Can You Afford to Reformat Your Data Center?
I love listening to the Datanauts podcast (Ethan and Chris are fantastic hosts), starting from the very first episode (hyper-converged infrastructure) in which Chris made a very valid comment along the lines of “with the hyper-converged infrastructure it’s possible to get so many things done without knowing too much about any individual thing…” and I immediately thought “… and what happens when it fails?”
It Looks Easier and Easier
The ever-simpler GUI and wizards that come with well-executed hyper-converged offerings allow typical data center administrator (one would expect a single person to work with compute, storage and network in a hyper-converged world) to set up and operate a reasonably-sized data center without knowing much about anything – like in every other IT discipline the knowledge-versus-complexity curve looks more and more like the hockey stick.
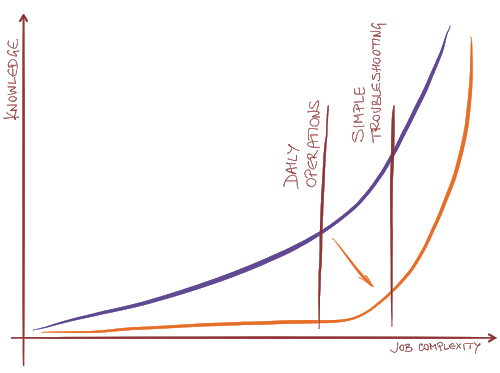
However, the simplistic façade hides ever-increasing pile of complexity, and because a typical administrator never had to build the skills necessary to master it (including the troubleshooting skills), he has absolutely no chance of fixing things when they break beyond the simple alarms displayed by the GUI, and often the VAR- or vendor support engineers fare no better.
It’s Not Just the Hyperconverged Infrastructure
Cisco ACI seems to offer similar experience – it’s extremely easy to operate (and hope it doesn’t break) once it’s set up. This is the feedback I got from one of the network architects testing the product:
Other than assigning a BGP ASN (which has no real world meaning in BGP peering), ACI really isn't networking. They made a point several times to explain that you still need networking experts who understand the underlying flows for troubleshooting and such - and I agree with that - but when I stop viewing this like a network architect and start viewing it like a CIO, I could have a staff of entry-level folks learn menus and dropdowns run the whole thing after it's set up. As long as the Security team approves what is in the Policies (Contracts) between the EPGs, the rest of it can be automated anyway.
It’s the Same All over the Place
Data centers are obviously not the only area facing this problem. We stopped fixing PCs, laptops, or tablets long ago. It’s easier to reformat them or replace them with a shinier model.
I’ve seen the same unfortunate trend in many other industries. A few years back my car’s engine developed crazy hiccups that were impossible to diagnose using the standard diagnostic tools, and an army of mechanics worked on the problem for weeks futilely trying to replace one component after another… until an old grunt decided to ignore the automated diagnostics, started looking at the schematics and the measurement points, and identified a leaky air pipe.
The whole process looked exactly like the TAC engineers telling you to reload the box or upgrade the software without even trying to identify the root cause of the problem.
Can You Afford It?
It’s easy to tell an unfortunate user he has to reformat the laptop (and hope the data restore process will work). You can afford to drive around in clunky replacement car for weeks while computer operators (formerly known as mechanics) try out random combinations of old and new components. Can you afford to go through the same experience with your data center?
Summary: Sooner or later you’ll have to deal with a product that will behave like a black box (regardless of whether it’s called EVO:*, hyperconverged infrastructure or SDN), and unless I’m missing something, you have only two options: either (A) reduce the black box size to acceptable unit of loss or (B) prepare for an all-out disaster with a good disaster recovery plan.
Did I Mention Disaster Recovery?
We discussed various aspects of disaster recovery and active-active data centers in the Designing Active-Active and Disaster Recovery Data Centers webinar.
could we do that with only two edge network L2 (Juniper ex series) switches and how the router will act if it connect to an external network with out needing to run STP?
Also, there are well-established ways to deal with urgent needs: you talk to your vendor SE, or to your system integrator/VAR, or you hire a consultant.
There is a complicating factor here: the whole point of hyperconverged is delivering a simplified customer experience, competing not against traditional server/storage/network but against giving up on in-house data centers and outsourcing data center infrastructure to the cloud.
The answer here isn't to put a simplistic user interface on the network we have today ("lipstick on a pig", as it were). It's also not to preserve the network silo, just as the storage business is learning that hyperconverged doesn't preserve SANs or the status quo in storage.
Oh, and the DevOps world (whatever you call it) seems to have rejected the idea of networking as a black box which is maintained as a separate technology silo by a separate organizational silo. What we see the Googles and Facebooks doing is at least as much about integrating network configuration and management into application configuration and management as it is about CapEx and vendor pricing. This "new world" is rejecting the status quo, in the data center.
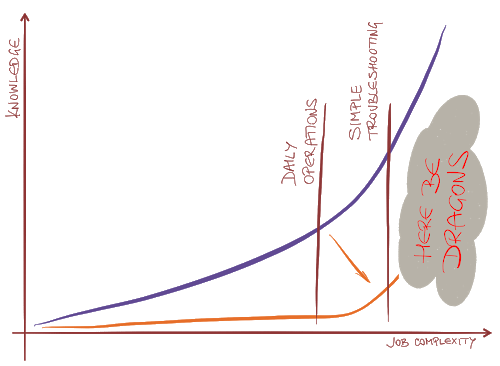
Looking at this customer and competitive situation, my gut instinct is that the data center needs to evolve into 1000-server-size islands of networking which are truly simple and can be installed and operated by application centric people, joined at the backbone (or for the vast majority of installations/businesses to the WAN or campus network) by more traditional networking.
Whether these islands look more like (my employer, for whom I'm not speaking here) Hewlett Packard Enterprise's Virtual Connect, or like Cisco's ACI, or something Intel cooks up around Omni-Path ... well, we'll all know by 2025. But I do agree, "here be dragons" if we try to do this with the full complexity of today's data center networking.
@FStevenChalmers