Scaling EVPN BGP Routing Designs
As discussed in a previous blog post, IETF designed EVPN to be next-generation BGP-based VPN technology providing scalable layer-2 and layer-3 VPN functionality. EVPN was initially designed to be used with MPLS data plane and was later extended to use numerous data plane encapsulations, VXLAN being the most common one.
Design Requirements
Like any other BGP-based solution, EVPN uses BGP to transport endpoint reachability information (customer MAC and IP addresses and prefixes, flooding trees, and multi-attached segments), and relies on an underlying routing protocol to provide BGP next-hop reachability information.
The most obvious approach would thus be to use BGP-based control plane with an underlying IGP (or even Fast Reroute) providing fast-converging paths to BGP next hops. You can use the same design with EVPN regardless of whether you use MPLS or VXLAN data plane:
- Use any IGP suitable for the size of your network. Some service providers have over a thousand routers in a single OSPF or IS-IS area. Even in highly-meshed environments (leaf-and-spine fabrics), OSPF or IS-IS easily scale to over a hundred switches.
- Use IBGP to transport EVPN BGP updates, and BGP route reflectors for scalability.
In data centers using EBGP as an IGP replacement, you could use the existing EBGP sessions to carry IPv4 (underlay) and EVPN (overlay) address families. For more information on this approach and some alternative designs read the BGP in EVPN-Based Data Center Fabrics part of Using BGP in Data Center Leaf-and-Spine Fabrics document.
Beyond a Single Autonomous System or Fabric
Like with MPLS/VPN, EVPN EBGP designs are a bit more convoluted than IBGP designs.
When using MPLS data plane, there’s almost no difference between MPLS/VPN and EVPN designs:
- Inter-AS Option B: change BGP next hop on AS boundary, and stitch EVPN MPLS labels at AS boundary. Like with MPLS/VPN, AS boundary routers would have to contain forwarding information for all VPNs (VLANs and VRFs) stretching across the AS boundary.
- Inter-AS Option C: retain the original BGP next hop, and stitch MPLS labels for BGP next hops at AS boundary. Network operators using BGP autonomous systems in the way they were designed to be used (collection of connected prefixes under control of a single administrative entity) rarely use Inter-AS Option C because it requires unlimited MPLS connectivity between PE-routers in different autonomous systems.
Situation is a bit different when using EVPN with VXLAN encapsulation. There’s no need for a hop-by-hop LSP between ingress and egress device – all they need is IP transport provided by the network core. It’s therefore best to leave BGP next hop (egress VXLAN Tunnel Endpoint – VTEP) unchanged unless you’re hitting the scalability limits of ASIC forwarding tables – an equivalent to Inter-AS Option C.
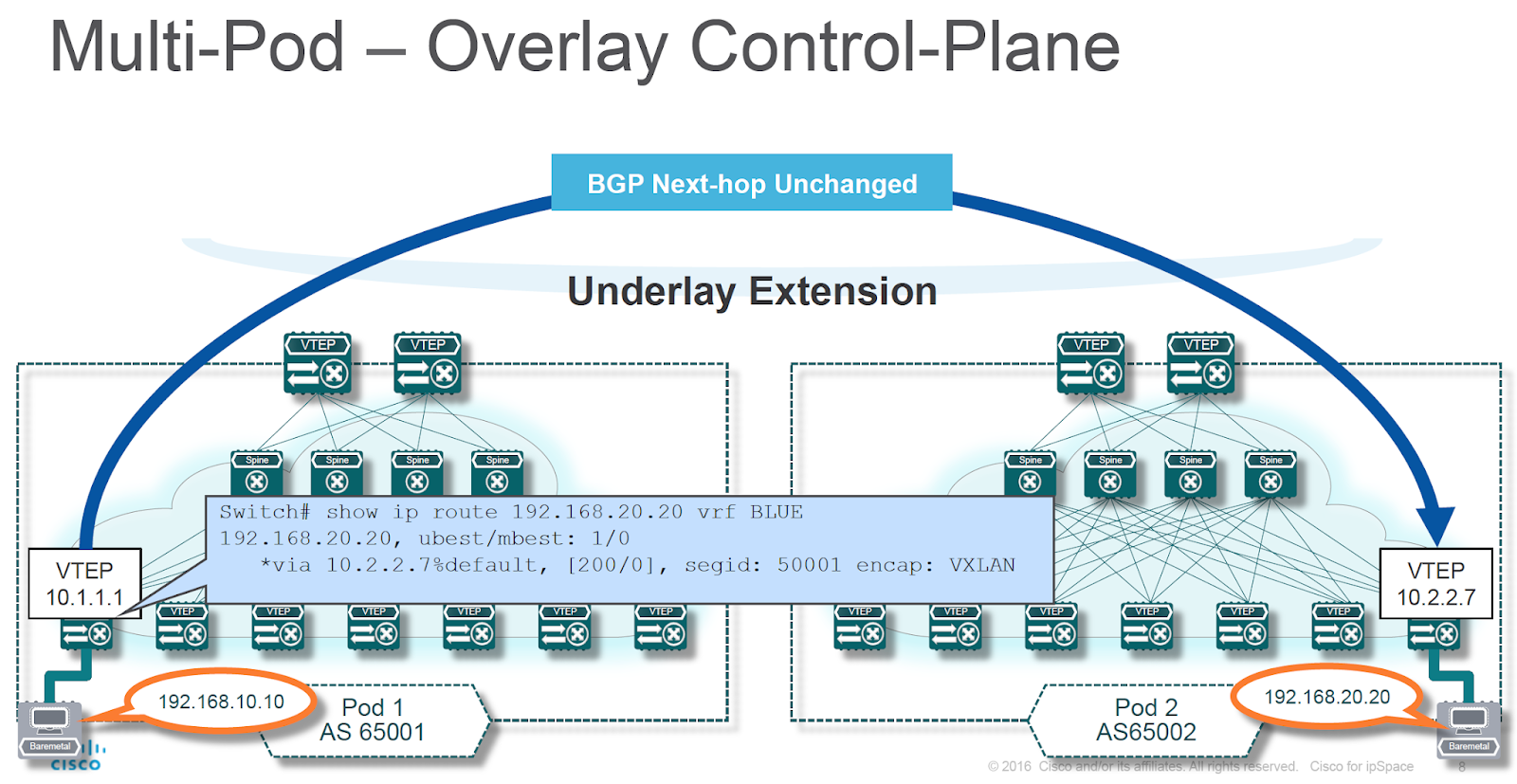
Multi-pod EBGP - next hop is unchanged (diagram by Lukas Krattiger)
A VXLAN equivalent to MPLS Inter-AS Option B is harder to implement. In this scenario, the AS boundary device changes BGP next hop, becoming an endpoint of VXLAN tunnels.
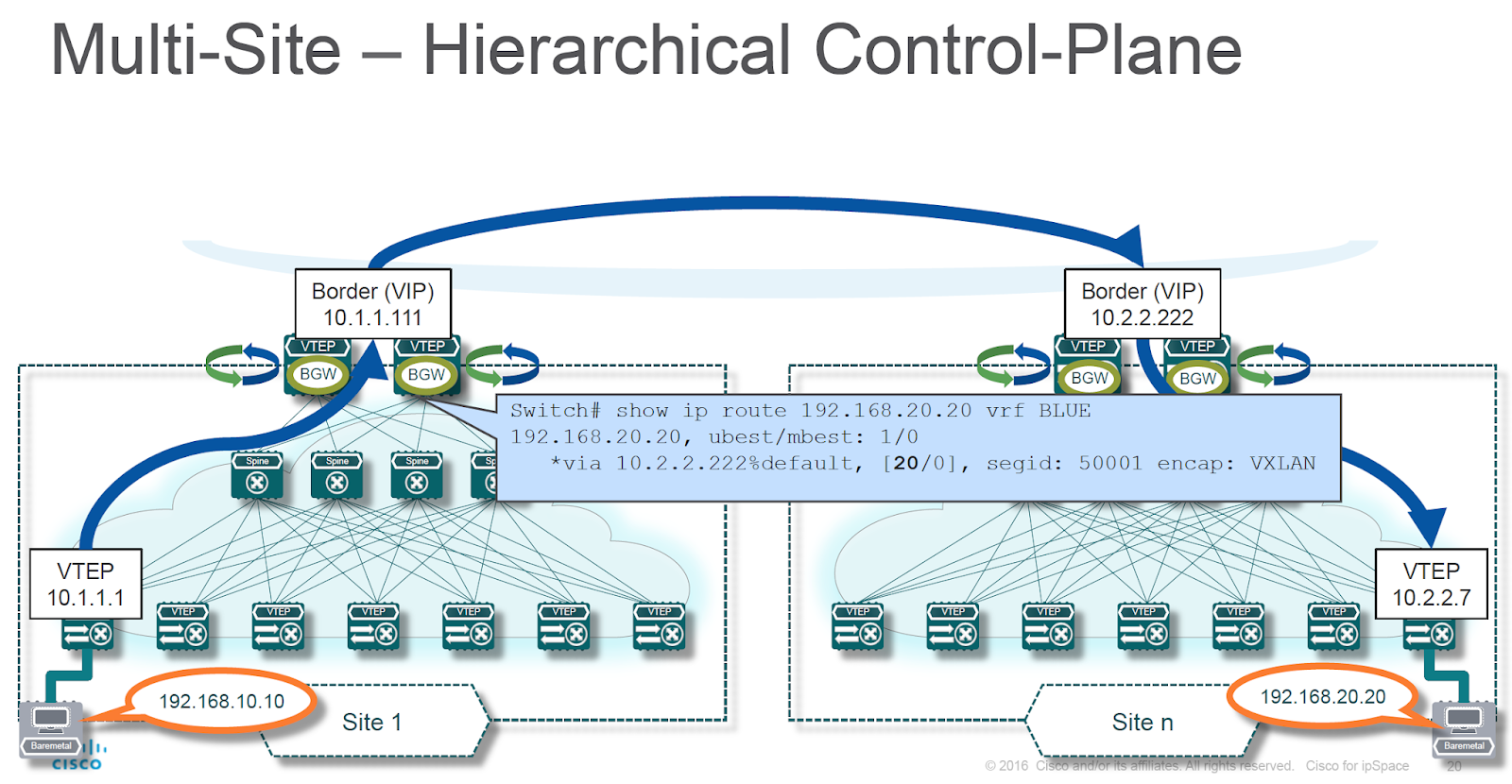
BGP next hop is changed on fabric boundary (diagram by Lukas Krattiger)
The border gateway (device changing BGP next hop on fabric boundary) has to be able to:
- Receive VXLAN-encapsulated packet;
- Perform forwarding based on MAC address toward the next-hop VTEP, including split-horizon flooding;
- Re-encapsulate the forwarded Ethernet frame into another VXLAN packet.
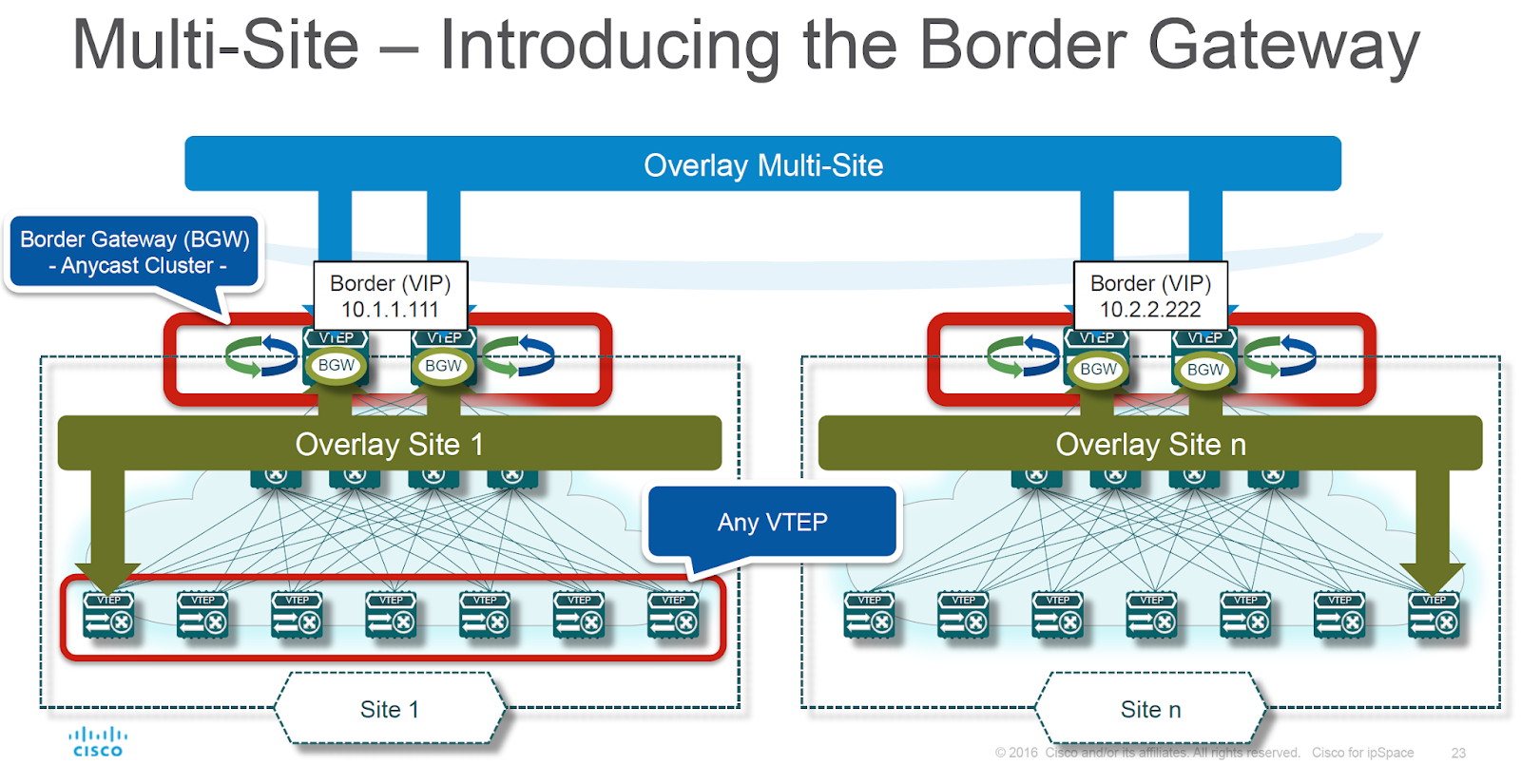
Border gateways perform VXLAN-to-VXLAN forwarding (diagram by Lukas Krattiger)
While recent merchant silicon ASICs implement RIOT (Routing In-and-Out of VXLAN Tunnels), very few of them can do bridging In-and-Out of VXLAN Tunnels – the mandatory prerequisite for Inter-AS Option B.
More EVPN information
- An overview of using BGP in data center fabrics including EVPN considerations.
- EVPN Deep Dive (focused on data center fabrics using VXLAN).
Revision History
- 2023-03-01
- Added a link to a blog post describing VXLAN-to-VXLAN bridging ASIC implementations.
Regardless, there must be something you confuse ... a) NX-OS with VXLAN EVPN is not automated by ACI and b) having a B-option doesn’t mean no multi-vendor support. Maybe worth to join 2019 and revalidate your ancient biases and FUD.
Let´s have 2 sites with EVPN/DCI configured:
- First datacenter on site A
- Second datacenter on site B
Both sites share the same subnet, e.g. 192.168.10.0/24 with the same distributed gateway on EVPN switch A and EVPN switch B
- We have one host A connected to the EVPN TOR switch A with IP 192.168.10.1
- We have one host B connected to the EVPN TOR switch B with IP 192.168.10.2
If you "show arp" on switch A, it will show ARP entry for A
If you "show arp" on switch B, it will show ARP entry for B
If you "show ip route" on switch A, it will show ip route /32 entry for B via BGP
If you "show ip route" on switch B, it will show ip route /32 entry for A via BGP
But,
if you "show ip route" on switch A, it will not show you any route for host A.
if you "show ip route" on switch B, it will not show you any route for host B.
Let´s imagine:
if you want to export that /32 host of host A to an external WAN router A which is connected to switch A dynamically, i.e. if host A is connected to EVPN switch A, its /32 host route is exported from EVPN switch A to external WAN router A and therefore the whole ingoing/outgoing traffic for that host is going through WAN router A
Vice versa if you want to export that /32 host of host B to an external WAN router B which is connected to switch B dynamically, i.e. if host B is connected to switch B, its /32 host route is exported from EVPN switch B to external WAN router B and therefore the whole ingoing/outgoing traffic for that host is going through WAN router B.
The problem is how to get the information out of the ARP table from each EVPN switch to make an /32 host route out of it?