Chasing CRC Errors in a Data Center Fabric
One of my readers encountered an interesting problem when upgrading a data center fabric to 100 Gbps leaf-to-spine links:
- They installed new fiber cables and SFPs;
- Everything looked great… until someone started complaining about application performance problems.
- Nothing else has changed, so the culprit must have been the network upgrade.
- A closer look at monitoring data revealed CRC errors on every leaf switch. Obviously something was badly wrong with the whole batch of SFPs.
Fortunately, my reader took a closer look at the data before they requested a wholesale replacement… and spotted an interesting pattern:
- All leaf switches apart from one had input CRC errors on one of the uplinks but not the other. What if there was a problem with the spine switch?
- The spine switch on the other side of the “faulty” uplinks had input CRC errors on the link toward the one leaf switch with no CRC errors, and output CRC errors on all other links.
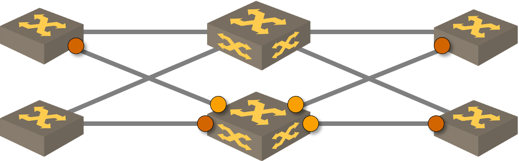
Weird pattern of CRC errors
Knowing Ethernet fundamentals, one should ask a naive question at this point: “isn’t CRC checked when receiving packets and how could you get one on the transmit side?” Fortunately my reader also understood the behavior of cut-through switching and quickly identified what was really going on:
- The one link with no errors on the leaf switch had a bad cable, resulting in CRC errors on the spine switch, but no errors in the other direction;
- The spine switch was configured for cut-through switching, so it propagated the corrupted packets, and stomped the CRC on egress ports to prevent the downstream devices from accepting the packet… increasing the transmit CRC error counter at the same time.
- Downstream leaf switches received corrupted packets originally sent over the faulty link and increased their receive CRC error counters.
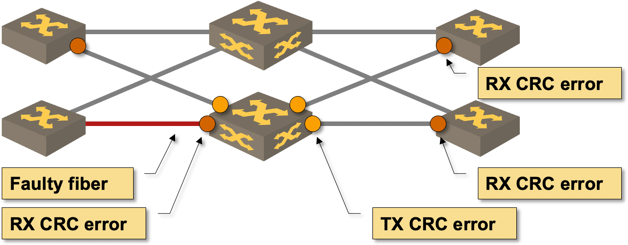
Fabric-wide errors caused by a single faulty transceiver
They replaced the faulty cable, the errors disappeared, and life was good. As for the original performance problem… maybe it wasn’t the network ;)
For more details watch the Store-and-Forward versus Cut-Through Switching video in How Networks Really Work webinar and read this excellent article by John Harrington.
Dear Ivan,
Thank you for this excellent article. It’s educated me very much. In it you wrote “ stomped the CRC on egress ports”. Could you elaborate on this sentence. It is not clear to me exactly what you mean.
Thank you.
Hi Mark! So nice to hear you like the article. For more details, follow the links in the paragraph starting with "For more details...". This might also help.
Ivan, I don't know about you, but I think cut-through and deep buffer are nothing but scams, and it's subtle problems like this that open one's eyes to the difference between reality and academy. Cut-through switching might improve nominal device latency a little bit compared to store-and-forward (SAF), but when one puts it into the bigger end-to-end context, it's mostly useless.
Take the topology in the post, say if the spine switch operates in cut-thru mode, then it can forward the frames a bit faster, only to be blocked up at the slower device(s) down the chain, as they're lower-end devices and so, can't handle the higher rate -- asynchronous speeds -- and being at the lower end, they might be SAF devices themselves. The downstream devices then become the bottlenecks, so end-to-end latency is hardly any better. Also, as cut-thru switches can't check CRC, they will just cause retransmission of bad packets, and along with it, an increase in end-to-end latency.
Even within the cut-thru switch itself, cut-thru mode is not always viable. Let's use Nexus 5k as an example. It uses single-stage xbar fabric with VOQ. If you have output contention, which you always do if your network is highly utilized, then the packets need to be buffered at the input waiting for the output to be available. In that case, cut-thru behaviour is essentially as good as SAF; both have to buffer the packets and wait for their turns to transmit.
Also, Nexus 5k (and other xbar switches) uses cell-based fabric + VOQ to deal with HOL blocking. So basically the xbar has to provide speed-up/overspeed to both compensate for cell tax and evade the HOL blocking problem. Since the xbar is therefore faster than the input interfaces, the asynchronous-speeds situation once again surface, and cells will have to be buffered before being sent across the xbar. Plus, in each cell time, there're arbitration decisions made by the xbar schedulers in regard to which cells get to enter the fabric, so buffering and waiting are inevitable.
All in all, the (dubious) benefit of cut-thru switching seems to be almost totally nullified. Not to mention cut-thru switches have more complicated ASICs and wiring than simple SAF switches, making it more expensive for no tangible gains.
I think cut-thru switching only makes sense if the whole network fabric runs the same model of switches, with simple protocol stack. So the place where it makes sense is niche markets like HPC cluster running low-overhead infiniband, or HFT trading, but the latter are mostly criminals trying to front-run each other anyway, so not sure if it's ethical to provide a tools for them to do damage to society.
In day-to-day networks that deal with a mixture of traffic types and aggressive traffic patterns, cut-thru switching, like deep buffer, is just a diversion, and provides yet another opportunity for vendors to sell their overpriced boxes.
I must admit, I did find Cisco very admirable for having the guts to come out and say it like it is, that these days Cut-thru and SAF are very similar performance-wise.