Using Unequal-Cost Multipath to Cope with Leaf-and-Spine Fabric Failures
Scott submitted an interesting the comment to my Does Unequal-Cost Multipath (UCMP) Make Sense blog post:
How about even Large CLOS networks with the same interface capacity, but accounting for things to fail; fabric cards, links or nodes in disaggregated units. You can either UCMP or drain large parts of your network to get the most out of ECMP.
Before I managed to write a reply (sometimes it takes months while an idea is simmering somewhere in my subconscious) Jeff Tantsura pointed me to an excellent article by Erico Vanini that describes the types of asymmetries you might encounter in a leaf-and-spine fabric: an ideal starting point for this discussion.
Defining the Problem
Leaf-and-spine fabrics are usually symmetrical – there’s an equal number of paths (and equal number of hops) to get from any edge to any other edge.
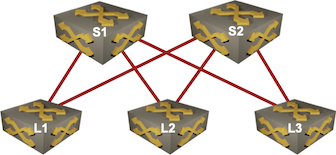
Looks symmetrical, right?
Due to that property, it’s mostly OK to use simple equal-cost multipath (ECMP) on leaf switches to get decent traffic distribution (ignoring for the moment the challenges of long-lived elephant flows).
Traditional routing protocols + ECMP can adjust to many failures in well-designed leaf-and-spine fabrics, and I haven’t found a scenario in a simple leaf-and-spine fabric where a node failure would result in asymmetry. Answering the same question for multi-stage fabrics is left as an exercise for the reader.
There are, however, two link failure scenarios that require special attention:
- Failure of one link in a leaf-to-spine bundle
- Impact of link failures on third-party traffic.
Link-in-a-Bundle Failure
Imagine the following fabric with two parallel links connecting leafs and spines:
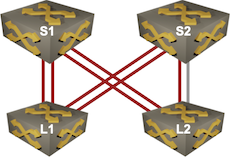
Link-in-a-bundle failure
When the L2-S2 link fails, we could get into one of the following scenarios (for more details, watch the Route Summarization and Link Aggregation video from Leaf-and-Spine Fabric Architectures:
LAG between L2 and S2 with bandwidth and routing cost adjustment based on the number of links in the bundle. The moment a bundle member fails, the cost of the LAG link goes up, and nobody is using it anymore. UCMP would be a solution for this scenario.
LAG between L2 and S2 without bandwidth or routing cost adjustment based on the number of links in the bundle. UCMP is of no use, as a member link failure doesn’t change a thing from the routing protocol perspective.
Multiple routing adjacencies between L2 and S2. The cost between L2 and S2 stays the same no matter how many routing adjacencies you have between the two nodes. UCMP cannot help you.
In theory, you could adjust link state routing protocols to compute end-to-end cost differently when there’s more than one routing adjacency between two routers, or adjusts distance vector routing protocols to report lower cost when the next hop is reachable over multiple links, but no-one seems to be “brave” enough to do anything along these lines. Well, almost no-one (see below).
In practice, I don’t think that handling this particular failure scenario is worth the extra complexity. You might disagree and deeply care about this problem – put your money where your mouth is and buy two more spine switches instead of burdening everyone else with more complex (and buggy) routing code. Problem solved.
When There’s a Problem, There’s a BGP Solution
Of course we can solve the above problem with BGP. What else did you expect?
Imagine you’re (mis)using EBGP as your IGP, and your vendor:
- Tweaked their BGP implementation to propagate DMZ Link Bandwidth extended community across EBGP sessions (described in an informational draft)
- Tweaked their handling of DMZ Link Bandwidth to advertise cumulative downstream bandwidth
- Tweaked their handling of EBGP ECMP to implement UCMP based on DMZ Link Bandwidth attribute received from downstream EBGP neighbors belonging to different autonomous systems (requiring as-path-relax feature, but almost everyone is doing that anyway).
Such an implementation would neatly solve the above problem. I described Arista EOS implementation years ago somewhere in the Data Center Fabric Architectures webinar. I have no idea whether they’re still doing that… but then no network OS feature ever disappears1. Pointers to other implementations are highly welcome.
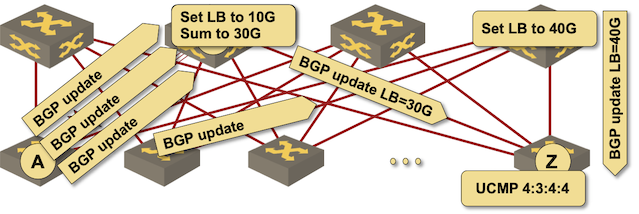
Arista’s aggregation of DMZ Link Bandwidth (June 2016)
Third-Party Link Failure
Now let’s consider a more interesting scenario – simple leaf-and-spine fabric with a single link failure:
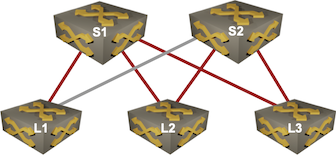
Third-party link failure
Because there’s a single path between L1 and L3, the link between S1 and L3 becomes more congested than the link between S2 and L3. If L2 uses ECMP between S1 and S2, half of its traffic encounters a more-congested link.
There’s nothing any routing protocol I’m aware of can do in this scenario, and UCMP is of no help either. Routing protocols are concerned with downstream paths, and the problem is caused by an independent upstream path.
Long Story Short
I don’t think asymmetries in leaf-and-spine fabrics are worth spending any sleepless nights on… unless of course you have frequent failures that take weeks to fix, but then you have a bigger problem than lack of UCMP.
Also note that all of the problems described in this blog post diminish if you use four or eight spine switches instead of two (plus you increase the resiliency of your fabric). The proof is left as an exercise for the reader.
For more details, watch the Leaf-and-Spine Fabric Architectures, now with brand-new Using OSPF in Leaf-and-Spine Fabrics section.
-
OK, AppleTalk did disappear from Cisco IOS decades after I’ve last seen it in the wild. X.25 is probably still there. ↩︎
I use UCMP not for failure scenarios like this but part of normal design.
It works particularly well when using anycast with servers. You have to think down to the server layer and maybe even higher than the spine layer for the most dramatic affect.
Within the fabric, maybe there are cases where different amounts of servers using the same ip address on each top of rack switch. The ECMP only method the spines would send equal traffic per top of rack switch. The UCMP would use its metric to balance it based on how many servers have the IP.
If you look up to the router layer. The router could be connected to multiple fabrics. What if fabric A has 5 anycast servers sharing an IP and fabric B has 20. With ecmp the router would normally split this 50/50 leaving the 20 servers in fabric b under utilized and the 5 in A over utilized. UCMP enabled up to this layer can track how many servers are at each fabric and balance based on server count. That way no matter how unbalanced the anycast deployment is in a datacenter, this feature enabled will help to keep the load even n every server.
At this point in time, RIFT solution to UCMP looks absolutely superior to any other approach (but I’m biased as you know ;-))
Hi Ivan, wrt to asymmetry of load and congestion when link failure happens, I brought up Conga previously in another post of yours re load-balancing. Conga helps with this situation because it holds global congestion information and therefore can alleviate this. It's a point-solution for two-level leaf-spine fabric that scale to 27.6k 10Ge ports. Pretty nice invention from Cisco and is available in their ACI, but Conga can be implemented independent of ACI:
https://people.csail.mit.edu/alizadeh/papers/conga-sigcomm14.pdf
@Network Ninja: Thank you -- I'm aware of that use case (Pete Lumbis mentioned it in a comment to the first article in this series), just haven't found the time to write about it yet.
@Minh Ha: I know you mentioned Conga. The solution from Erico Vanini's article is much more elegant and they claim it's comparable (performance-wise) to Conga. Will write a blog post about it (eventually...).