Simplify Your Disaster Recovery with Virtual Appliances
Regardless of what the vendors are telling you, it’s hard to get data center disaster recovery right (unless you’re running regular fire drills), and your job usually gets harder due to the intricate (sometimes undocumented) intertwining of physical and virtual worlds. For example, do you know how to get the firewall and load balancer configurations from the failed site implemented in the equipment currently used at disaster recovery site?
Imagine a simple application stack with a few web servers, app servers and two database servers. There’s a firewall in front of the web servers and a load balancer tying all the segments together.
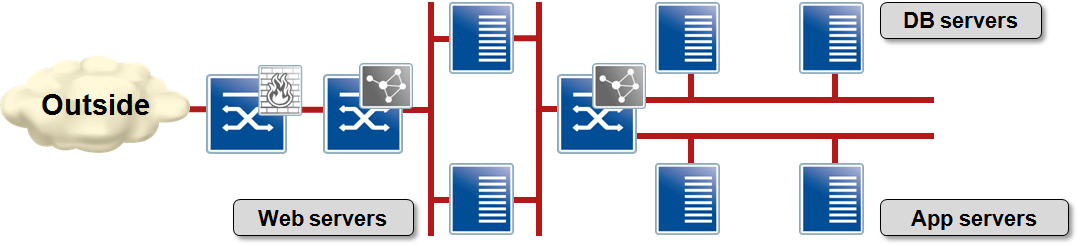
Sample application infrastructure
To implement this extremely simple application stack you need four or five (internal) VLANs, two load balancing contexts, and a firewall context. How many points do you have to touch when migrating the whole stack to a disaster recovery site? How many things can go wrong?
Now let’s try to virtualize the whole stack.
Step#1: Replace the physical appliances with virtual firewall and load balancer. Your life quickly becomes easier – the virtual appliances are usually small and tied to individual applications, and they usually store their configuration in a central repository (I do hope you have an up-to-date copy of that repository at the DR location) or on local disk, which is just a file on some shared file system (yet again, hopefully replicated to the DR site).
Moving a virtual appliance to a disaster recovery location is literally as easy as point-and-click, and getting it up and running after a data center failure is a total no-brainer… but there are still VLANs to configure.
Step#2: Throw overlay virtual networks into the mix. They don’t rely on physical infrastructure (as long as that infrastructure provides IP transport and in some cases IP multicast), so you can build a complex application stack with virtual machines and virtual appliances without ever touching the physical gear. Can you move that whole stack to a different location and recreate the environment there? Of course you can, the only thing you might have to do is to create the port groups referenced in VMDK files.
The only points of interaction between the whole application stack and the external world are the outside dependencies: client access (after all, clients still live in the physical world), and connectivity to central services (be they a central database, LDAP/AD or anything else).
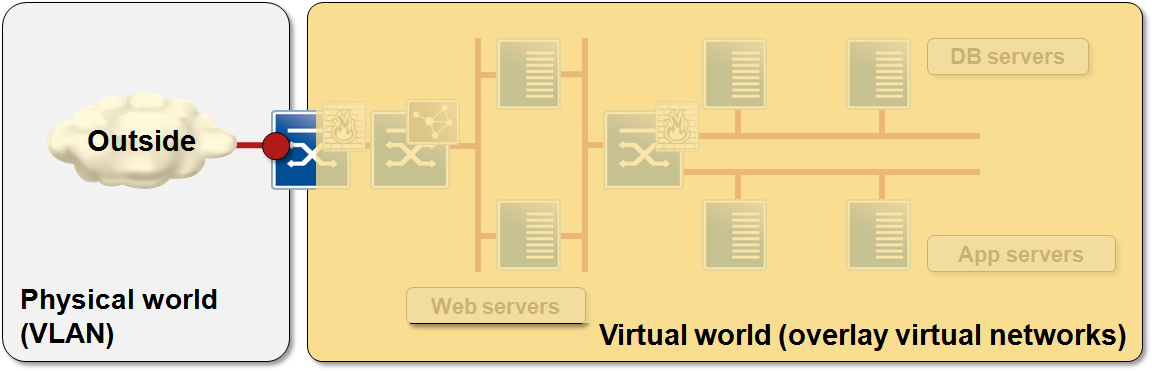
Splitting infrastructure into physical and virtual components
Client connectivity can be handled with dynamic addressing of the outside interface of the first load balancer/firewall in the application stack coupled with corresponding DNS changes; connectivity to common services is likewise easy to implement with a NAT box using DHCP on the outside (external-services-facing) interface.
Alternatively, you can use some interesting routing tricks that I’m describing in the Enterasys Robust Data Center Interconnect Solutions. Unfortunately not too many vendors found it expedient to offer something similar; it’s sexier to throw a bunch of new technologies (and bugs and interdependencies) into the mix.
Finally, remember that the overlay networks used to implement intra-stack connectivity stay totally isolated from the outside world. You can use whatever address range you wish within the application stack; as long as the outside-facing addresses remain reachable from the physical world your application works.
You really wouldn’t want to use overlapping address ranges, but that’s a whole different story.
End result: a packaged application stack that can be moved to another location with minimal (or no) interaction with the physical gear. I somehow suspect some hardware vendors don't like the idea ;)
More Information
I described the virtual appliance ideas in more detail in the Virtual Firewalls webinar.
That way all you need in case of a DR event is to swing the external connectivity.
In any other case, you'll pay hefty Murphy's tax.
Also, don't forget the usual three steps to disaster recovery planning: 1. Disaster, 2. Recovery, 3. Plan ;D
We have virtualized most of the solution (network and DB outstanding). As continue to virtualize, the support requirement and swing times continue to decline.
Donny