Impact of Azure Subnets on High Availability Designs
Now that you know all about regions and availability zones (AZ) and the ways AWS and Azure implement subnets, let’s get to the crux of the original question Daniel Dib sent me:
As I understand it, subnets in Azure span availability zones. Do you see any drawback to this? You mentioned that it’s difficult to create application swimlanes that way. But does subnet matter if your VMs are in different AZs?
It’s time I explain the concepts of application swimlanes and how they apply to availability zones in public clouds.
Here’s a typical (let’s call it enterprisey) way of deploying an application stack in a public cloud:
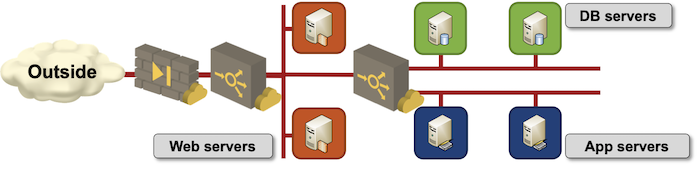
Use load balancers and multiple instances in every application layer
This architecture is extremely easy to deploy in Azure:
- Create an external application load balancer (Azure Application Gateway). Add Application Firewall for a sprinkle of security
- Create an internal network-layer load balancer (Azure Load Balancer) and use it for all layers of application stack to save some money.
- Deploy multiple VM instances in each application layer using availability set to ensure the VM instances are deployed across multiple availability zones (fault domains) and update domains.
It’s a perfect picture that will get you a tick-in-the-box during the annual audit and ensure your application stack survives an availability zone failure.
It’s also a perfect recipe for disaster when an availability zone experiences a bad-hair day resulting in significant performance degradation. Due to the way the resources are spread across all availability zones it’s likely that each user request will hit at least one instance in an underperforming zone, totally destroying the user experience (see also: How NOT to Measure Latency).
If you care about performance of your application stack you’d be much better off using the concept of swimlanes – parallel application stacks deployed in different regions or availability zones. A performance problem in a single availability zone would hit only a single swimlane, and you can easily take the whole swimlane out of operation by removing the first-layer instance (web server) from the top load balancer pool.
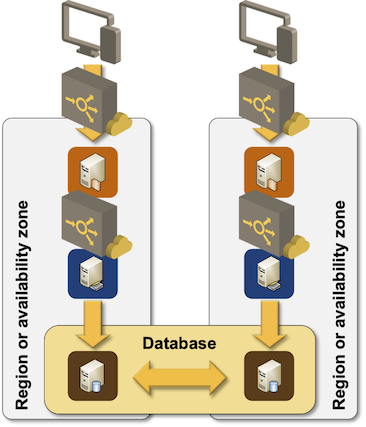
Application architecture using swimlanes
A word of caution before you run off and rearchitect your application stacks: as I already explained in the past, no amount of redesign will help you if you have a single transactional database sitting at the bottom of the stack. Even if you deploy a scale-out (multi-instance) database, the transactional requirement mandates tight coupling between those instances (example: 2-phase commit) which means that an underperforming instance could drag down the performance of the whole cluster.
The only way to decouple swimlanes is to use an eventually consistent asynchronous replication at the bottom of the stack. More about that in another blog post…
Dirty Details
By now you should have a number of questions including:
How is AWS better? Subnets are limited to individual availability zones, so it’s extremely easy to control the placement of all components of your application stack. Auto-scaling groups can also be limited to individual subnets (and thus availability zones) or span multiple subnets (in case you don’t care).
While Azure also allows you to pin resources to individual availability zones you have to deal with zonal resources and things quickly become somewhat more complex than they should have been.
Wouldn’t it be better to use multiple regions? Absolutely, and you could use either anycast global load balancing or global HTTP proxies in both AWS and Azure to perform load balancing across them instead of relying on DNS-based load balancing. But would you really want to take a whole region out of operation (and incur latency penalty on local users) just because a single availability zone is misbehaving?
Does It Matter? As always, there are no easy answers. You MUST have a realistic discussion with the business owners to figure out:
- How important is the application you’re deploying?
- What are the realistic availability targets?
- How much are they willing to pay for increased availability and/or performance?
- Does it even matter? In many cases, non-redundant architectures are good enough once we get past “does that mean I’m not important enough” ego trips.
After figuring out what the real needs are, you have to guestimate how likely it is to have AZ failure, AZ performance degradation, or region-wide failure, and design your application architecture accordingly. Just keep in mind that (A) high availability starts with good application architecture, (B) there are no silver bullets and (C) you can’t solve application problems with infrastructure hacks no matter what vendors claim in their slide decks.