VXLAN, IP multicast, OpenFlow and control planes
A few days ago I had the privilege of being part of an VXLAN-related tweetfest with @bradhedlund, @scott_lowe, @cloudtoad, @JuanLage, @trumanboyes (and probably a few others) and decided to write a blog post explaining the problems VXLAN faces due to lack of control plane, how it uses IP multicast to solve that shortcoming, and how OpenFlow could be used in an alternate architecture to solve those same problems.
MAC-to-VTEP mapping problem in MAC-over-IP encapsulations
As long as the vSwitches remained simple layer-2 devices and pretended IP didn’t exist, their life was simple. A vSwitch would send VM-generated layer-2 (MAC) frames straight through one of the uplinks (potentially applying a VLAN tag somewhere along the way), hoping that the physical network is smart enough to sort out where the packet should go based on destination MAC address.
Some people started building networks that were larger than what’s reasonable for a single L2 broadcast domain, and after figuring out all the network-based kludges don’t work and/or scale too well, Cisco (Nexus 1000v) and Nicira (Open vSwitch) decided to bite the bullet and implement MAC-over-IP encapsulation in the vSwitch.
In both cases, the vSwitch takes L2 frames generated by VMs attached to it, wraps them in protocol-dependent envelopes (VXLAN-over-UDP or GRE), attaches an IP header in front of those envelopes ... and faces a crucial question: what should the destination IP address (Virtual Tunnel End Point – VTEP – in VXLAN terms) be. Like any other overlay technology, a MAC-over-IP vSwitch needs virtual-to-physical mapping table (in this particular case, VM-MAC-to-host-IP mapping table).
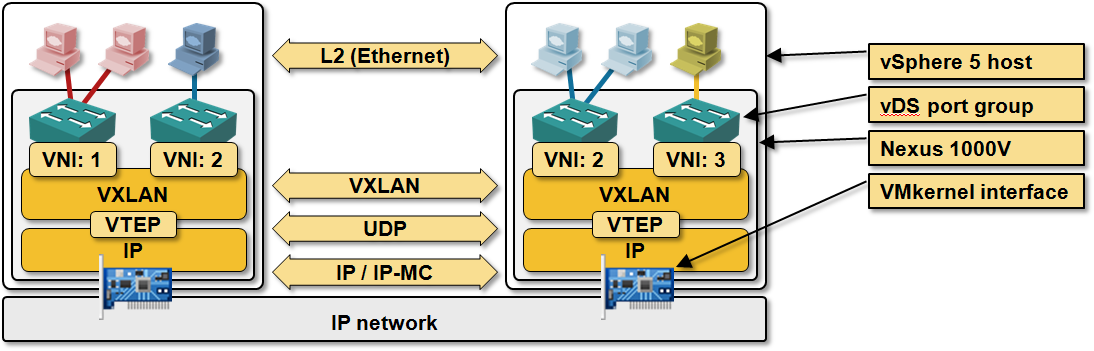
As always, there are two ways to approach such a problem:
- Solve the problem within your architecture, using whatever control-plane protocol comes handy (either reusing existing ones or inventing a new protocol);
- Try to make it someone else’s problem (most often, the network becomes the solution-of-last-resort).
Nicira’s Network Virtualization Platform (NVP) seems to be solving the problem using OpenFlow as the control-plane protocol; VXLAN offloads the problem to the network.
VXLAN: flooding over IP multicast
The current VXLAN draft is very explicit: VXLAN has no control plane. There is no out-of-band mechanism that a VXLAN host could use to discover other hosts participating in the same VXLAN segment, or MAC addresses of VMs attached to a VXLAN segment.
VXLAN is a very simple technology and uses existing layer-2 mechanisms (flooding and dynamic MAC learning) to discover remote MAC addresses and MAC-to-VTEP mappings, and IP multicast to reduce the scope of the L2-over-UDP flooding to those hosts that expressed explicit interest in the VXLAN frames.
Ideally, you’d map every VXLAN segment (or VNI – VXLAN Network Identifier) into a separate IP multicast address, limiting the L2 flooding to those hosts that have VMs participating in the same VXLAN segment. In a large-scale reality, you’ll probably have to map multiple VXLAN segments into a single IP multicast address due to low number of IP multicast entries supported by typical data center switches.
According to the VXLAN draft, the VNI-to-IPMC mapping remains a management plane decision.
VXLAN and IP multicast: short summary
- VXLAN depends on IP multicast to discover MAC-to-VTEP mappings and thus cannot work without an IP-multicast-enabled core;
- You cannot implement broadcast reduction features in VXLAN (ARP proxy); they would interfere with MAC-to-VTEP learning;
- VXLAN segment behaves exactly like a regular L2 segment (including unknown unicast flooding); you can use it to implement every stupidity ever developed (including Microsoft’s NLB in unicast mode);
- In case you do need multicast over a VXLAN segment (including IP multicast), you could use the physical IP multicast in the network core to provide optimal packet flooding.
The IP multicast tables in the core switches will probably explode if you decide to go from shared trees to source-based trees in a large-scale VXLAN deployment.
OpenFlow – an potential control plane for MAC-over-IP virtual networks
It’s perfectly possible to distribute the MAC-to-VTEP mappings with a control-plane protocol. You could use a new BGP address family (I’m not saying it would be fast), L2 extensions for IS-IS (I’m not saying it would scale), a custom-developed protocol, or an existing network- or server-programming solution like OpenFlow or XMPP.
Nicira seems to be going down the OpenFlow path. Open vSwitch uses P2P GRE tunnels between hypervisor hosts with GRE tunnel key used to indicate virtual segments (similar to NVGRE draft).
You can’t provision new interfaces with OpenFlow, so Open vSwitch depends on yet another daemon (OVSDB) to create on-demand GRE tunnels; after the tunnels are provisioned, OpenFlow can be used to install MAC-to-tunnel forwarding rules.
You could use OVS without OpenFlow – create P2P GRE tunnels, and use VLAN encapsulation and dynamic MAC learning over them for a truly nightmarish non-scalable solution.
Open vSwitch GRE tunnels with OpenFlow: short summary
- Tunnels between OVS hosts are provisioned with OVSDB;
- OVS cannot use IP multicast – flooded L2 packets are always replicated at the head-end host;
- If you want OVS to scale, you have to install MAC-to-VTEP mappings through a control-plane protocol. OpenFlow is a good fit as it’s already supported by OVS.
Once an OpenFlow controller enters the picture, you’re limited only by your imagination (and the amount of work you’re willing to invest):
- You could intercept all ARP packets and implement ARP proxy in the OpenFlow controller;
- After implementing ARP proxy you could stop all other flooding in the layer-2 segments for a truly scalable Amazon-like solution;
- You could intercept IGMP joins and install L2 multicast or IP multicast forwarding tables in OVS. The multicast forwarding would still be suboptimal due to P2P GRE tunnels – head-end host would do packet replication.
- You could go a step further and implement full L3 switching in OVS based on destination IP address matching rules.
More information
If you’re new to virtualized networking, consider my Introduction to Virtualized Networking webinar.
You’ll get more details on scalability issues, VXLAN, NVGRE and OpenFlow-based virtual networking solutions in my Cloud Computing Networking – Under the Hood webinar.
Curious to hear your opinion on OpenFlow controlling both the vSwitches and pSwitches. :)
Fantastic post!
http://networkheresy.wordpress.com/2011/11/17/is-openflowsdn-good-at-forwarding/