FCoE and LAG – industry-wide violation of FC-BB-5?
Anyone serious about high-availability connects servers to the network with more than one uplink, more so when using converged network adapters (CNA) with FCoE. Losing all server connectivity after a single link failure simply doesn’t make sense.
If at all possible, you should use dynamic link aggregation with LACP to bundle the parallel server-to-switch links into a single aggregated link (also called bonded interface in Linux). In theory, it should be simple to combine FCoE with LAG – after all, FCoE runs on top of lossless Ethernet MAC service. In practice, there’s a huge difference between theory and practice.
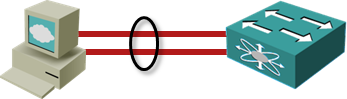
Assume the simplest possible scenario where two 10GE links connect a server to a single adjacent switch:
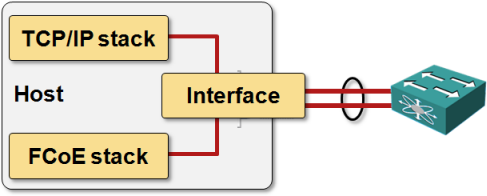
In theory, the aggregated link should appear as a single interface to the host operating system, and FCoE and IP stack should use the same interface:
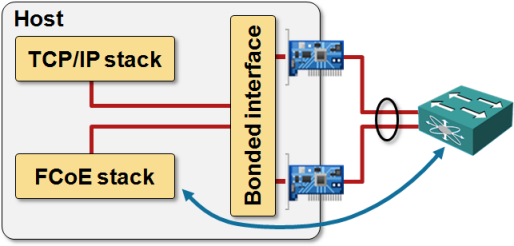
In reality, hardware network interface cards (NICs) rarely implement link aggregation (it also doesn’t make sense to connect both uplinks to the same hardware), and the aggregated link appears as a logical bonded interface (to confuse the unwary, the physical interface sometimes remain directly reachable). Still no problem, FCoE software stack could use the bonded interface.
Most CNAs implement FCoE stack in hardware and present two physical interfaces (Ethernet NIC and FC Host Bus Adapter – HBA) to the operating system. Two CNAs thus appear as four independent interfaces to the operating system, with the HBA part of CNA emulating FC host interface and running FCoE stack on the CNA. It’s obviously impossible to run FCoE over the aggregated link, because link aggregation happens way later, above the physical Ethernet device driver. The two CNAs thus need two FCoE sessions with the upstream switch.
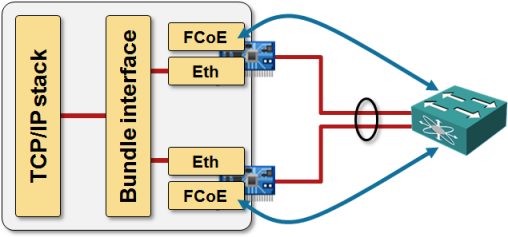
This behavior makes perfect sense, more so in multi-chassis LAG environment where CNAs establish FCoE sessions with different switches, thus maintaining SAN-A/SAN-B separation.

However, that’s not how FC-BB-5, the standard describing FCoE, is written.
FC-BB-5 nitpicking
FC-BB-5 is not very specific about the underlying layers, it mostly refers to MAC and Lossless Ethernet MAC (example: Figure 26 in Section 7.2). Link aggregation standard (802.1AX) is more specific – in the Overview part (section 5.1) it says:
Link Aggregation allows one or more links to be aggregated together to form a Link Aggregation Group, such that a MAC Client can treat the Link Aggregation Group as if it were a single link.
And later, in the Principles of Link Aggregation (5.2.1):
A MAC Client communicates with a set of ports through an Aggregator, which presents a standard IEEE 802.3 service interface to the MAC Client.
Clear enough? It is for me.
What is the industry doing
Every single FCoE switch vendor that I’m aware of (Cisco, Brocade, Juniper) is “interpreting” FC-BB-5 in exactly the same way. All switches thus behave in approximately the same way (as described above) and work with the host CNAs ... maintaining interoperability (a good thing) and setting up the stage to trip up an unsuspecting engineer who thinks reading standards can help to figure out how networking devices actually work.
One would understand the discrepancy between FC-BB-5 standard and a typical industry implementation if FC-BB-5 were written by a bunch of theoreticians, but it was (like other FC standards) designed by an industry body with representation from most of the vendors mentioned in the previous paragraph. Proves again what a huge gap there is between theory and practice.
More information
You’ll find more information about FCoE, DCB, and various FCoE deployment models in my Data Center 3.0 for Networking Engineers webinar.
If I understand what you're suggesting properly, multipathing would be handed over to the LACP bond. Wouldn't that require significant changes to the FC stacks? And in my experience, LACP bonds don't failover nearly as fast as FC drivers. That could very well have implications for the 'lossless' requirement of FCoE...
-Loren
Also, the current (non-standard) behavior forces the first switch to be FCF (or not to use LAG). Just imagine what would happen if the first switch is a regular DCB switch and you use LAG to connect to it.
I think there's a piece missing from your conversation (or *I* am missing something, which is entirely probable :) ). The FC-BB-5 standard does not specify anything about the underlying MAC address, whether it's bonded or not. This is by design.
When FCoE gets its address it does not simply use the MAC address of the host. Instead, FCoE uses its own addresses that can be mapped wherever you like. In this case, the only difference is that the interface MAC address is not the LAG MAC address.
Each VN_Port gets its own FPMA address, that is uniquely identified by a triplet:
MAC address of FCoE Device A (bonded or not); MAC address of device B (bonded or not); FCoE VLAN ID
This has nothing to do with the physical addresses of the LAG nor of the interface.
Or, am I missing something in your explanation?
J
information about etherchannel load balancing; amazingly, TMEs were not able to
explain (reveal) schema(s) to combine IP and FCoE across the same channel.
Do you have more details for channels between switches / Nexus:
"A port based load balancing" => L1&L2&L3&L4 hashing => asymmetric side utilization...??
FCoE traffic - at a high level - is just another VLAN. Each switch in a VPC (where you have a link going to the two switches) must allow the VLAN in order to be able to provide the appropriate connectivity for both SAN A and B.
So, suppose you have VLAN 101 for SAN A (on Switch A) and VLAN 102 for SAN B (on Switch B). Each FCF sees the MAC address behind the VLAN for the instantiation of the FCoE_LEP. FPMA provides the address based on the triplet I indicated before - in this case the MAC address is the bonded MAC address.
In this scenario, SAN A traffic does not get forwarded to Switch B because the VLAN 101 is not in Switch B's database; the inverse is true for SAN B traffic.
So, while my non-FCoE traffic (say, e.g., VLAN 1 and 100 for iSCSI traffic) gets hashed across both switches, the FCoE VLAN is forwarded and configured to a particular switch only, thus maintaining the separation.
Because of this, I don't see how the standard for FC-BB-5 is broken between the document and implementation (addressing is still based upon the presented MAC address), and LAG bonding is still maintained for the port.
Again, it's entirely possible that I'm missing your point here, so I apologize if it's right in front of me and I just can't see it.
LAG should be one logical link from Ethernet perspective, with one MAC address, and all the link parameters (including speed, VLAN list ...) should match between LAG members. In FCoE case, that's not true because of NIC/HBA separation in CNA.
I'm scratching my head here because I still don't understand the problem. LAG from server to switch has nothing to do with how the FC topology is viewed by the FC stack on the server. When the CNA is connected via LAG to the FCoE switch, the LAG is only visible to the Ethernet/IP topology, not the FC topology. What am I missing?
Cheers,
Brad
Do I make more sense now? If not, I'm giving up ;) If I can't explain myself in a way that you'd understand, I have no chance whatsoever to explain it to anyone else.
This was a bit of a confusing topic a few months ago. Even more so when you through VMware into the mix.
As @tbourke mentioned, and Ivan you have blogged about - http://goo.gl/Ky7iP - LAG isn't supported the vSwitch and distribution between two active uplinks is handled usually by the hypervisor. Configuration on both the VMware side and the switch side wasn't as simple as anyone expected.
It's when you make switch-to-switch FCoE LAG connections when the FC-BB-5 language about LAG is applicable.
Also - don't you think it's weird that we run one L3 protocol (FCoE) over physical interfaces and another one (IP) over port-channel interfaces? Does it sound right to be able to configure inconsistent parameters on port channel members?
As for "FC-BB-5 language is applicable to inter-switch links", I thought FC-BB-5 was _the_ standard defining all of FCoE ;))
Conversely, if the standard doesn't solve the problem you have, then you are free to determine your own solution.
This is just a generic message and in no way contradicts my earlier statements. :P
In addition, I'd also like to point out that due to the formatting of the "FC-BB-5 nitpicking" paragraph in your original post, a reader may incorrectly conclude that FC-BB-5 mentions "Link Aggregation" and it does not, FC-BB-5 (the standard that defines FCoE) only mentions "Ethernet MAC" and "Lossless Ethernet MAC". FC-BB-5 says no more on the topic because it would have been inappropriate for FC-BB-5 (a T11 working group) to say anything more about a topic (Ethernet MACs) that are defined by IEEE. With this in mind, one should conclude that the "MAC Client" referenced in section 5 of 802.1AX and an "FCoE ENode" are different ways of describing the same thing.
That having been said, I don't see any relevant text in 802.1AX that indicates all MAC Clients using the same MAC need to be aggregated in the same manner. Additionally, you specifically referenced the following text:
"A MAC Client communicates with a set of ports through an Aggregator, which presents a standard IEEE 802.3 service interface to the MAC Client."
I would like to point out that later on in this same section the following text is included:
"This standard does not impose any particular distribution algorithm on the Distributor. Whatever
algorithm is used should be appropriate for the MAC Client being supported."
Therefore, since distributing FCoE frames across multiple physical links would not be appropriate for the MAC Client (FCoE ENode), it is not done by the Distributor.
BTW, if you want to see an example of Teaming/Bonding and FCoE coexisting quite happily, take a look at the "FCoE Tech Book" and the "Nexus 7000, Nexus 5000, and MDS 9500 series topology" case study.
Thanks for your comment. This is the first comment that really addresses my concerns. I agree that one could read the 802.1AX standard in the way you interpret it.
You might still face an interesting problem if the first-hop switch is a DCB-capable switch w/o FC stack (and potentially even without FIP snooping), distributing FCoE frames across LAG at will ... but hopefully we'll eventually come to a point where everyone agrees that doesn't make too much sense.
Ivan
Ultimately, your bonded interface only brings up half the issue. We need to tie the process to the SCSI process at the OS level. SCSI requires *one* single path.
Multiple paths for SCSI operation have been a thorn in the side for ages. I'm told that it has to do with nanosecond (or tighter) timing, so that there has to be some referee to ensure that bits are to/from the SCSI stack in guaranteed order or risk corruption.
Array vendors have developed multipathing software to sit in-between the HBAs and the OS. If the OS/SCSI can't deal with 2 paths natively, how would FC-BB-5 solve this without some form of middleware?
Erik, of course, sitting on the T11 committee has a much greater understanding of the text than I do (I'm just a on-again, off-again observer in the meetings). But FWIW Claudio DeSanti mentioned last night that:
"A standard is violated when an *explicit* requirement (i.e., a "shall" statement) is not observed. To state that a standard is violated he has to point out a specific "shall" statement that is not observed. Everything else is not a violation of a standard."
I know it's semantics and nitpicks, but then again, that's precisely what standards *are* - semantics and nitpicks. 8-)