On the Lossiness of TCP
When someone tells you that “TCP is a lossy protocol” during a job interview, don’t throw him out immediately – he was just trusting the Internet a bit too much (click to enlarge).
Everyone has a bad hair day, and it really doesn’t matter who published that text… but if you’re publishing technical information, at least try to do no harm.
Let’s do a step-by-step walk through that bit of wisdom:
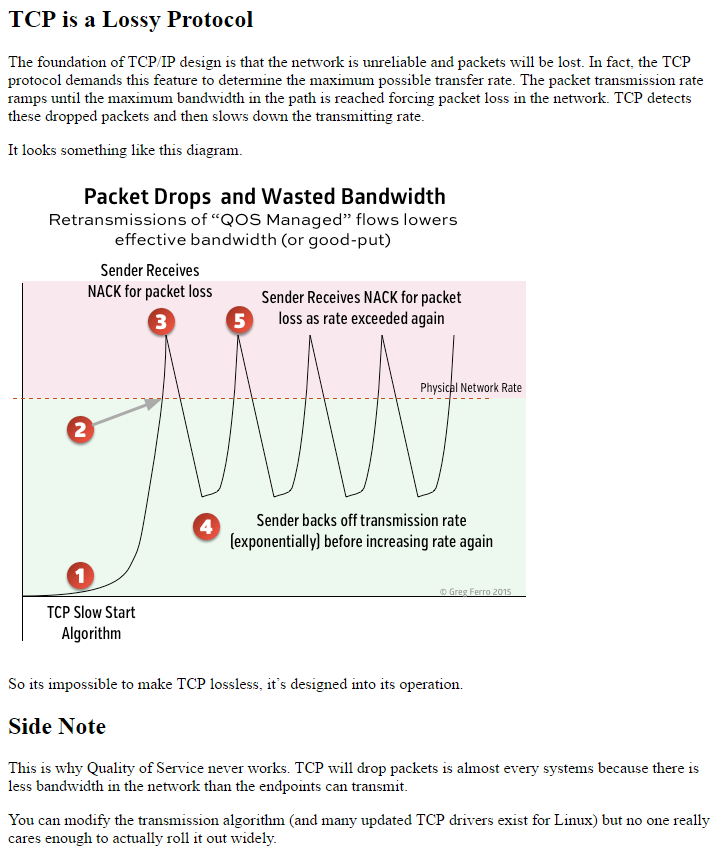
The foundation of TCP/IP design is that the network is unreliable and packets will be lost.
True.
In fact, the TCP protocol demands this feature to determine the maximum possible transfer rate.
Wrong. TCP reacts to packet drops and delays (increased round-trip-time; RTT). It turns out it’s better to delay packets than to drop them on low-speed links with a small number of TCP sessions, and it’s really easy to reproduce the measurement Jeremy Stretch did a long time ago.
We could go into a lengthy discussion on when it’s time to start dropping the packets instead of buffering them (see also Bufferbloat), and how TCP ECN could be used to alleviate congestion before the dropping starts, but that’s way beyond the point.
So it’s impossible to make TCP lossless, it’s designed into its operation.
You don’t have to trust me or Wikipedia, but you might trust the authors of RFC 793:
TCP provides for reliable inter-process communication between pairs of processes in host computers attached to distinct but interconnected computer communication networks.
I’d guess that reliable and lossy usually aren’t considered synonyms.
Back to the lossiness of TCP… seems it has some impact on QoS:
This is why Quality of Service never works. TCP will drop packets in almost every systems because there is less bandwidth in the network than the endpoints can transmit.
Another sound bite for a job interview, right? ;) It’s not totally wrong:
- Internet-wide QoS is a pipe dream. See also interview with Douglas Comer.
- Consistent QoS across more than one administrative domain is usually mission impossible.
- In many cases it’s easier to throw more bandwidth at the problem.
However, if:
- you can’t throw bandwidth at the problem,
- you can separate your traffic into few coarse classes, and
- you realize QoS is always a zero-sum game
… then you can use QoS mechanisms like policing, shaping, queuing or dropping to improve the service offered to some traffic at the cost of other traffic. Just keep in mind that you’re trading link cost for increased operational complexity (and associated costs).
Maybe his intention was to describe the fact that almost any normal TCP stream has certain amount of drops and retransmisions. We all have been on many troubleshooting calls, trying to explain this little fact to everybody...
P.s. The picture that describes the throughput is also weird, every oscilation should be smaller and smaller...
The title of the post seems like it would be right at home in the "National Inquirer", which is a gossip rag here in the US.
Well except for TOIP/VOIP it has been working for quite some time
@expert_reseau
Just because you can do Skype over the Internet doesn't mean that it's wrong.