Blog Posts in February 2014
Service Insertion with OpenFlow
Another pretty-down-to-Earth OpenFlow use case: service insertion. “Slightly” easier than playing with VLANs or PBR (can you tell how tired I am based on the enormous length of this intro?).
CLI or API? Wait … Do You Really Have to Ask?
The “Is CLI In My Way … or a Symptom of a Bigger Problem” post generated some interesting discussions on Twitter, including this one:
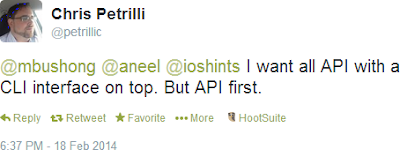
One would hope that we wouldn’t have to bring up this point in 2014 … but unfortunately some $vendors still don’t get it.
This Is Not the Host Route You’re Looking For
When describing Hyper-V Network Virtualization packet forwarding I briefly mentioned that the hypervisor switches create (an equivalent of) a host route for every VM they need to know about, prompting some readers to question the scalability of such an approach. As it turns out, layer-3 switches did the same thing under the hood for years.
VMware NSX Firewall Errata and Updates
Marcos Hernandez sent me a nice list of updates/errata after watching the NSX firewalls video from the VMware NSX Architecture webinar:
iSCSI or FCoE – Flogging the Obsolete Dead Horse?
One of my regular readers sent me a long list of FCoE-related questions:
I wanted to get your thoughts around another topic – iSCSI vs. FCoE? Are there merits and business cases to moving to FCoE? Does FCoE deliver better performance in the end? Does FCoE make things easier or more complex?
He also made a very relevant remark: “Vendors that can support FCoE promote this over iSCSI; those that don’t have an FCoE solution say they aren’t seeing any growth in this area to warrant developing a solution”.
What exactly is SDN (Video)?
The first question I tried to answer (and probably failed to) in the SDN 101 webinar was: What exactly is SDN? Is it an architecture with physically separate centralized control plane, or is it more? Does separate control plane make sense, or is it better to program distributed devices? Watch the video recorded during the live webinar session and tell me whether you agree with my answers.
Comparison of IPv6-over-IPv4 Tunneling Techniques
A while ago Sander Steffann and Iljitsch van Beijnum wrote a fantastic document that compared most (somewhat) widely used IPv6-over-IPv4 tunneling mechanisms. The document got published as RFC 7059 in November and is a definite must-read for anyone having to deal with this particular can of worms.
Unfortunately the document doesn’t cover the recent IPv4 sunset developments – numerous mechanisms that transport IPv4 leftovers over IPv6-only access networks (MAP-E, DS-Lite, lw4over6, 464XLAT …). One can only hope Sander and Iljitsch plan to produce a complementary document soon ;)
Interested in IPv4-to-IPv6 transition mechanisms?
Check out IPv6 Transition Mechanisms webinar and other IPv6 resources on ipSpace.net.
Going All Virtual with Virtual WAN Edge Routers
If you’re building a Greenfield private cloud, you SHOULD consider using virtual network services appliances (firewalls, load balancers, IPS/IDS systems), removing the need for additional hard-to-scale hardware devices. But can we go a step further? Can we replace all networking hardware with x86 servers and virtual appliances?
Published on , commented on July 10, 2022
Is CLI In My Way … or Is It Just a Symptom of a Bigger Problem?
My good friend Ethan recently published a blog post rightfully complaining how various vendor CLIs hamper our productivity. He’s absolutely correct from the productivity standpoint, and I agree with his conclusions (we need a layer of abstraction), but there’s more behind the scenes.
Flow-based Forwarding Doesn’t Work Well in Virtual Switches
I hope it’s obvious to everyone by now that flow-based forwarding doesn’t work well in existing hardware. Switches designed for large number of flow-like forwarding entries (NEC ProgrammableFlow switches, Enterasys data center switches and a few others) might be an exception, but even they can’t cope with the tremendous flow update rate required by reactive flow setup ideas.
One would expect virtual switches to fare better. Unfortunately that doesn’t seem to be the case.
OpenFlow-Based Network Tapping and Tap Aggregation Networks
Network tapping and tap aggregation are obviously the OpenFlow equivalent of the Hello World application – almost every OpenFlow controller vendor has a tap aggregation solution. Does that make sense? Sure – tap aggregation network is outside of the production data path and thus a great candidate for semi-production technology pilots.
For more details, watch the Tap Aggregation Networks video recorded during the Real Life OpenFlow-based SDN Use Cases webinar
Combine Physical and Virtual Appliances in a Private Cloud
I was running fantastic Network Security in a Private Cloud workshops in early 2010s and a lot of the discussions centered on the mission-impossible task of securing existing underdocumented applications, rigidity of networking team and their firewall rules and similar well-known topics.
The make all firewalls virtual and owned by the application team idea also encountered the expected resistance, but enabled us to start thinking in more generic terms.
Upcoming Presentations and Conferences
March will be a pretty busy month: I’ll be @ Troopers 14 and Interop Las Vegas. If you plan to be at one of these conferences, drop by one of my presentations:
- SDN, OpenFlow and NFV – hype and reality (1 day workshop);
- High Availability Strategies in IPv6 networks;
- SDN and Security – a Perfect Fit or Oil and Water;
- Designing the Virtual Networks for Software-Defined Data Centers (half-day workshop);
- Infrastructure for Private Clouds (half-day workshop);
- Following a Packet through the Virtual Data Center.
The list of past and upcoming presentations is also available on my web site.
Keep Your Failure Domains Small
A week after the disastrous sleet that kicked whole regions of Slovenia off power grid the servicemen of the local power distribution company (working literally days and nights) managed to restore electricity to the closest town … but it still might take days or even weeks before everyone gets it. One of the reasons: huge failure domains.
First-hop Load Balancing in IPv6
“I want default router address in DHCPv6 options” is a popular religious war on various IPv6 mailing lists. One of the underlying reasons is the need to implement poor man’s first hop load balancing (I won’t even consider the “I don’t want to think, so want IPv6 to behave like IPv4” mentality in this blog post), and as always, the arguments have more to do with suboptimal implementations than true technical needs.
Distributed In-Kernel Firewalls in VMware NSX
Traditional firewalls are well-known chokepoints in any virtualized environment. The firewalling functionality can be distributed across VM NICs, but some of those implementations still rely on VM-based packet processing resulting in a local (instead of a global) performance bottleneck.
VMware NSX solves that challenge with two mechanisms: OpenFlow-based stateful(ish) ACLs in VMware NSX for multiple hypervisors and distributed in-kernel stateful firewall in VMware NSX for vSphere. You’ll find more details in the NSX Firewalls video recorded during the VMware NSX Architecture webinar.
Disasters and Recoveries, Part 2
You wouldn’t believe what your second most pressing problem is when you lose electricity for a few days in the middle of a winter storm: freezer. Being a good engineer focused on redundant solutions, I bought a diesel generator before moving into the hills to keep the freezer at a reasonably low temperature in case of a long-term power loss.
I also thought about using the same generator to run our central heating. As always, I found a huge disconnect between theory and practice.
Why Can't We Have Plug-and-Play Networking?
Every time I plug a new device into my Windows laptop and it automatically discovers the device type, installs the driver, configures the devices, and tells me it’s ready for use, I wonder why we can’t have get the same level of automation in networking.
Consider, for example, a well-known vSphere link failover issue: if you forget to enable portfast on server-facing switch ports, some VMs lose connectivity for up to 30 seconds every time a switch reloads.
Disasters and Recoveries, Part 1
You probably know the three steps to a disaster recovery plan: Disaster. Recovery. Plan. It’s amazing how true that joke is, and how unprepared we tend to be for infrequent outages.
Things you say actually mean stuff
This is totally out of context, but imagine the consultants and marketers promising us unicorn-generated nirvana like follow-the-sun VM mobility or large-scale flow-based forwarding encountering Alice.
