Avoid Summarization in Leaf-and-Spine Fabrics
I got this design improvement suggestion after publishing When Is BGP No Better than OSPF blog post:
Putting all the leafs in the same ASN and filtering routes sent down to the leafs (sending just a default) are potential enhancements that make BGP a nice option.
Tony Przygienda quickly wrote a one-line rebuttal: “unless links break ;-)”
We covered the drawbacks of summarization in leaf-and-spine fabrics in great details in the Layer-3 Fabrics with Non-Redundant Server Connectivity part of Leaf-and-Spine Fabrics Architectures webinar and Designing and Building Leaf-and-Spine Fabrics online course. Here’s a short summary of that discussion.
The Problem
Imagine the design proposed by my reader:
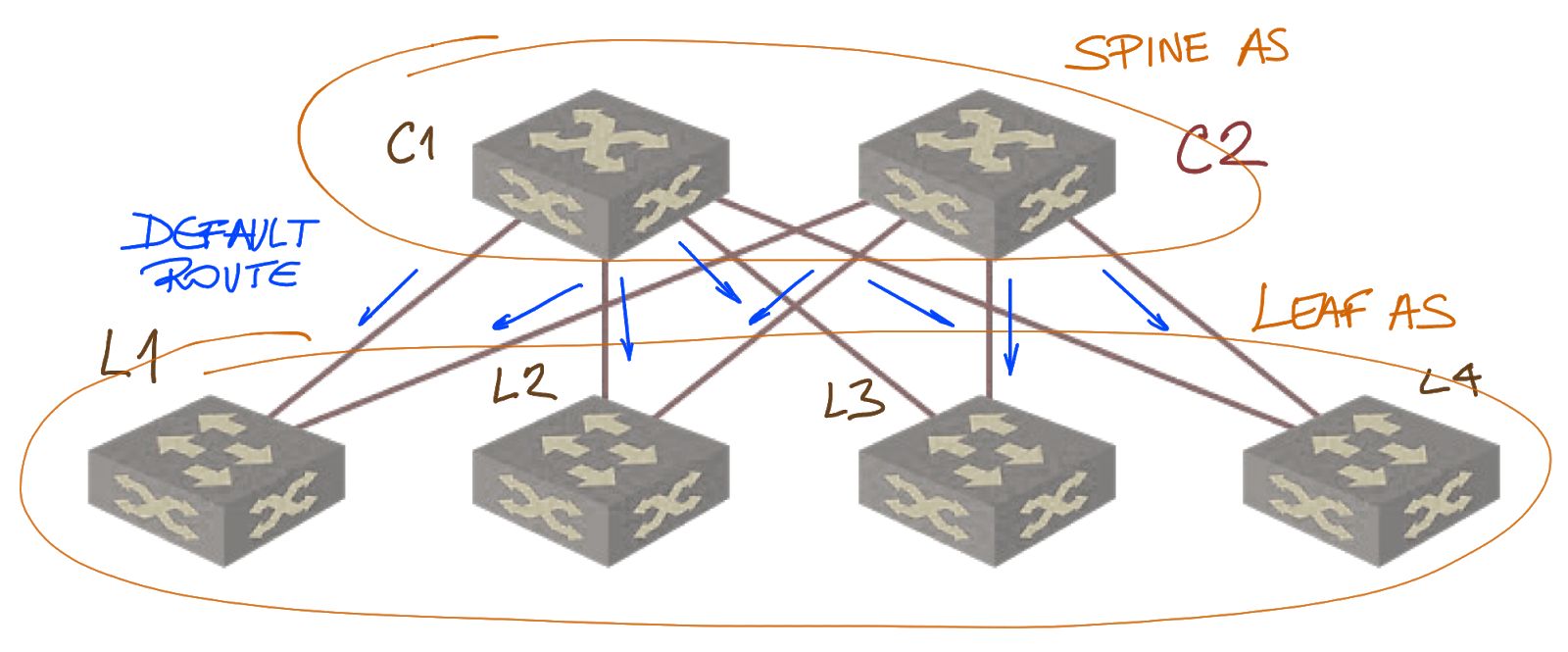
Using a default route in a data center fabric
Spines announce a default route (or some other summary route) to the leaves, and the prefixes announced by leaves are not propagated to other leaves.
Now image the L1-S1 link fails. No routing update is sent to other leaves, and they continue sending the traffic as they did before. For example, L4 will (on average) send 50% of its traffic for L1 toward S1… where the traffic will be dropped because S1 has no route for prefixes advertised by L1.
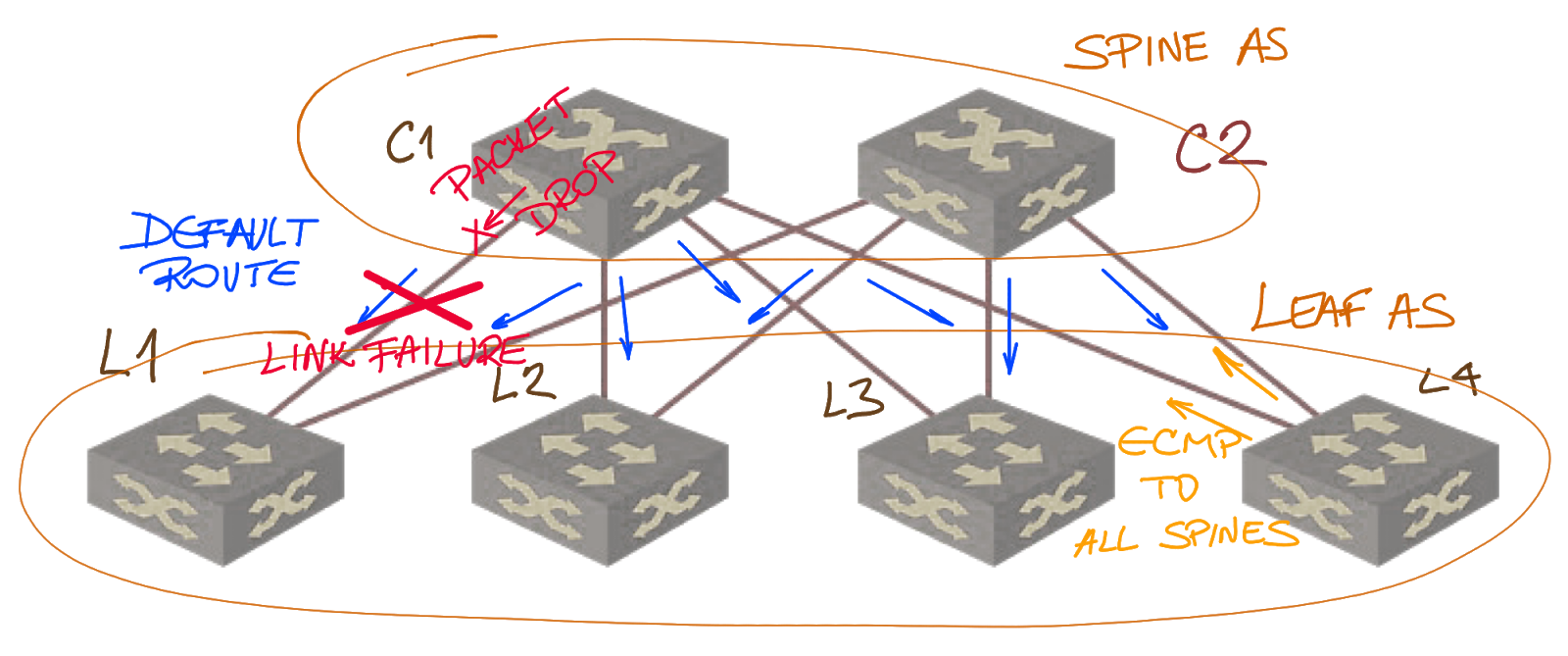
A link failure creates a black hole
The scenario (although in a slightly different format) should be familiar to anyone who had to deal with inter-area summarization in redundantly-built OSPF networks.
Can We Fix It?
Sure. You can add links between spine switches, add a superspine layer, or use RIFT (not available for production deployment at the time this blog post was written) that does selective deaggregation following a link failure – more details in Software Gone Wild Episode 88.
Let’s focus on the challenges of the inter-spine links. Life is simple if we have just two spines: we add a link between them and run IBGP session across that link.
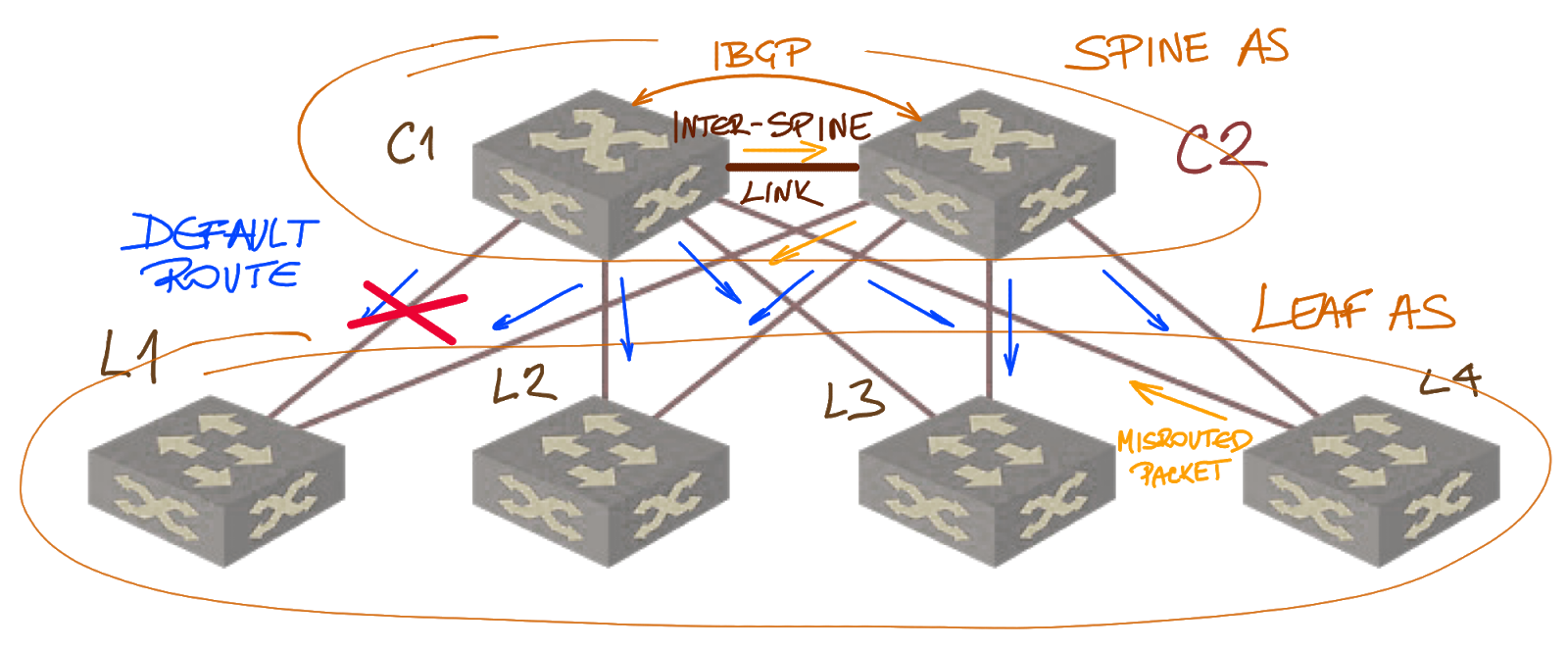
Adding inter-spine links
That link (as Oliver Herms pointed out in a LinkedIn discussion) also increases the fabric resiliency. Without it, two link failures (example: Spine1-to-Leaf1 and Spine2-to-Leaf2) could partition the fabric.
What about larger fabrics with more than two spines. The design quickly gets trickier:
Topology: Will you create a full mesh between spines, or a ring between them? What will you do when you go from two spines to four or eight spines? Also, you no longer need the inter-spine link for resiliency.
Routing: Spines have to exchange routes across inter-spine links. Will you use IBGP or will you go for some crazy schizophrenic idea of running EBGP between routers in the same autonomous system by faking AS numbers on both ends of the session? If you go for IBGP, will you add IGP to the mix, or will you tweak next hops on IBGP sessions? Will some spines become route reflectors or will you have a full-mesh of IBGP sessions?
Think again. Is the extra complexity really worth it? Or as Russ White would say “if you haven’t identified the tradeoffs, you haven’t looked hard enough”.
Is It Worth the Effort?
Control-plane traffic (BGP updates) is negligible compared to the usual leaf-to-spine bandwidth. Control-plane CPU in data center switches is usually not involved in packet forwarding, so the CPU has all the time in the world to process BGP updates. The number of prefixes advertised in a data center fabric is typically low.
So what exactly are we trying to optimize? The only reason I could see for summarization between spines and leaves is forwarding table size on leaves. Modern data center switches shouldn’t have that problem in most deployments – for more details on unified forwarding tables (UFT) and typical table sizes in data center switches see Data Center Fabric Architectures webinar, in particular the UFT Technology Overview video.
There might be an interesting edge case where you’d need lots of MAC and ARP entries on leaf switches, so you’d go for small IPv4 forwarding table… but even the host-focused UFT profile on Broadcom’s Trident-2 has 16.000 IPv4 prefixes (and 288.000 MAC/ARP entries). Apart from that, I’d stick with the simplest possible design without any form of route summarization.
https://tools.ietf.org/html/rfc7938#section-8.2
Pointing to your webinars (which I absolutely love and use extensively) on your blog would have been redundant ;-) but yes, of course!
Makes you wonder what they're doing the rest of their time :D... but on the other hand, they're a wonderful source of inspiration for future blog posts.