OpenStack Quantum (Neutron) Plug-In: There Can Only Be One
OpenStack seems to have a great architecture: all device-specific code is abstracted into plugins that have a well-defined API, allowing numerous (more or less innovative) implementations under the same umbrella orchestration system.
Looks great in PowerPoint, but to an uninitiated outsider looking at the network (Quantum, now Neutron) plugin through the lenses of OpenStack Neutron documentation, it looks like it was designed by either a vendor or a server-focused engineer using NIC device driver concepts.
2013-10-03: Slightly changed the wording of the previous paragraph to explain my observation bias. For another perspective on Quantum beginnings, please read the comments.
You see, the major problem the Quantum plug-in architecture has is that there can only be one Quantum plugin in a given OpenStack deployment, and that plugin has to implement all the networking functionality: layer-2 subnets are mandatory, and there are extensions for layer-3 forwarding, security groups (firewalls) and load balancing.
2014-09-14: The situation is a bit better in OpenStack Icehouse release with ML2 Neutron plugins. More details in the second half of this blog post.
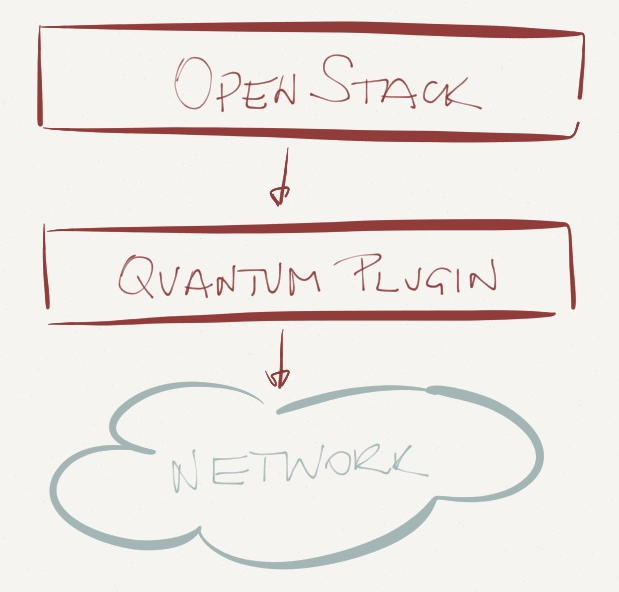
This approach worked well in early OpenStack days when the Quantum plugin configured virtual switches (similar to what VMware’s vCenter does) and ignored the physical world. You could choose to work with Linux bridge or Open vSwitch and use VLANs or GRE tunnels (OVS only).
However, once the networking vendors started tying their own awesomesauce into OpenStack, they had to replace the original Quantum plugin with their own. No problem there if the vendor controls end-to-end forwarding path like NEC does with its ProgrammableFlow controller, or if the vendor implements end-to-end virtual networks like VMware does with NSX or Midokura does with Midonet … but what most hardware vendors want to do is to control their physical switches, not the hypervisor virtual switches.
You can probably guess what happened next: there’s no problem that cannot be solved by another layer of indirection, in this case a layered approach where a networking vendor provides a top-level Quantum plugin that relies on sub-plugin (usually OVS) controlling the hypervisor soft switches.
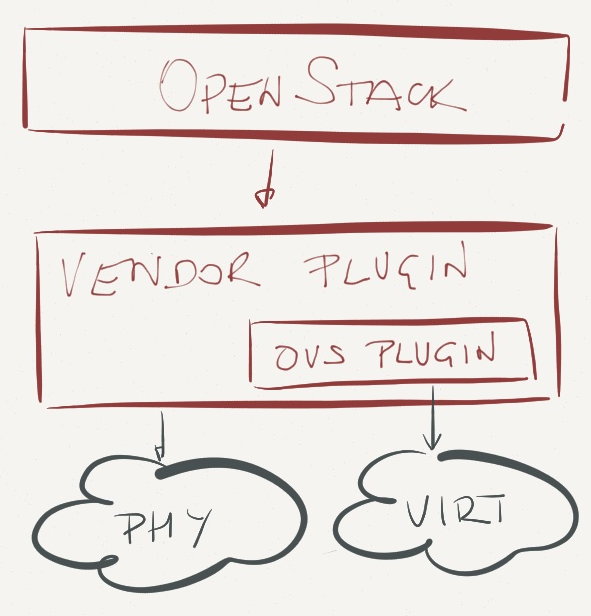
Remember that OpenStack supports a single plugin. Yeah, you got it right – if you want to use the above architecture, you’re usually locked into a single networking vendor. Perfect vendor lock-in within an open-source architecture. Brilliant. Also, do remember that your vendor has to update the plugin to reflect potential changes to Quantum/Neutron API.
2013-10-03: Florian Otel pointed out the Meta plugin. It might improve matters, but the documentation claims it's still experimental.
I never claimed it was a good idea to mix multiple switching vendors in the same data center (it’s not, regardless of what HP is telling you), but imagine you’d like to have switches from vendor A and load balancers from vendor B, all managed through a single plugin. Good luck with that.
Alas, wherever there’s a problem, there’s a solution – in this case a Quantum plugin that ties OpenStack to a network services orchestration platform (Tail-f NCS or Anuta nCloudX). These platforms can definitely configure multi-vendor network environments, but if you’re willing to go this far down the vendor lock-in path, you just might drop the whole OpenStack idea and use VMware or Hyper-V.

OpenStack Icehouse release gives you a different option: a generic plugin that implements the high-level functionality, works with virtual switches, and provides a hardware abstraction layer (Modular Layer 2 – ML2) where the vendors could plug in their own “device driver”.
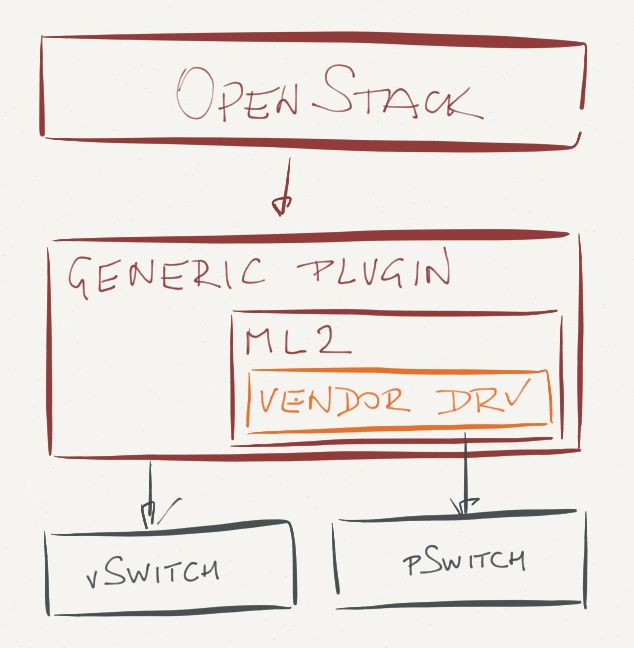
This approach removes the vendor lock-in of the monolithic vendor-supplied Quantum plugins, but limits you to the lowest common denominator – VLANs (or equivalent). Not necessarily something I’d want to have in my greenfield revolutionary forward-looking OpenStack-based data center, even though Arista’s engineers are quick to point out you can implement VXLAN gateway on ToR switches and use VLANs in the hypervisors and IP forwarding in the data center fabric. No thanks, I prefer Skype over a fancier PBX.
Finally, there’s an OpenDaylight Quantum plugin, giving you total vendor independence (assuming you love riding OpenFlow unicorns). It seems OpenDaylight already supports layer-3 OpenFlow-based forwarding, so this approach might be an interesting option a year from now when OpenDaylight gets some traction and bug fixes.
Cynical summary: Reinventing the wheel while ensuring a comfortable level of lock-in seems to be a popular pastime of the networking industry. Let’s see how this particular saga evolves … and do keep in mind that some people remain deeply skeptical of OpenStack’s future.
The original design discussions around Quantum/Neutron covered this topic extensively, and as someone how was there, pretty much all of your assumptions about intent are wrong.
The root of the problem is confusing a Quantum/Neutron "plugin" (a strategy for implementing the neutron API) with a "driver" (a piece of code that talks to a particular back-end technology). Your post makes this mistake by saying:
"Remember that OpenStack supports a single plugin. Yeah, you got it right – if you want to use the above architecture, you’re locked into a single networking vendor."
A single plugin does not mean you can only use a single technology. Plugins can support drivers, as your examples above point out. In fact, in my view, this post argues against itself, as by highlighting the value of different models like the ML2 and tail-f designs, it drives home the point that no single "driver model" is sufficient, hence you need pluggability at a higher layer (i.e., the plugin). This was the exact motivation for the original design. A user can choose a plugin (i.e., a strategy) that ties them to a particular vendor technology, or a strategy that gives them flexibility to use technologies from different vendors, often with a "lowest-common denominator" result. We explained this to people so much in the early days of quantum that we even had standard back-up slides for it (see slides 36-38: http://www.slideshare.net/danwent/openstack-quantum-intro-os-meetup-32612 ).
The notion of a "meta" plugin, that enables the use of different vendor-specific technologies at once was also discussed at the original design summit for OpenStack Quantum. It has been implemented and in the code base for a long time now. Again, all of this stuff is publicly available information: https://blueprints.launchpad.net/neutron/+spec/metaplugin
You should also correct your statement about services like load balancers being tied to the plugin, as from the start you were able to load LB plugins as "service plugins", which are independent of the "core plugin" that is loaded.
Thanks for the comment - reworded the intro paragraph a bit to explain my observation bias ;)
Although I agree with you in principle, the sad fact remains: at the moment you can't mix networking solutions from multiple vendors, and even though Tail-f can manage devices from multiple vendors, you're just replacing hardware lock-in with controller lock-in.
Need to investigate LB aspect further - would appreciate if you could point me to a reasonable starting point.
Kind regards,
Ivan
Would love to also see you explore what happens when Quantum services are combined with controller-based services. Where should various policies be configured? How will they interact if someone wants to deploy NFV services that run on VMs, which have to be provision via the "server" services (eg. Nova, vCenter, etc.)?
I do agree with Dan in most of his suggestions to your blog but I also find your point of view about multi-vendor and multi-plugin very interesting. I believe that we are targeting more than one domain in Neutron with only one plugin and therefore, it is very hard. By domain I mean PNI (Physical Networking Infrastruture) versus VNI (Virtual Networking Infrastructure). ML2 by means of drivers is putting together configuration for these two domain but I find it odd, exactly because looks messy and very difficult to debug for Cloud OpenStack Users. Services are like plugins, you can deploy many instances of the same service but only one kind of them, still some limitations but again some times those limitations are the result of providing all that functionality with opensource tools.