Can We Trust BGP Next Hops (Part 2)?
Two weeks ago I started with a seemingly simple question:
If a BGP speaker R is advertising a prefix A with next hop N, how does the network know that N is actually alive and can be used to reach A?
… and answered it for the case of directly-connected BGP neighbors (TL&DR: Hope for the best).
Jeff Tantsura provided an EVPN perspective, starting with “the common non-arguable logic is reachability != functionality”.
Now let’s see what happens when we add route reflectors to the mix. Here’s a simple scenario:
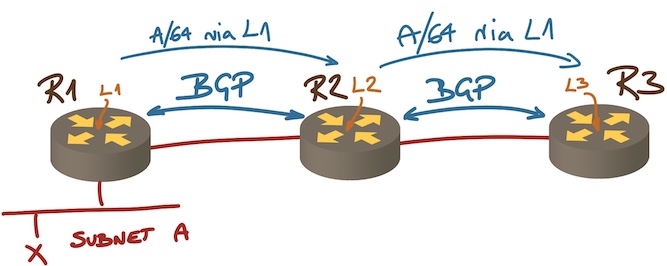
BGP next hops when using an IBGP route reflector
Assuming we’re running IBGP sessions between loopback interfaces, and all AS edge routers use next-hop-self so all the BGP next hops within the AS are the loopback interfaces, can we can trust that the advertised next hops are safe for packet forwarding? TL&DR: Heck NO.
In Trust We Trust
In our scenario R1 advertises subnet A with next hop L1, the update is sent to R2 and reflected to R3. Here’s the chain of implicit trust that leads to R3 selecting L1 as the next hop for A:
- R2 has to trust that R1 did the right thing, can reach A, and can forward packets to A (we discussed this part in the last blog post).
- R3 has to trust that R2 (the route reflector) did its job correctly;
- R3 has to have L1 in its routing table;
- R3 has to trust that the intra-AS routing protocol did its job and calculated the correct next hop to reach L1;
- R3 has to trust that all the intermediate nodes on the IGP-computed path between itself and R1 know how to forward the traffic toward A (not just toward L1).
In the BGP over MPLS core design the situation is slightly different. After verifying that L1 is in R3’s routing table, R3 has to:
- Hope that it has an LSP toward L1 in its LFIB, or that everyone in the forwarding path knows how to reach A.
- Having an LSP toward L1, trust that the LSP is not broken, and that everyone on the LSP does proper label swapping.
What could possibly go wrong?
In the last blog post I mentioned two things that can go wrong in a directly-connected BGP scenario:
- Access control lists that would drop traffic toward A;
- RIB-to-FIB mismatch (lovingly called ASIC wedgie). Obviously that’s not just a myth, managing that mismatch was presented as one of the first use cases for Cisco’s Network Assurance Engine.
Let’s add a few other minor details to the mix:
- Best path selection on BGP route reflectors could generate a persistent loop.
- Ever heard of BGP Wedgies? There’s a whole RFC on the topic.
- Then there’s BGP-to-IGP synchronization and IGP-to-LDP synchronization.
- Finally, you could get corrupted LFIB anywhere on the path.
For even more BGP fun, read Considerations in Validating the Path in BGP (RFC 5123).
After considering all that, do you really care whether R1 advertises a prefix with the next hop equal to the source IP address of its IBGP session, or with a third-party next hop that it believes works?
Back to EVPN
I’m guessing that the original question that triggered this series of blog posts had a hidden assumption (and I apologize in advance if I got it wrong):
In the EBGP-only data centers, it’s better to run IBGP between loopback interfaces of leaf- and spine switches than to advertise loopback VTEPs over EBGP sessions on leaf-to-spine links, because we can rely on direct next hop (loopback VTEP advertised over IGBP between loopbacks) more than on third-party next hop (loopback VTEP advertised as third-party next hop over EBGP session).
Considering everything I wrote above, reachability != functionality, and the myriad things that can go wrong, I would consider this a minor detail, and the least of your worries. Also, remember the conclusion of my previous blog post on this topic: “You might as well stop bothering and get a life, networks usually work reasonably well.”
More to Explore
I’ll slowly get to the routing protocols in the How Networks Really Work webinar (parts of it are available with free ipSpace.net subscription), and we have tons of content on leaf-and-spine fabric designs (including routing protocol selection) and EVPN.
You might also want to explore other BGP resources we’ve created in the last decade and a half.
Why would you run eBGP? I thought we should keep the things simple. What's the problem running IGP with iBGP?
"Why would you run eBGP [as the underlay data center fabric routing protocol]" << I keep wondering that myself, but some vendors insist on doing that even though they never designed and/or adapted their software to that use case.
This problem arises from the fashion of centralized Route Reflectors.
The course books were not updated in the last few decades from the state when enabling a Route Reflector could overload and break your router. So you need a centralized solution. Always, no exceptions in most people's mind...
However, an IP network routing protocol by original design should share the fate of the links. So your iBGP sessions should follow exactly the physical topology. Then if a link goes down, then the corresponding single iBGP session goes down. There is no cascade of multiple iBGP sessions going down. There is no problem with a different virtual topology.
The fully distributed RR setup is the safest and closest to the original intentions. However, it is not so easy to automate, since every transit router will become an RR and each of them will have a slightly different BGP configuration.
Once you share the fate of the iBGP session with the fate of the link, then you do not even need to use loopbacks. Indeed you should use the real interfaces addresses. If you use loopbacks, then BGP is really just telling the overall reachability of your loopbacks, no information about the actual physical topology.
By the way, centralized RRs are typically logical single point of failures by design. You can have RR hardware redundancy, you can do vendor diversity, but still you can misconfigure and a big chunk of your network has gone. I have seen it multiple times...
With a distributed, fate sharing RR design, when BGP on one node is misconfigured then you just lose that single node and its links. No other impact on the rest of the network. If you had a redundant topology, then all services are still happy after convergence.
Of course, in transit AS you have to take care about full Internet routing tables. But in most enterprise networks you are not a transit AS. So you do not have such scalability issues. You have the freedom to use a fully distributed RR design... If you prefer a robust network...
Ivan, I went back to some of your old, connected to this blog posts and I think I understood now why I started seeing DC protocol wars in linkedin and around other blog spaces.
In my opinion, 95 to 98% (accounting for all the nerds and enthusiast who wants to make their lives miserable) of the time you don't need bgp only fabric. The last 2% might fit into rfc7938 that all vendors cite in defence of the bgp only dc, but let's be honest, with a properly configured igp you can easily go to 1k+ devices in the underlay. Choose the right device with the right port count for your 1k switches, and this could be the only thing you will ever need as scalability.
Cheers.
@Bela: While I agree with everything you wrote, there's a theoretical difference between running pure IP versus BGP-with-MPLS-core, or MPLS/VPN, or EVPN with VXLAN or MPLS. You probably still don't want to have full tables for all address families on all devices in your network.
However, those data center fabric vendors that believe in IBGP for EVPN published designs with route reflectors on all spine switches, so why bother ;)
@Alexander: We're in perfect sync. With a bit of network design you can probably increase the 1k+ to 10k+ (for example, using stub OSPF areas in access layer), which should be more than enough for most everyone.
I would also be surprised if many data centers with more than 10K switches run layer-2 networks with VXLAN and EVPN on ToR switches, making the whole brouhaha a bit of an academic exercise.