Dynamic Routing with Virtual Appliances
Meeting Brad Hedlund in person was definitely one of the highlights of my Interop 2013 week. We had an awesome conversation and quickly realized how closely aligned our views of VLANs, overlay networks and virtual appliances are.
Not surprisingly, Brad quickly improved my ideas with a radical proposal: running BGP between the virtual and the physical world.
Let’s revisit the application stack I used in the disaster recovery with virtual appliances post. One of the points connecting the virtual application stack with the physical world was the outside IP address of the firewall (or load balancer if you’re using bump-in-the-wire firewall).
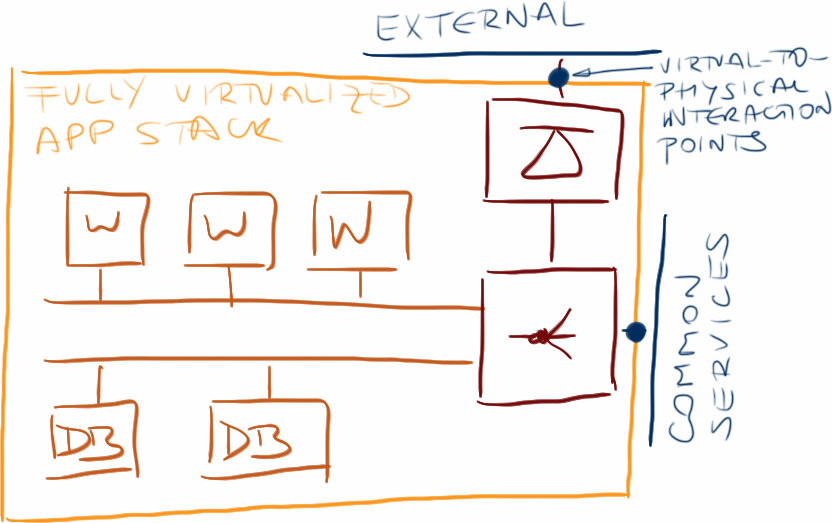
Virtual appliance interaction points
Now imagine inserting a router between the firewall and the outside world, allocating a prefix to the application stack (it could be a single /32 IPv4 prefix, a single /64 IPv6 prefix, or something larger), and advertising that prefix from the virtual router to the physical world via BGP.
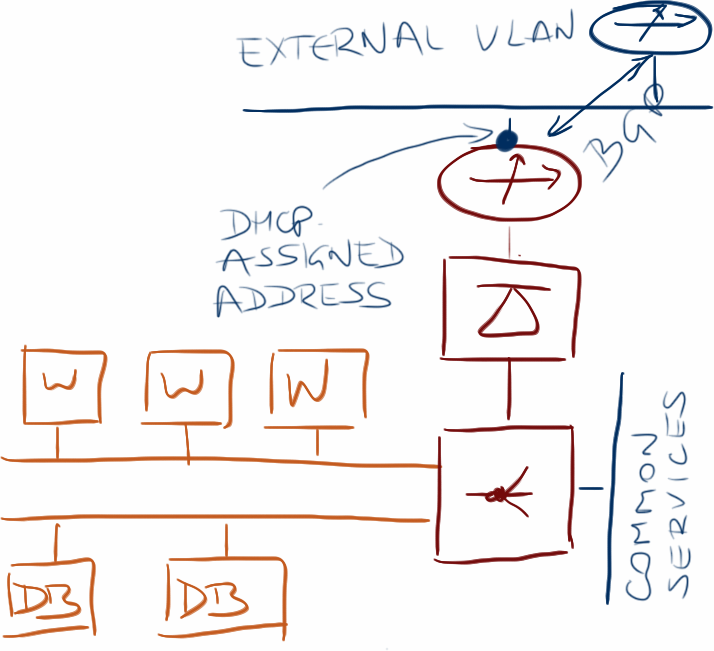
Virtual appliance running BGP with the adjacent switch
You could easily preconfigure the ToR switches (or core switches – depending on your data center design) with BGP peer templates, allowing them to accept BGP connections from a range of directly connected IP addresses, assign outside IP address to the virtual routers via DHCP (potentially running on the same ToR switch), and use MD5 authentication to provide some baseline security.
An even better solution would be a central BGP route server where you could do some serious authentication and route filtering. Also, you could anycast the same IP address in multiple data centers, making it easier for the edge virtual router to find its BGP neighbor even after the whole application stack has been migrated to a different location.
This twist on the original idea makes the virtual application stack totally portable between compatible infrastructures. It doesn’t matter what VLAN the target data center is using, it doesn’t matter what IP subnet is configured on that VLAN, when you move the application stack the client-facing router gets an outside address, establishes a BGP session with someone, and starts advertising the public-facing address range of the application.
More information
I described the basics of overlay networks in Cloud Computing Networking and Overlay Virtual Networking_ webinars.
For vendor-specific information, please watch VMware NSX Technical Deep Dive and Cisco ACI Deep Dive webinars.
Revision History
- 2023-02-01
- Removed a few obsolete mentions
- Added links to webinars created after the original publication date
- Added an NSX-T reference
http://www.nanog.org/meetings/nanog55/presentations/Monday/Lapukhov.pdf
http://channel9.msdn.com/Events/TechEd/NorthAmerica/2013/MDC-B351
it's less work todo and we can eliminate extra router and run
ospf right on the virtual firewall - not all vendors support bgp.
Unless extensive route filetring required (like corporate datacenter)
this should work.
Going to extreme (or simple) even RIPv2 with tweaked timers and distribution
lists will work fine - this virtual silo needs default route to the core
and core needs only route from the virtual firewall about the network
behind it. So block all RIPv2 updates on the core with distribution lists, allocate
/24 for the firewalled silo and core will receive 1 /24 block per silo. That's it.
All vendors support RIP, no much CPU power needed in this case.
The idea of running BGP to a vrouter/vswitch on the hypervisor has been what many in the decentralized control-plane camp have been pushing for quite some time and some vendors are actively building in one form or other. Proposals to BGP peer with the ToR dynamically on DHCP offer and other ways have been floated in NVO3 mailing list from early on.
The other BGP proposed in NVO3 is hypervisor-mode MP-BGP transporting VPNv4 and EVPN prefixes. I thought MPLS in the hypervisors (or something equivalent) was a good idea a long time ago, got persuaded in less than 5 minutes that it's not by people who actually run large-scale cloud data centers, and haven't changed my mind since.
I agree that using MPLS for the transport tunnel is not ideal for the DC. Implementations of EVPN and VPNv4 in the works for the DC will let the NVE advertise the set of encapsulations that it supports. This allows gradual migration from one encap to another as encaps themselves might evolve. This also makes it much more possible for seamless network virtualization across different NVO3 domains so long as both ends support the address family and have a supported encap in common.
I'm a proponent of MPLS over GRE where an NVE advertises via MP-BGP locally significant MPLS labels per context or even per NLRI. These labels can be used to identify local tenant context or apply whatever special action the egress NVE wishes to apply against an advertised label. With locally significant labels the context ID is not condemned forever to the one role of creating a flat virtual network. Locally significant context ID also enables very flexible topologies, and even takes the number of virtual networks from 24M to something that is a function of the size of BGP route targets and the number of NVE. If route target size increases, so does the number of virtual networks, without any change to the data plane. You could choose to fix use globally significant labels or even split the label space into local and globally significant.
What did the folk at the large-scale cloud DC tell you that convinced you? I'd like to believe as well, but haven't seen anything that works for everyone versus just for monolithic large cloud DC.
On a different note, if BGP is not ideal for service location and mobility in the service provider infrastructure, why would we want customers to use it for that purpose in tenant space?
If you have 10G/40GE WAN links, I am jealous...
This sounds very interesting, but could you expand on the bigger picture? I don't follow the comment about a /32. Was the intent to adv the virtual subnet (subnet behind fw) out to the ISP? How would this work with a /32?
If the application has a whole IPv4 /24 (or IPv6 /48) assigned to it, then you can advertise its new location to the Internet at large.
Finally, you can always use LISP and deploy xTR on the virtual appliance ;)
Could you take a look at what iLand is doing for disaster recovery? They work closely VMware and it seemed very promising to us. I would be interested in knowing where some of your models differ form theirs. Perhaps you could cover this is in your upcoming webinar. thank you
But what are the existing virtual PE? The cisco CSR1000, quagga, vayatta....Junos olive?
We need to make the networks SIMPLER, not more complex. That also means dropping some borderline use cases and focusing on 95% of the problems.
There are plenty of virtual appliances you can use today. Keep in mind the use case: separating an app stack from the outside world, which implies FW or LB functionality, so don't look at traditional router vendors.
I don't seem to get the nugget here. If i understand right, client facing IP address could either be /32 or dhcp generated on that DC. This address is advertized to the external world thro' a virtual router running BGP. This ip address is unique to an application stack, so there is one-one mapping between application stack and this ip-address. By having such a model, it is easy to move the application stack from One DC to another DC ?. If /32 is used, it is just a BGP update. If DHCP is used, it is going to be DNS update ?. Is this a fair summarization of this post ?.
BTW, why do i need an external VLAN as depicted in the picture but not explained in the post ?. Is it for overlay address space to be masked from underlay network (BGP session between Virtual router and BGP router ?)
-Bhargav