path 7F724DEDA4F8, share 1/1, type attached nexthop, for IPv4
nexthop 10.1.0.5 GigabitEthernet3, IP adj out of GigabitEthernet3...
path 7F724DEDA448, share 120/120, type recursive, for IPv4
recursive via 10.0.0.1[IPv4:Default], fib 7F72AE3E3C88, 1 terminal fib...
path list 7F72505C4270, 3 locks, per-destination, flags 0x49 [shble, rif, hwcn]
path 7F724DEDA658, share 1/1, type attached nexthop, for IPv4
nexthop 10.1.0.1 GigabitEthernet2, IP adj out of GigabitEthernet2...
… the hashing buckets don’t reflect the desired traffic sharing. The traffic is sent toward E1 and E2 in 8:8 (i.e. 1:1) ratio. Bummer.
output chain:
loadinfo 80007F72AF328F60, per-session, 2 choices, flags 0003, 5 locks
flags [Per-session, for-rx-IPv4]
16 hash buckets
< 0 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
< 1 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
< 2 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
< 3 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
< 4 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
< 5 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
< 6 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
< 7 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
< 8 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
< 9 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
<10 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
<11 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
<12 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
<13 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
<14 > IP adj out of GigabitEthernet3, addr 10.1.0.5 7F7249F23E20
<15 > IP adj out of GigabitEthernet2, addr 10.1.0.1 7F7249F24010
If you want to reproduce my results, you’ll find the lab topology and configuration files on GitHub.
Back to Leaf-and-Spine Fabrics
Can we use the same trick in a leaf-and-spine fabric? Absolutely. Figuring out how to apply these concepts to leaf-and-spine fabrics is left as an exercise for the reader.
The example used IBGP over OSPF. Can we use EBGP-only design in a leaf-and-spine fabric? According to the original DMZ Link Bandwidth draft, the answer is NO. The DMZ Link Bandwidth community is not supposed to be propagated beyond a single AS2. Of course that didn’t stop anyone – there’s another draft saying it’s OK to propagate DMZ Link Bandwidth over EBGP.
I used Cisco IOS XE in the examples. What about data center switches? Similar functionality is implemented in Arista EOS and FRR (and thus Cumulus Linux, SoNIC, and whoever else uses FRR).
The Arista EOS implementation (described in the Data Center Fabrics webinars in June 2016) is even better than what’s available in Cisco IOS XE. You can aggregate the bandwidth advertised from downstream BGP speakers (servers or leaf switches), and split the bandwidth when advertising the same prefix toward upstream BGP speakers (spine switches or ingress leaf switches).
I haven’t found anything similar in Nexus OS; corrections are (as always) most welcome.
-
As is often the case when configuring BGP, the changes apply to new incoming updates. Do clear ip bgp soft in first. ↩︎
-
Long-time readers might remember that I was always telling people to use IBGP+OSPF instead of EBGP as better IGP hype in small data center fabrics. Not that anyone ever listens. ↩︎
It seems X1 and X2 routers have wrong loopback IP addresses in your network diagram. Any idea why the hash buckets are evenly distributed accross the interfaces and not according to the share ratio on PE1? Is this a bug?
@Anonymous: Fixed the diagram. Thank you. Also added lab setup instructions to the GitHub repository.
As for the CEF table: It could be a bug, or it could be irrelevant. I have no idea whether CSR 1000v uses CEF table for packet forwarding. If it uses the underlying Linux routing table, it doesn't matter what's in the CEF table.
X1 and X2 looks like are in AS65100 based on cli output. In the diagram X1,X2 are in AS65001.
Thank you, fixed. Hope this is the last error in that diagram 😕
Thank you for the post!
I tried something similar in my LAB and having difficulties understanding few things.
When I have equal BW on interfaces, from CEF I can see each destination using different interface.
R1#show ip bgp 4.4.4.4 BGP routing table entry for 4.4.4.4/32, version 8 Paths: (2 available, best #2, table default) Multipath: eBGP Advertised to update-groups: 1 2 Refresh Epoch 1 12641 12.12.12.2 from 12.12.12.2 (2.2.2.2) Origin IGP, localpref 100, valid, external, multipath(oldest) DMZ-Link Bw 1250 kbytes Refresh Epoch 1 12641 13.13.13.2 from 13.13.13.2 (3.3.3.3) Origin IGP, localpref 100, valid, external, multipath, best DMZ-Link Bw 1250 kbytes
R1#show ip bgp 44.44.44.44 BGP routing table entry for 44.44.44.44/32, version 9 Paths: (2 available, best #2, table default) Multipath: eBGP Advertised to update-groups: 1 2 Refresh Epoch 1 12641 12.12.12.2 from 12.12.12.2 (2.2.2.2) Origin IGP, localpref 100, valid, external, multipath(oldest) DMZ-Link Bw 1250 kbytes Refresh Epoch 1 12641 13.13.13.2 from 13.13.13.2 (3.3.3.3) Origin IGP, localpref 100, valid, external, multipath, best DMZ-Link Bw 1250 kbytes
R1#show ip cef exact-route 1.1.1.1 4.4.4.4 1.1.1.1 -> 4.4.4.4 => IP adj out of Ethernet1/1, addr 13.13.13.2 R1# R1#show ip cef exact-route 1.1.1.1 44.44.44.44 1.1.1.1 -> 44.44.44.44 => IP adj out of Ethernet1/0, addr 12.12.12.2 R1#
But when I configure unequal BW on E1/0 & E1/1, CEF always seems to prefer the one with higher BW.
R1#show ip bgp 4.4.4.4 BGP routing table entry for 4.4.4.4/32, version 11 Paths: (2 available, best #2, table default) Multipath: eBGP Advertised to update-groups: 1 2 Refresh Epoch 1 12641 12.12.12.2 from 12.12.12.2 (2.2.2.2) Origin IGP, localpref 100, valid, external, multipath(oldest) DMZ-Link Bw 12500 kbytes Refresh Epoch 1 12641 13.13.13.2 from 13.13.13.2 (3.3.3.3) Origin IGP, localpref 100, valid, external, multipath, best DMZ-Link Bw 1250 kbytes R1# R1# R1#show ip bgp 44.44.44.44 BGP routing table entry for 44.44.44.44/32, version 12 Paths: (2 available, best #2, table default) Multipath: eBGP Advertised to update-groups: 1 2 Refresh Epoch 1 12641 12.12.12.2 from 12.12.12.2 (2.2.2.2) Origin IGP, localpref 100, valid, external, multipath(oldest) DMZ-Link Bw 12500 kbytes Refresh Epoch 1 12641 13.13.13.2 from 13.13.13.2 (3.3.3.3) Origin IGP, localpref 100, valid, external, multipath, best DMZ-Link Bw 1250 kbytes R1#
R1#show ip cef exact-route 1.1.1.1 4.4.4.4 1.1.1.1 -> 4.4.4.4 => IP adj out of Ethernet1/0, addr 12.12.12.2 R1# R1#show ip cef exact-route 1.1.1.1 44.44.44.44 1.1.1.1 -> 44.44.44.44 => IP adj out of Ethernet1/0, addr 12.12.12.2 R1#
Does this mean ECMP works but not UCMP? Or am I doing something wrong? Apologies for the lengthy comment, really looking forward to read your thoughts on this :) Also, to confirm the traffic is in fact taking the interfaces mentioned in CEF, I applied ACLs to see the traffic matches, so it's definitely taking the interfaces as seen in CEF.
I apologize for such a mess of a comment, without proper markdown, I don't see the option to delete though :(
You'll find the answer in one of the old CEF-related blog posts (https://blog.ipspace.net/tag/cef.html). Hint: 5-tuple load balancing.
I used it here https://blog.ipspace.net/2021/11/anycast-mpls.html to get the desired results in a scenario pretty similar to this one.