… updated on Monday, May 24, 2021 12:05 UTC
Packet Bursts in Data Center Fabrics
When I wrote about the (non)impact of switching latency, I was (also) thinking about packet bursts jamming core data center fabric links when I mentioned the elephants in the room… but when I started writing about them, I realized they might be yet another red herring (together with the supposed need for large buffers in data center switches).
Here’s how it looks like from my ignorant perspective when considering a simple leaf-and-spine network like the one in the following diagram. Please feel free to set me straight, I honestly can’t figure out where I went astray.
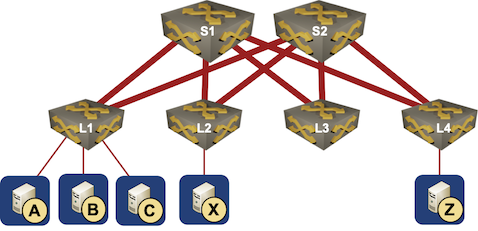
Simple leaf-and-spine network
Outbound Packet Bursts Generated by Servers
TCP stacks can generate large bursts of packets (1MB+), and we always worried about those bursts jamming outgoing interfaces, resulting in all sorts of QoS measures. However…
- Output queue can build (eventually resulting in interface congestion) only when the packet arrival rate is higher than the packet departure rate.
- In a data center fabric, the leaf-to-spine link is usually four times faster than the server-to-leaf link, so individual server bursts can never saturate the uplink.
- Even when bursts from multiple servers land on the same uplink, their packets are nicely interspersed, so there’s minimal latency increase and jitter. The proof is left as an exercise for the reader.
- Bad things start happening when simultaneous bursts from numerous servers (N » 4) land on a single uplink. That’s when you might need buffering. I’m saying might because people familiar with TCP keep telling me it’s better to drop than to buffer.
- It’s obvious that it helps if the packet dropping mechanism is better than drop everything that won’t fit, although even with the tail drop on leaf-to-spine links all currently active bursts get affected in approximately the same way (yet another exercise for the reader).
- TCP sessions might get synchronized resulting in the sawtooth behavior (so some sort of Random Early Drop can’t hurt), but at least there shouldn’t be excessive retransmission like what we’re seeing on Internet uplinks.
In any case, as I explained two years ago, you still don’t need deep buffers to handle uplink congestion.
Let’s redo the math based on Broadcom Trident-4: it has 128 100GE ports (or 32 400GE ports) and 132MB of packet buffers, resulting in more than 1MB per port without any buffer sharing. Assuming you’re not using jumbo frames, that’s more than 600 1500-byte packets in the output queue of every single port at the same time. When you see congestion like that, please let me know.
Spine-to-Leaf Links
Although the core of a leaf-and-spine fabric is usually not using oversubscription, individual spine-to-leaf links could get saturated when numerous sources send traffic toward destinations connected to the same leaf switch.
However, at that point the traffic bursts from individual TCP sessions are already nicely interspersed, and packet drops affect individual packets from many sessions (the spine switch is not dropping a whole burst).
Coming back to the it’s better to drop mantra, you probably don’t need large buffers at the spine switches (contrary to what some vendors are occasionally trying to sell). Having some sort of we’re about to get congested mechanism is obviously a good thing, as is smart load balancing at the ingress, but let’s not get off-track.
Leaf-to-Server Links
Incast is supposedly a huge problem in data center fabrics. When many sources send data to a single destination, packet drops occur because the switch-to-server link becomes severely overloaded, and bad things happen (see the next section).
You could “solve” this problem by connecting servers experiencing incast to large-buffer leaf switches, but as most TCP congestion algorithms aren’t delay-sensitive (the only thing they understand are drops), you’re effectively increasing end-to-end latency (resulting in people yelling at you) trying to fix other people’s problems.
There are obvious pathological cases like a large number of nodes with broken TCP stacks writing humongous amounts of data to a single iSCSI target. There will always be pathological cases, but that doesn’t mean we have to design every network to cope with them, although it does help if you can identify them and figure out what’s going on when you stumble on one (see also: House MD).
All Is Not Rosy in TCP Land
Speaking of pathological cases, someone told me about a pretty common one:
- While it’s true that TCP Selective Acknowledgement solves most of the packet drop issues, there’s a corner case: if the last packet in a request is dropped, the receiver won’t send a Selective ACK response, and as the sender keeps quiet (waiting for a response), we’ll have to wait for the regular TCP timeout to kick in.
- The default minimum TCP retransmission timeout (RTO) in Linux is 200 msec – ridiculously large for environments where we love nagging about microsecond latencies.
End result: if the network manages to lose just the right packet, end-to-end application latency can go through the roof. Even worse, it probably won’t show in the averages your lovely single-pain-of-glass displays, but the users will definitely notice it.
Most operating systems try to do their best estimating retransmission timeout (here’s a lengthy description of what Linux does), and if you care enough, you can set the minimum RTO in Linux routing table, effectively eliminating incast collapse and the need for big buffers. That’s been known for over a decade, but of course it’s easier to blame the network and demand large buffers everywhere. It might also be more expensive, but who cares – it’s some other teams’ budget anyway.
On a somewhat tangential topic, Linux can change IPv6 flow labels after encountering repetitive retransmissions, and if you use IPv6 flow labels as part of your in-fabric ECMP hashing, that could help TCP flows avoid a congested (or misbehaving) switch. For more details, watch the Self-healing Network of the Magic of Flow Labels presentation by Alexander Azimov
Revision History
- 2021-05-24
- Fixed the Linux RTO paragraph and added a link to Sigcomm 2009 paper measuring the impact of reduced minimum RTO. (source: Enrique Vallejo).
-
Added a link to RIPE82 presentation by Alexander Azimov (source: Blake Willis via LinkedIn)
Note that 200 ms is the default value for the RTOmin parameter, this is, the minimum value that the Retransmission TimeOut can be assigned dynamically, based on the estimation of RTTs. Decreasing this value (instead of the initial RTO) has been reported to hugely improve TCP goodput in presence of incast - because it reduces the dramatical impact of packet losses and retransmissions. See:
https://www.cs.cmu.edu/~dga/papers/incast-sigcomm2009.pdf
This study explores values for RTOmin of 1 ms and lower. Note that, in practice, you can be limited by the kernel clock resolution -- we have found some systems in the past where it prevented you from setting any value lower than 5 ms. In any case, the benefit from the default RTOmin = 200 ms is huge.
Datacenter links can normally support those server bursts, but at the end there is a traffic server to client that cannot support those bursts. Clients are 1G, servers are 10G/25G. Most of access switches can not suport all those servers bursts neither. Is still better drop than use pause frames on access switches?
@Enrique: Thanks a million! I love how much I learn from the comments ;)) Will fix the text and add a link.
@Xavier: As most traffic toward the client is client-generated in the first place, you wouldn't expect to see a massive incast problem, and as the TCP bursts gradually increase in size as the peers are trying to figure out what works, eventually the network-to-client link will get into packet drop territory and the inbound TCP sessions will reach an equilibrium.
I would strongly suggest you figure out (A) how much buffering there is on your access switches and (B) what's the percentage of outbound packet drops caused by output queue overflow. You might not have that problem at all.
Hi Ivan, spot on about deep buffering not required and a bit of drop (not too much) is fine in DC environments, where RTTs tend to be in us rather than ms range. Also, one implicit assumption on a lot of these discussions, is what we describe generally applies to busy to very busy DCs. For low-utilization DCs, it doesn't matter the design, just throw in hardware in a basic topology and often times it works acceptably :)).
That said, congestion in busy DCs doesn't require saturation of every single port of a switch, core or leaf. Take the incast scenario -- the same effect can happen to a hang server. Say when A,B,C and a few others on L1 send to X simultaneously and X fails to respond due to whatever reason, leading to output queue saturation on X port of L2 switch. That will cause all other traffic destined to X (say X is hosting several busy VMs) to be dropped as well, causing big delay for other traffic. And the buffer saturation will now move back toward that of S1-L2 port, still on L2, causing VOQ saturation on that input port. Depending on how the VOQs are built, if they're quota-restricted, they won't cause buffer fill-up on that port, but if the packet buffer is shared among all VOQs with not quota enforced on each one, then buffer hogging by the saturating VOQ will occur, leading to more packet loss for all sources sending to that uplink as well. So basically all traffic sent to L2 from S1 will suffer, while S1 can be under-utilized.
Also, another assumption we tend to make in high-level discussion is fabric scheduler's efficiency. But schedulers are not perfect, far from it. These schedulers, the majority of them some variants of iSLIP/PIM, tend to work well with uniform and uncorrelated traffic. When the traffic is bursty and correlated, plus there's congestion going on at some port, the scheduler's performance can drop pretty quickly. Also these schedulers are generally designed with the assumption of symmetry in mind. When switches have uplink ports whose link bandwidth are bigger than other ports, port scheduling can get inefficient. So in reality, all of these factors can cause congestion and increase delay greatly even when the core switches are under-utilized.
Vendors also tend to post best-case performance numbers, so when they post things like 5 billions of packets in total for product xyz, we should expect the thing to perform worse in practice. Their method of calculation can be questionable as well -- they might test only a subset of ports, then multiply the result and call that total switching capacity, when in fact, due to scheduler's performance variation between low and high offered loads, plus all other reasons mentioned above, realistic performance doesn't even come close to that.
Section 3.2 in this paper documents what happens when the authors attempt to create several traffic patterns on a leaf-spine topology. It's not a big setup, yet it can get ugly fast:
https://arxiv.org/abs/1604.07621
In big DCs with much bigger fan-in traffic, this situation can get worse. High fan-in can also cause work-conservation problem in switches as well. Say L1 in your diagram. When lots of ports all send to 1 or 2 uplinks at the same time, oversubscribing the uplinks, the scheduler performance can bog down because it's too hard to do efficient scheduling for that kind of traffic pattern, resulting in the uplinks not receiving as many packets as they can send out, aka they're not work-conserving. All of this can happen while L1's total load is nowhere near 100%.
Work-conservation is a fundamental issue in switch design, and AFAIK, there's no scheduler to date that can deal with this optimally, and that for unicast traffic alone. Mixing in multicast traffic, and things can get messy pretty quickly. That's why I don't put much stock in the beautiful performance figures vendors put out. That said, we don't generally have these kinds of problems in the average enterprise DC because switches are pretty underused there :)).
Thanks a million for another batch of "further reading". Just two minor details:
> Say when A,B,C and a few others on L1 send to X simultaneously and X fails to respond due to whatever reason, leading to output queue saturation on X port of L2 switch.
I hope we are not talking about lossless traffic here. Under the usual IP is unreliable, use TCP assumptions, if X does not respond, the traffic sent to it is lost (or at least unacknowledged), and the congestion on that port should be reduced (apart from occasional retransmissions).
> That will cause all other traffic destined to X (say X is hosting several busy VMs) to be dropped as well, causing big delay for other traffic.
And that is solved by rate-limiting or shaping the traffic toward a VM within the server, making sure congestion detection/avoidance kicks in well before the physical uplink is saturated. Yeah, I'm sure there are people out there not doing that, but that's a totally different story 🤷♂️
Hi Ivan, no, I was not talking about lossless fabric, just lossy ones; I intentionally left that one out because with lossless fabric, situations like this get much worse due to congestion spreading and HOL blocking :)) . Might even cause deadlock due to circular buffer dependency.
You're right the traffic sent to X is lost and congestion should eventually reduce due to TCP congestion control and exponential backoff, but TCP RTOMin is in the ms range even when tuned, while the port buffer can fill up in us range, due to both high bandwidth and high fan-in, so quite a bit of loss can result and back up in the meantime. In that situation, traffic shaping doesn't help as cumulative shaped bandwidth of high fan-in can still overrun OQ buffer at X in us timeframe.
Unfortunately, looks like data about DC congestion incidents are kept hush-hush -- if you know of any, pls let me know -- so we can't look deeper into specific cases and examine the dynamics. That would be a great way to improve our knowledge and experience, as one lifetime is too short to be able to witness all situations first hand :) .