Nicira NVP Control Plane
In the previous posts I described how a typical overlay virtual networking data plane works and what technologies vendors use to implement the associated control plane that maps VM MAC addresses to transport IP addresses. Now let’s walk through the details of a particular implementation: Nicira Network Virtualization Platform (NVP), part of VMware NSX.
Components
Nicira NVP currently relies on Open vSwitch (OVS) to implement hypervisor soft switching. OVS could use dynamic MAC learning (and it does when used with OpenStack OVS Quantum plugin) or an external OpenFlow controller.
A typical OpenFlow-based Open vSwitch implementation has three components:
- Flow-based forwarding module loaded in Linux kernel;
- User-space OpenFlow agent that communicates with OpenFlow controller and provides the kernel module with flow forwarding information;
- User-space OVS database (ovsdb) daemon that keeps track of the local OVS configuration (bridges, interfaces, controllers …).
NVP uses a cluster of controllers (currently 3 or 5) to communicate with OVS switches (OVS switches can connect to one or more controllers with automatic failover). It uses two protocols to communicate with the switches: OpenFlow to download forwarding entries into the OVS and ovsdb-proto to configure bridges (datapaths) and interfaces in OVS.

Simple 2-host setup
Let’s start with a simple two host setup, with a single VM running on each host. The GRE tunnel between the hosts is used to encapsulate the layer-2 traffic between the VMs.
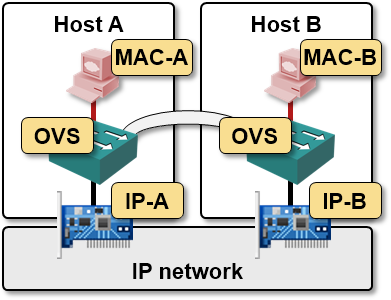
NVP OpenFlow controller has to download just a few OpenFlow entries into the two Open vSwitches to enable the communication between the two VMs (for the moment, we’re ignoring BUM flooding).

Adding a third VM and host
When the user starts a third VM in the same segment on host C, two things have to happen:
- NVP controller must tell the ovsdb-daemon on all three hosts to create new tunnel interfaces and connect them to the correct OVS datapath;
- NVP controller downloads new flow entries to OVS switches on all three hosts.
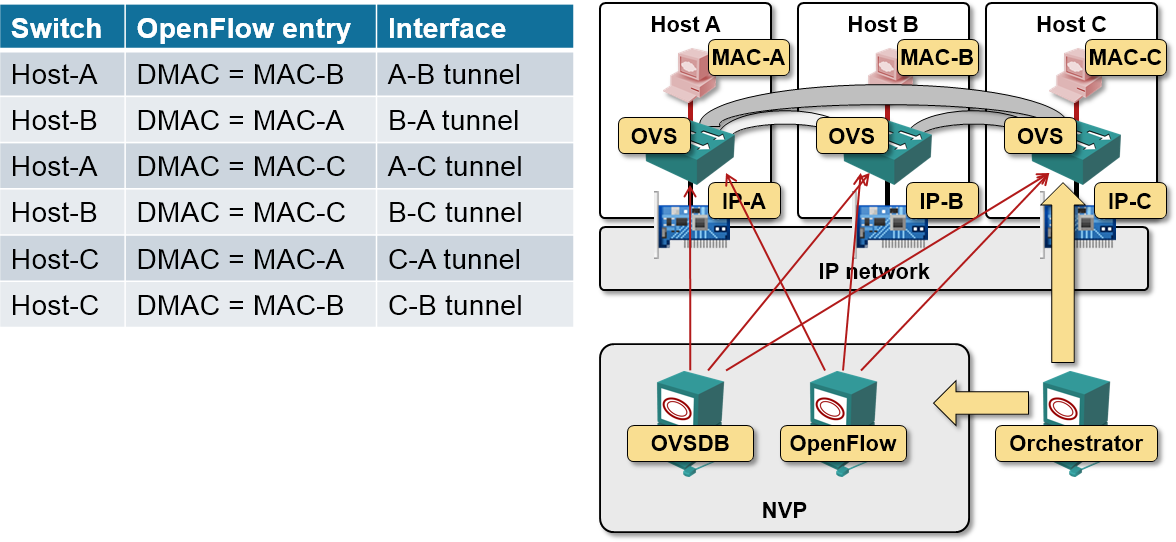
BUM flooding
And now let's stop handwaving the BUM flooding under the carpet. NVP supports two mechanisms to implement flooding within a virtual layer-2 segment:
Flooding through a service node – all hypervisors send the BUM traffic to a service node (an extra server that can serve numerous virtual segments) which replicates the traffic and sends it to all hosts within the same segment. We would need a few extra tunnels and a handful of OpenFlow entries to implement the service node-based flooding in our network:
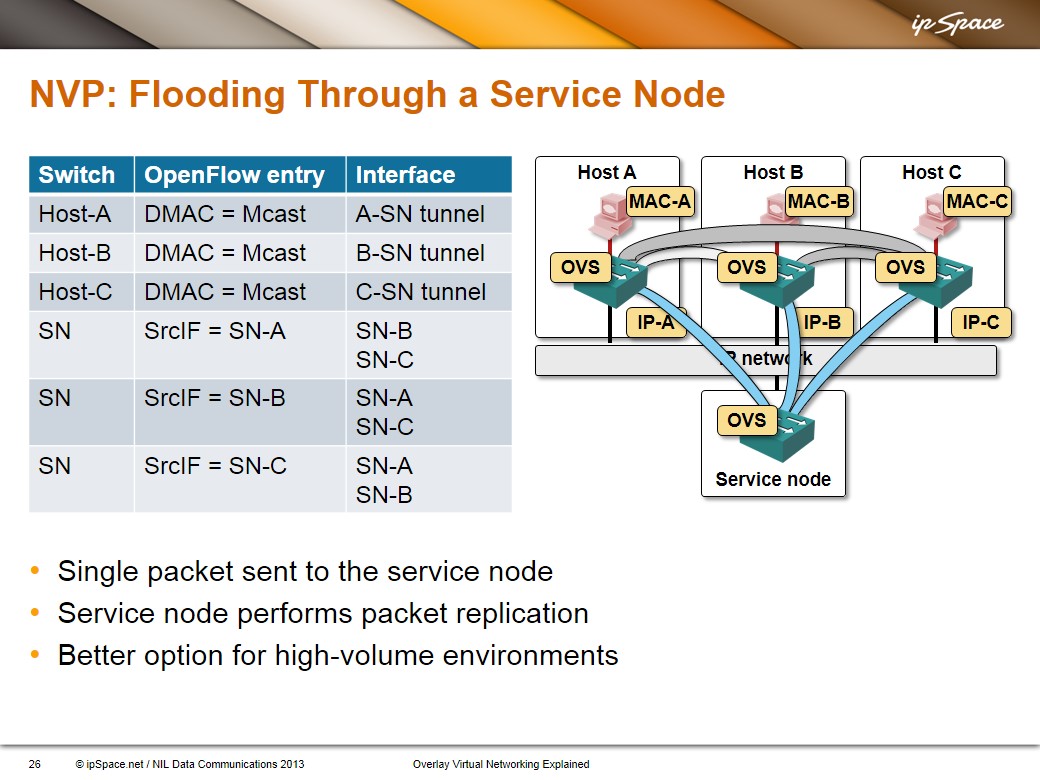
If the above description causes you heartburn caused by ATM LANE flashbacks, you’re not the only one ... but obviously the number of solutions to a certain networking problem isn’t infinite.
You can also tell the NVP controller to use source node replication – the source hypervisor sends unicast copies of an encapsulated BUM frame to all other hypervisors participating in the same virtual segment.
These are the flow entries that an NVP controller would configure in our network when using source node replication:
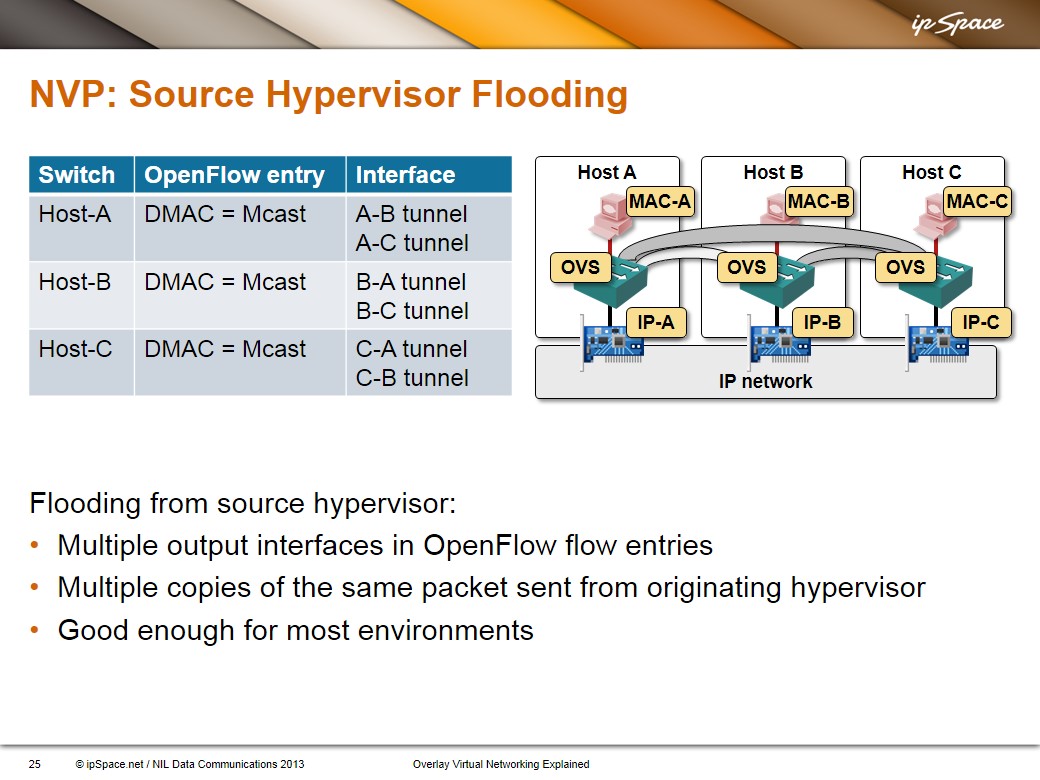
Do you think solutions like BGP/MPLS based Ethernet VPN are also better suited to Data Centre fabric environments?
Why do you think Cisco implemented unicast VXLAN?
Also - how does the OpenSwitch come to know about mac addresses it may like to reach that are not part of the mesh (e.g. devices not running NVP)?
Q#2: Unknown MAC addresses might happen only if you have a L2 gateway attached to the overlay subnet. In that case the L2 gateway node and the service node perform dynamic MAC learning and all other transport nodes (hypervisors) send packets to service node for unknown unicast flooding.