… updated on Saturday, May 1, 2021 18:19 +0200
Fundamentals: Is Switching Latency Relevant?
One of my readers wondered whether it makes sense to buy low-latency switches from Cisco or Juniper instead of switches based on merchant silicon like Trident-3 or Jericho (regardless of whether they are running NX-OS, Junos, EOS, or Linux).
As always, the answer is it depends, but before getting into the details, let’s revisit what latency really is. We’ll start with a simple two-node network.

The simplest possible network
End-to-end latency is the time delay between first node sending the packet and the second node receiving the packet… but we need to be more precise than that. The latency that we can observe and measure from the outside is the delay between the first node sending the first bit of the packet and the second node receiving the last bit of the packet (at which point it can start processing the packet).
In our simple network, latency seems to have two components:
- Serialization delay: the time it takes to put all the bits on the wire. This component depends solely on the link speed.
- Propagation delay: the time it takes for a single bit to get across the cable. This component depends solely on the cable length and signal propagation speed.
To put things in perspective, here are a few typical serialization delays for a 1518-byte packet with a 8-byte preamble (because Ethernet):
| Speed | Latency |
|---|---|
| ISDN (64 kbps) | 190 ms |
| Ethernet (10 Mbps) | 1,22 ms |
| Gigabit Ethernet | 12,2 µs |
| 10 GE | 1,22 µs |
| 100 GE | 0,122 µs |
Speed of signal propagation in a fiber optic cable is usually 70% of the speed of light in vacuum (copper cables are a bit faster – HT Adeilson Rateiro), or approximately 200.000 km/s, or 200 meters per microsecond.
In reality, there are two more components involved: transmit-side and receive-side transceivers. It’s hard to get transceiver latency numbers, what I found (from an unreliable source) was 0.3 µs per link (transmit and receive) for SFP+ and 2.6 µs per link for 10GBASE-T. Pointers to better sources would be much appreciated.
Transceivers add latency (diagram from Advanced Routing Protocols Topics presentation)
Beyond Two Nodes
In a larger network, intermediate nodes have to receive packets, process them, put them in an output queue, and finally send them.

Adding an intermediate node
For every intermediate node you’ll have to add:
- Switching (forwarding) latency;
- Output queuing delay;
- Serialization delay on output link unless the device uses cut-through switching.
To make matters even more interesting, there are two ways to measure switching (forwarding) latency (see Section 3.8 of RFC 1242 for details):
- In store-and-forward mode, latency is defined as the time interval between the last bit entering the switch and the first bit leaving the switch.
- In cut-through mode, switches become bit forwarding devices (using terminology from RFC 1242) – latency is defined as the time interval between the first bit entering the switch and the first bit leaving the switch.
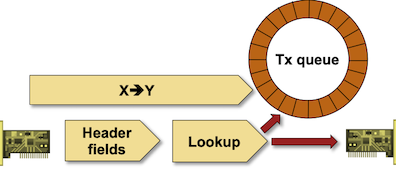
Cut-through Switching in a Nutshell
Most data center switching vendors claim switching latency in microsecond range, with low-latency switches being below 500 nsec. Broadcom is claiming Trident-3 forwarding latency is 900 nsec, while its carefully chosen competitor has 11 µs forwarding latency (based on the marketing brouhaha from major vendors, they must have looked really hard to find someone so slow).
The best I could find on the router side was a Cisco Live presentation from 2016 claiming “tens of microseconds” for ASR Quantum Flow Processor. Yet again, I would appreciate pointers to better sources.
Back to the Question
Coming back to the original question: does it matter? It might when you’re running extremely latency-sensitive applications on high-speed links within a single data center. The moment you’re using Gigabit Ethernet links, or sending data between multiple locations you probably shouldn’t care any longer… unless, of course, you’re in High Frequency Trading (HFT), in which case you don’t care what I have to say about latency anyway.
Finally: Spot the Elephant
Hope you found the above discussion interesting, but it might be totally irrelevant, as I carefully avoided a few elephants in the room.
The first one is definitely congestion or queuing latency. Switching latency becomes irrelevant when you’re dealing with an incast problem.
The endpoint latency is probably a pod of blue whales compared to everything else we’ve been discussing, and worthy of another blog post… but it’s well worth measuring and understanding.
It doesn’t make sense to optimize microseconds when the nodes connected to the network need milliseconds to respond. In other words: figure out what problem you’re trying to solve, and focus on the lowest-hanging fruits first, regardless of which team is responsible for picking them.
Finally, someone also mentioned that QoS can lower the latency even further. Unfortunately, that’s a red herring. QoS can lower the latency of high-priority traffic during periods of congestion by placing them at the front of the queue, but it cannot beat the laws of physics. No QoS tricks can reduce whatever the serialization or switching latency happen to be under idle conditions. Also, keep in mind that QoS tends to be a zero-sum game – you give someone more resources at the expense of someone else. The only exception I’m aware of is link compression, but I haven’t seen anyone doing that since the days of sub-Mbps Frame Relay or ISDN circuits.
Revision History
- 2021-05-01
- Added a few pointers to the elephants strolling about the room
- 2021-04-16
- Added a link to an Arista document describing their measurement of copper/SMF/MMF latency
My bet for the elephant in the room is congestion delay. Using a congestion control mechanism that keeps buffer utilization (and thus buffer delay) low, such as Datacenter TCP, is probably much more relevant than having a low forwarding latency in the intermediate devices. For example, an average occupancy of 20 packets per input buffer increases latency by 24 μs when using 10G, way larger than typical zero-load forwarding latency.
Buffering delay? Maybe packet size? Hard to guess the elephant.
Some HFTs are looking at using LASERs in space. Speed of light in a vacuum is faster again :)
Perhaps elephant flows that delay reception of more latency sensitive mice flows
There is a really good Cisco Live from Lucien Avramov (BRKDCT-2214) about low latency networking with a few numbers and measurements. He also points out that network latency is way lower than middelware and application latency, which is probably where one should start instead of optimising a few nano-seconds on a switch.
I think the elephant is "but how fast can you actually process the packets when you receive them?" 🙂
Excellent article (you always find interesting topics). My bet for the elephant will be QoS to lower the latency even further.
https://www.cisco.com/c/dam/en/us/products/collateral/switches/nexus-3550-series/esg-white-paper-ultralowlatency.pdf
I don't know where FPGA fits into this ultra low-latency picture, because FPGA, compard to ASIC, is bigger, and a few times slower, due to the use of Lookup Table in place of gate arrays, and programmable interconnects. In any case, looking at their L2 and L1 numbers, it's too obvious the measurement was taken in zero-buffer and non-contentious situations. In the real world, with realistic heavily bursty, correlated traffic, they all perform way less than their ideal case. But regardless, L3 switching at 250ns even under ideal condition is highly impressive, given Trident couldn't achieve it in any of their testing scenarios.
Again, I'm not bashing Broadcom. It's just I find it laughable reading their apologies in their report you linked to, wrt how they don't "optimize" for 64-byte packets (love their wording), and how they manage to find a way to make their competitor finish far behind in the tests. Granted, Mellanox was trying the same thing in their test against Broadcom, so they're all even, and we should only take these so-called vendor-released testing reports with a grain of salt.
The elephant in the room that you alluded to, is most likely endpoint latency. It's pretty irrelevant to talk about ns middlebox-latency when the endpoints operate in the ms range :p . And endpoint latency gets even worse when features like interrupt coalescing and LSO/GRO are in place. Must be part of the reason why the Cloud's performance for scientific apps sucks, and funny enough, they actually admit it as I found out recently.
But IMO, that only means the server operating system, the hypervisor, the software switch etc, are the ones that need innovation and up their game, instead of using their pathetic latency figures as an excuse not to keep bettering routers' and switches' performance. Overlay model is notoriously slow because it's layer on top of layer (think BGP convergence vs IGP convergence), and as mentioned in your previous post, Fail fast is failing fast: "If you live in a small town with a walking commute home, you can predictably walk in the front door at 6:23 every evening. As you move to the big city with elevators, parking garages, and freeways to traverse, it's harder to time your arrival precisely," that kind of overburderned, complex architecture is not deterministic and no good for applications with real-time requirements. Infiniband shied away from TCP/IP for the same reason, and used a minimal-stack model to keep their latency low.
The Cloud and their overlay model is a definitely a step backward in terms of progress. By doing it cheap, they make it slow. Good for their greedy shareholders, sucks for consumers who truly need the numbers. Well, I guess I can stop complaining now that bare-metal instances are a thing. But yeah, taken as a whole, basically echnology winter sems to continue. These days about the only kind of progress we have is corporate-PR progress.
Speaking of HFT, there seems to be a lot of fanfare going on there when it was big some 10 yrs ago. FPGA was often mentioned as the way they sped up their end-to-end latency. But I ran across comments of some of the guys who actually did HFT for a living sometime back, and they said it's all hot-air, with most of the stuff they try to optimize being on the software level, such as doing away with message queuing (and so, safely getting rid of locks) to unburden their programs of concurrency synchronization, which is a big latency killers. Staying away from language that performs garbage collection is another thing, as there's no one-size-fit-all garbage collection algorithm that's optimized for all use case, and regardless, it's an additional layer compared to explicit memory management, and more layer means slower.
From what I know of RenTech, one of the biggest if not the biggest HFT (they also do other algorithmic trading besides HFT), they rely on software with big-data models, not fancy hardware.
Yet another true gem from Ivan - Thanks ever so much
I guess the Elephant is TCP and the correct router buffer sizing. Too small and you get drops and thus retransmission and thus delay, too big and you get the bufferbloat phenomenon and thus delay again. Having said that, you need to buffer if you are not fast enough at switching and/or if your chipset design is crap (e.g. use of external memory for lookups) and thus perhaps this might be an elephant too ?
Just one last thing on buffer sizing in a SP environment. I also hope to engage Minh Ha on this as I know he's passionate about this subject too (he once wrote about selfsimilarity of internet traffic) but maybe on another post of Ivan - Ivan permitting of course ;)!!!
I found this paper "https://www.semanticscholar.org/paper/Internet-Traffic-is-not-Self-Similar-at-Timescales-Telkamp-Maghbouleh/6ca16fcd9959eb1bca89a52be63bf5cfbb3fcc00" cited at CiscoLive and also associated to multicast and video transport that is my major area of interest as we speak. The CiscoLive PPT is this one @ https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2015/pdf/BRKSPV-1919.pdf
Basically the Telkamp's paper is a theoretical paper and states that Internet Traffic is not SelfSimilar @ timescales relevant to QoS. This means that it is instead markovian and thus not bursty at timescale that really counts.
I also found though a pretty recent empirical paper from AT&T Labs that managed (not an easy task at all) to look into real Internet backbone traffic @ very small scale (relevant to router QoS and thus @ ms grain) that observed that real internet traffic is instead indeed self-similar and thus bursty even at ms level.
The AT&T lab paper is @ http://buffer-workshop.stanford.edu/papers/paper18.pdf
Would love to know what your take is on this pretty complex but tremendously important subject. Hope I haven't derailed too much from the main topic as DC traffic is totally different from SP traffic...unless you do ..... Telco Cloud :) ? In that case I hope it can be treated separately in a different post maybe - Ivan permitting of course !!
Cheers/Ciao
Andrea
Hi Andrea,
I cannot get access to the paper as only its abstract is available. Nevermind :)). Self-similarity/long-range dependency of traffic arrival, like almost everything else in the grand scheme of Internetworking, should be treated with a big-picture perspective. So basically if someone tries hard enough, they can prove that at a certain timescale, the traffic is not self-similar, or not that self-similar, you know, with some mathematical twists and "proved theorems" ;). Not that it changes the true nature of things, i.e. Internet traffic is still bursty on many timescales, as proven by microburst for the fine-grain level, and so, due to this many-timescale burstiness, using big buffer as a form of low-pass filter to smooth out traffic, doesn't work most of the time. It can increase throughput, but may not goodput (due to loss and retransmission), and at the cost of considerable latency. Not good.
Also, a lot of switch-scheduling algorithms work well with uniform traffic, but their performance starts to degrade when bursty models like self-similarity is used. Add to that multicast traffic when enabled, and optimum switch-fabric scheduling is still an open problem. That's why building a high-end router is a lot more than just writing some network OS and sticking it on top of off-the-shelf hardware, hoping for the best. And that's why I commented above, that the Cloud is a step-back in terms of progress, with their commodity-based network. Not that it matters, we're in the midst of a technology winter anyway, with scams like Quantum Computing and AI being hailed left and right as the saviours of the day ;).
So in a word, instead of trying to dispute the fact that Internet traffic is bursty on many levels, and use that as an excuse to justify their under-performing equipment, researchers and vendors would do better to face facts, and work hard to create products that work best for worst-case scenarios, as that's how routers were originally bench-marked anyway. Good, high-performance products never go out of style.
Back to our topic, for DC environment, when the RTT is in the low us, point-solutions like DC-TCP along with intelligent load balancing (flowlet, or even better, packet-level ECMP) can be used to both improve delay and throughput, plus negate the necessity of big buffer. Solutions like this are not viable in the Internet due to bigger delay and jitter, causing reordering and serious performance degradation.
For Telco/carrier Cloud environments, where NFVs (which are much slower than hardware SGW) get used a lot, latency is higher with a lot of jitter due to the nature of software and the varying link speeds, so DC-level near-zero buffer is not applicable. But all the same, very big buffer causes a lot of trouble there too. You might like this paper that discusses this particular issue:
http://lig-membres.imag.fr/heusse/WirelessNet/Papers/2012Jiang.pdf
A few years ago, Codel was proposed as the solution for bufferbloat in Internet/SP environment, and was highly touted. But with all of its fanfare, it's not without its weaknesses (like everything else) and its superiority against good old RED was challenged here:
https://core.ac.uk/download/pdf/33663637.pdf
In the end, I think there's no substitute for a good hardware and an over-provisioned network if you want to guarantee SLA, esp. for rainy days. If you have to live with a mix of legacy equipment whose performance lacks the rest of the fleet, you can use some tricks like bigger buffer to work around that, but it's a band-aid, not a solution.
Hello Minh !
Thanks for your priceless reply
This link should work for the paper cited by Cisco:
https://www.researchgate.net/profile/V_Sharma4/publication/266463879_Internet_Traffic_is_not_Self-Similar_at_Timescales_Relevant_to_Quality_of_Service/links/55b1ede708aed621ddfd6fae/Internet-Traffic-is-not-Self-Similar-at-Timescales-Relevant-to-Quality-of-Service.pdf?origin=publication_detail
My point was that regardless of what Cisco cited as a paper, traffic is indeed self-similar (i.e. bursty) even at ms/QoS grain and it is self-similar even at the backbone level (which is telling me that the low pass filtering implemented at the Edge boxes with big buffers does not smooth traffic towards the backbone in the end) as AT&T Lab's paper (http://buffer-workshop.stanford.edu/papers/paper18.pdf) proved by measuring it on their production network (not an easy task), then surely shallow buffers do not work in backbone routers. Huge buffers do not work either due to the bufferbloat phenomenon. So, it looks like there's no an easy recipe really in backbone networks.
Cheers/Ciao
Andrea
Hi Andrea,
Thx for providing the link. I've had a read thru it. Basically in that paper, they intentionally targeted the timescale not present in the original and seminal work of Leland et al, and came up with the conclusion that the traffic pattern wasn’t self-similar/fractal, at the low ms range. But they measured it over 1 link only, and then made some inference over the limited data obtained. Seriously, I had to suspect if this paper was a rushed attempt to make up a justification for Diffserv. Given the time period (2004) and with the benefit of hindsight, it's most likely the case, as around this period Diffserv was emerging as a viable answer to the false promise of Intserv. The paper’s analysis was shallow, and from what was presented, I had to sa, that the authors' understanding of the implications of self-similarity was insufficient, for them to draw informed conclusions out of it.
No wonder the AT&T empirical paper, which came out much later, and at a time when Internet traffic contained a lot more vid content than 2004 -- youtube came to be in 2005, Netflix and others much later -- refuted the finding of the former. Video traffic was proven to be self-similar in nature, and Broadcom also mentioned that in their presentation. It's pretty well-known.
What the paper you linked failed to realize, is that self-similarity's implication has a lot to do with whether more buffer or more bandwidth, is needed to deal with Internet traffic congestion. The quick answer is, more bandwidth is the way to go, aka throwing bandwidth at the problem. With Poisson/Markovian traffic, which is short-range dependent, queue sizes decrease pretty quickly, therefore as does congestion, so big buffer can be used to temporarily hold the congested traffic, to wait it out. Not so with self-similar traffic. This is a direct quote from Leland's empirical paper, "on the self-similarity of Ethernet traffic":
"In particular, overallpacket loss decreases very slowly with increasing buffer capacity, in sharp contrast to Poisson-based models where losses decrease exponentially fast with increasing buffer size. Moreover, packet delay always increases with buffer capacity, again in contrast to the formal models where delay does not exceed a fixed limit regardless of buffer size. This distinctive loss and delay behavior can be precisely explained in terms of the frequency domain manifestation of self-similarity (see Section 3.2). Because both low and high frequencies are significant, heavy losses and long delays occur during long time-frame bursts (due to the presence of low frequencies) and can, therefore, not be dealt with effectively by larger buffers."
See, with self-similar traffic, intuitively, one can see that when congestion happens, queuing delay will decrease very slowly, regardless of buffer size, due to the significance of the low-frequency part of traffic arrival. The low-frequency part of arrived traffic matters, because self-similar traffic is long-range dependent (LRD). Low-frequency component of traffic matters not in Poisson/Markovian traffic because it's short-term dependent, in other words there's no correlation of patterns over a long range of time scales. The correlation over large timescales of self-similar traffic, is exactly why the use of big buffer as a form of low-pass filter is mostly useless, and will increase delay exponentially as queue size gets longer and longer under congestion.
So to deal with self-similar traffic more effectively, increase the available bandwidth if possible (over-provisioning), have routers with powerful packet-processing capability, and pay attention to admission control/back-pressure, all with the goal of avoiding congestion. Because the nasty effect of self-similarity comes in when there’s some form of congestion, which can happen due to link failure/maintenance, hot-potato routing changes, DDOS etc.
Leland's empirical work (traffic measurements taken over 4 yrs in Bellcore network) brought to light the fractal nature of LAN traffic, and after further work was carried out in that direction, WAN and Internet traffics were also found out to exhibit LRD/self-similarity. And in DCs these days, microburst is an example of self-similarity at sub-ms timescale. Again, big buffer has been shown to be ineffective against microburst, with proactive schemes like DC-TCP being much better alternatives. In DC environment, features like Interrupt coalescing, TSO, GRO, definitely contribute to self-similarity because they create ON-OFF traffic patterns, with infinite variations in timeframe the bigger the DC and the more traffic sources you have.
There’s a proposed solution that’s originally intended to address the latency issue in DC, but from what I can see, equally applies to alleviating self-similarity consequences in SP backbone as a result of congestion, here:
https://people.csail.mit.edu/alizadeh/papers/hull-nsdi12.pdf
This work, which involves Cisco, suggests the use of Phantom Queue as a form of link utilization monitoring. So when the phantom queue is full, which is a bit less than 100% of the actual link, action is taken. In the paper, this was in the form of DC-TCP’s ECN marking, but it can be other things as well. The reason I bring it up is because I think this solution has values (and might be available in some Cisco platforms), unlike lots of other papers that get written for self-promotion or for securing tenure, with no useful practicality whatsoever.
Since you are in SP/carrier sector, you can convey this idea to your peers. If enough interest is generated, resulting in further work being done in this direction by research groups, industrial or academic, that study backbone traffic conditions as an engineering topic, then maybe better networking products can be created down the road at some point.
Cheers Minh
Hello Minh,
Thanks for your always valuable contribution. I investigated a bit more and I actually found out that any references to internet traffic being markovian at ms grain/scale that was present in the 2014 version of the Cisco Live PPT was removed in the 2017 version. Here's the two versions..
https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2015/pdf/BRKSPV-1919.pdf
https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2017/pdf/BRKSPV-2919.pdf
In particular, it was removed the reference to this cariden PPT:
https://dokumen.tips/documents/013-telkamp-how-full-is-full.html
Apart from these annoyingly cisco-disseminated red herrings...the message from Cisco is that VoIP and mcast IPTV are markovian and thus not bursty - fair enough.
The idea Minh is exactly what you envisaged and thus that of conveying to my SP peers this approach of avoiding congestion/queuing at all costs as there's no other recipe for self-similar traffic. So, the right amount of overprovisioning, a well-designed forwarding chipset with proper QoS too and definitely not shallow buffers and not huge buffers as the Leland/Wittinger paper you mentioned clearly highlights.
Having said that, I am currently more focused on transporting multicast which is a different beast and has its own challenges, with one of them being that of having to be transported by the same ip infrastructure as the self-similar unicast traffic ...
Cheers/Ciao
Andrea
@Jean-Baptiste Could you please share the link to "Cisco Live from Lucien Avramov (BRKDCT-2214)"
I can't find it.
Thank you
Hi Ivan, Thanks for this great content.
Please allow me to share a pointer to this recent survey about how the one-way delay is measured in traditional IP networks and in SDN. It covers 30 research works and standards that do so in passive and active ways. It also does some analysis, comparison (w.r.t to coverage, granularity, cost, accuracy & resilience to packet loss, re-ordering and duplication) and discussion about open issues such as controller based network wide delay measurements in SDN in the sub-millisecond realm.
[ACM paywall] https://dl.acm.org/doi/10.1145/3466167
Disclaimer: I am the author :-), but not the copyright holder!