Fast Failover: Hardware and Software Implementations
In previous blog posts in this series we discussed whether it makes sense to invest into fast failover network designs, the topologies you can use in such designs, and the fault detection techniques. I also hinted at different fast failover implementations; this blog post focuses on some of them.
Hardware-based failover changes the hardware forwarding tables after a hardware-detectable link failure, most likely loss-of-light or transceiver-reported link fault. Forwarding hardware cannot do extensive calculations; the alternate paths are thus usually pre-programmed (more details below).
Software-based failover can act on link or node failures, including byzantine failures on a path between two forwarding engines as detected by BFD or similar protocols. It can involve selecting alternate routes provided by another routing protocol – including floating static routes – and extensive reprogramming of forwarding tables.
However, keep in mind that on modern CPUs the reprogramming of forwarding tables might take longer than the time a routing protocol needs to do its job, so it might not make sense to make software-based failover too complex… unless of course your hardware supports Prefix Independent Convergence (the ability to update next hops for a set of prefixes).
Hardware details are extremely hard to come by. Most high-speed switching silicon is either designed in-house by networking vendors or covered by impenetrable NDAs (an astonishing state of affairs considering how everyone loves to praise the virtues of open-everything).
Sometimes a vendor using third-party merchant silicon decides to spill some of the beans like Cisco did describing ASR 9000 behavior. While those documents are fun to read, to understand the fundamentals we often don’t need more than a high-level overview like what Lukas Krattiger sent me. As always, all the good stuff is his, and all the errors are mine.
Equal Cost Multi-Path (ECMP) is a function available in routing protocols that is supported natively in most routing platforms. It results in having multiple next-hops for a prefix (IP prefix or MAC address).
Routing protocol ECMP is driving the Routing Information Base (RIB, routing table), generally based in control-plane/CPU. Forwarding Information Base (FIB), the data-plane/ASIC-based part, is a different part of the story. If you support ECMP in the control plane doesn’t necessarily mean that you have ECMP programmed in the data plane.
We need to understand that Equal Cost Multipath (ECMP), Unequal Cost Multipath (UCMP), Loop Free Alternate (LFA) or Fast Reroute (FRR) are ways to influence the RIB and, if supported, tell the FIB what to program for forwarding. In order to make this happen, FIB needs functionality to support this, most commonly ECMP groups, Recursive Next Hops (RNH) used by protocols like BGP, and directly-connected next hops (CNH) aka adjacencies.
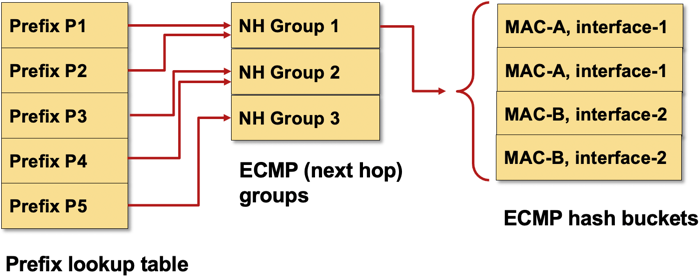
Typical FIB implementation supporting prefix-independent convergence with next-hop groups and ECMP buckets
Our expectation is that ECMP fast failover is always fast and consistent, but in fact, it’s usually Prefix Independent Convergence (PIC) which delivers this. To make matters even more complex, we have PIC Core (recursive next-hop resolution in a ECMP network) and PIC Edge (backup routes)
So three points become important when evaluating a solution:
- Routing protocol functionality;
- Programming RIB and FIB
- Forwarding hierarchies available and used in the FIB itself (ECMP, PIC, RNH, CNH).
If you rely only on routing protocols and techniques like FRR, LFA. routing protocol ECMP, you will not achieve faster convergence as the hardware must be re-programmed after every change has been evaluated. If you move groupings, hierarchies, and resolution checks into the hardware, you can achieve this much, much faster.
In simple terms, if you are using ECMP in the FIB, and a link to a next hop fails, there is no change to the prefix. A member of the ECMP group (directly connected or recursive) will be removed as it is not reachable anymore. Once a routing protocols learns about the topology change, most likely much later than the FIB can react, then it will start recalculating your routing topology and this can take time.
If you use indirection in the FIB and in the network, you can use things like MPLS labels, as used in Topology-Independent LFA (TI-LFA) or FRR. While this is a great approach, you might end up in using a lot more ECMP groups as your hardware might lack an additional level of indirection (labels in next hop groups).
Most scalable approach is still classic ECMP with PIC Core. If you can’t do that because of a complicated set of WAN links, choose wisely what method to use. In that particular case Segment Routing (SR) could be an option, as it has less complexity than the traditional MPLS-based solutions.
Let me add my own set of warnings to the end of this story:
- Different ASICs from the same manufacturer have different FIB structure and thus different fast failover capabilities;
- We don’t know what most ASICs can do, and can only hope to glean some details from vendor presentations;
- Even when an ASIC contains specific hardware functionality, that feature might not be supported in software running on the device;
- Until things settle down, expect every software release to behave a bit differently;
- If the fast failover behavior really matters, get all vendor promises in writing, make them part of purchase agreement, and do thorough lab testing way beyond pulling cables and measuring ping packet loss.
Thought the ASR9000 chipsets aren't Broadcom based, just unfortunately similarly named
This is important statement to remember that hardware must be programmed. This is true not only for FRR, IPLFA, ECMP, but also for EIGRP Feasible Successor and Prefix Prioritization. For example Prefix Prioritization was added in hardware by Cisco somewhere in 2015 on some platforms. Prior that there was no guarantee that the order of prefixes configured in software was preserved in hardware.
Just to clarify some points: - "PIC Core (recursive next-hop resolution in a ECMP network)" - PIC Core takes care of hierarchical FIB and resolution not only in ECMP. - On modern platforms PIC Core is enabled by default. On older like 7600 it requires an additional command. So to have hardware based backup path in IPFLA on ASR9k it is enough to turn on IPLFA. - "keep in mind that on modern CPUs the reprogramming of forwarding tables might take longer than the time a routing protocol needs to do its job" - It depends on the number of prefixes/objects to be programmed. Every hardware has its own FIB speed like ASR1k around 13k prefixes/second. This means that writing/removing 13k of prefixes takes 1 second. So a routing table computation can be faster but the overall convergence process will be longer as it requires also updating HW FIB.
@Piotr: Thanks a million for the ASR1K data point - exactly what I needed. Any pointers to documentation I could use?
My point was "if it takes 1 second to reprogram the FIB, who cares if it takes 1 msec or 100 msec to find the alternate path".
>>Thought the ASR9000 chipsets aren't Broadcom based, just unfortunately similarly named The NPUs are EZchip-silicon, at least for Trident & Typhoon, Tomahawk & Lightspeed maybe too. But they're also using Broadcom with the switch fabric which is (to my knowlege) just a big Broadcom-silicon-based switch. Not sure, but that's perhaps where the generation-name is derived from.
>>On modern platforms PIC Core is enabled by default. That's probably not true in all cases. It might be true for routers, but definitely not for switches, especially not for datacenter switches. The reason for that is the compromise you have to take in lookup time vs convergence time which is flat FIB vs hierarchical FIB (a.k.a. "PIC Code").
@Christoph
On your comment of: >>That's probably not true in all cases. >>It might be true for routers, but definitely >>not for switches, especially not for >>datacenter switches. The reason for that >>is the compromise you have to take in >>lookup time vs convergence time which >>is flat FIB vs hierarchical FIB (a.k.a. "PIC Code").
This is not accurate. Majority of the Switching Silicon (ASIC) supports hierarchical FIB and this is true for Merchant and Custom Silicon. For example, the Cisco Nexus 9000 (Cisco Silicon) as well as the Nexus 3600-R (Merchant Silicon) supports it and the same is true for the broader Merchant Silicon set across Broadcom, Innovium, Barefoot etc. The difference is in the detail but hierarchical FIB is today a pretty standard in Switch Silicon (ASIC).
@Ivan: FIB Speed is rare info available publicly. The most data today you can get about NCS: https://xrdocs.io/ncs5500/tutorials/ncs5500-fib-programming-speed. Other platforms via Cisco representatives or own testing.
>> My point was "if it takes 1 second to reprogram the FIB, who cares if it takes 1 msec or 100 msec to find the alternate path"
@Ivan: Agree. In such a case just a prefix prioritization may be good enough.
Ivan, here's an article from Broadcom describing their ECMP process in their ASICs like Trident and Tomahawk:
https://www.broadcom.com/blog/broadcom-s-trident-3-enhances-ecmp-with-dynamic-load-balancing
What they call Dynamic LB, is their equivalent of Juniper's Trio chipset's adaptive LB method. They both monitor the load and do flow redirection on sensing elephant flows hogging a link. So all of Juniper's platforms that make use of Trio chipsets, run ECMP in hardware. Their QFX5100 use Broadcom Trident 2, and since it'd kill forwarding speed and lead to packet loss as well if they don't do it in hardware, most of all when the hardware natively supports it, I can't see any reason QFX5100 doesn't perform hardware ECMP.
Cumulus, when they're indepdent, used both Mellanox and Broadcom ASIC, and they describe their ECMP behaviour here -- it varies depending on the ASIC in use, which basically tells us that it's done in hardware:
https://docs.cumulusnetworks.com/cumulus-linux-41/Layer-3/Equal-Cost-Multipath-Load-Sharing-Hardware-ECMP/
As to FIB speed, while vendors don't disclose much, we can get some rough idea of what's going on by looking at doccos from part suppliers, like this one here:
https://www.xilinx.com/support/documentation/ip_documentation/tcam/pg190-tcam.pdf
Xilin's TCAM lookup speed is 170MHZ. Assuming one lookup per packet, that Xilinx's particular TCAM can handle up to 170 Mpps, which exceeds 100GbE's max capacity of 150mpps. I've heard of much higher clock rate, and this is probably something you can verify with your industry contact, as they likely know better.
Xilin's TCAM update speed is, understandably, lower, due to TCAM's fundamental limitations. And interestingly, this fundamental limit can be seen manifested in the NCS5500 link shared by Piotr's above, in which FIB programming speed lags deletion speed quite a bit, 27.8k/s vs 32.6k/s.
This is also exactly the reason why SDN radicals and Openflow fundamentalists have failed miserably to date. They promised the world with their centralized controller model, but fell woefully short when it came to delivery, as the intrinsic nature/limitation of TCAM deals a huge blow to the overly dynamic flow-update requirement of flow-based switching, leading to massive latency issues, to say nothing of the heat dissipation problem caused by the sheer amount of insertion/deletion. On top of that, flow-based entries take way more states/bits to represent in TCAM compared to MPLS or IPv4, leading to multiple lookup per entries, severely cutting back on the lookup speed and the Mpps, and contribute to the heat and power utilization issue as well. That's why flow-based forwarding will never work, and the SDN guys were/are contemplating flow aggregation, which brings them back full-circle, to MPLS/IP paradigm.
IPv6 suffers from the same later issue, so for ex, in Cat6500 6T engine architecture docco, Cisco stated that their LC could handle 60Mpps for IPv4, and 30Mpps for IPv6. This is what happens when the software guys aka IPv6 designers, were disconnected from forwarding-plane reality. Segment routing, with its massive label stack, can fall prey to the exact same resource utilization problem, and itself comes with big complexities all over the place, while offering not much in return (what's the big problem it's supposed to solve?). And some people even have the audacity to preach abominations, insanities the likes of Srv6, totally disregarding how it's gonna melt their ASIC to liquid. Unbelievable!
Try as they might, centralized paradigm, due to various hideous problems, will never scale as well as distributed routing/switching.
Also, I agree with Lukas' comment above. Hierarchical FIB, is pretty standard for high-end silicons. MX routers, for ex, have H-FIB by default and you cannot turn it off.
And this part "keep in mind that on modern CPUs the reprogramming of forwarding tables might take longer than the time a routing protocol needs to do its job, so it might not make sense to make software-based failover too complex… unless of course your hardware supports PIC", I might have misunderstood what you meant here, as I though you meant PIC was 100% FIB-based recovery. If so, my apology Ivan.
From what I know, PIC, both Core and Edge, rely on IGP's convergence to do its work before they can get down to business, so they can't converge any faster than the software, IGP reconvergence in this case. The purpose of PIC is to enhance BGP-specific forwarding reconvergence and do away with/decouple from BGP routing reconvergence delay, as that one takes rather long. PIC Core doesn't need BGP indirect next hop, it just needs IGP indirect next hop to work, but PIC Edge is more involved and requires both types of indirection to work. ALso, with PIC, there's no need to do FIB re-programming, as you just remove the pointer that points to the previous next hop. THe BGP indirect next hop structure resides outside the TCAM, in a SRAM table I suppose, for fast lookup, just like the adjacency table.
@Minh Ha: Thanks a million for an extensive set of links and other details.
As for my "don't bother with software complexities if you don't have PIC" bit: maybe I should have called it hierarchical FIB, and say "don't bother doing anything beyond decent routing protocol implementation if you don't have hierarchical FIB"
@Lukas My comment based on what I was told. That was a couple years ago, it might be outdated or simply wrong, so thanks for the correction! :-)
Hi there,
I just wanted to add a couple of info I have come across:
1) Some implementations make use of the central CPU to scale BFD up (and not only BFD) since they provide the central CPU with the very same forwarding ASIC that is on the cards while others use the CPU on the line cards
2) BGP PIC-CORE implementation is, to me, very much ECMP fast-rehashing but at a higher indirection level of the hierarchical FIB as it applies to service/BGP prefixes in a BGP multipath scenario. What I found regarding BFD is that in some implementations the trigger for the ECMP fast-rehashing at that higher level can be both an interface-down or a BFD session-down event but in other implementations it’s the BFD session-down event only that triggers the ECMP fast-rehashing at that higher level of the hierarchical FIB. This latter case has some implications depending on your routing environment as you might not want to enable BGP Multipath for traffic/prefixes requiring ECMP fast-rehashing in case you loose for instance all of the primary interfaces towards one of the N x Multipath'ed BGP-NHs and you have no intention or you cannot run BFD-MHOP.
Ciao Andrea
@Ivan, I really enjoy reading your blog posts, it's time well spent. And what makes it even more interesting is the comments section. It is really amazing how much information can one find there.